Avian
Visitar Site Oficial



Avian Visão Geral
Avian é uma plataforma de infraestrutura de IA de última geração, projetada para fornecer a inferência de IA mais rápida e confiável do mercado. Atende a desenvolvedores, engenheiros de IA e empresas que exigem alto rendimento e baixa latência para suas aplicações de IA. Ao alavancar o hardware mais recente, como GPUs NVIDIA B200 e H200, e técnicas avançadas de otimização como a decodificação especulativa, a Avian atinge velocidades líderes do setor, estabelecendo novos benchmarks para modelos como o DeepSeek R1 a 351 tokens por segundo.
A plataforma oferece dois serviços principais para acomodar diversas necessidades: uma API Serverless flexível e Implantações Dedicadas poderosas. Essa abordagem dupla permite que os usuários integrem rapidamente modelos de ponta em suas aplicações com uma simples chamada de API ou obtenham controle total sobre sua infraestrutura para executar modelos personalizados e ajustados para tarefas especializadas. A Avian é construída para escalar, operando sem limites de taxa para suportar aplicações à medida que crescem do protótipo à produção total.
Como usar Avian
Começar a usar o Avian é simples e projetado para a eficiência do desenvolvedor. Existem dois métodos principais para aproveitar seu poder:
- Usando a API Serverless da Avian: Esta é a maneira mais rápida de acessar modelos de alto desempenho. Os desenvolvedores podem simplesmente se inscrever, obter uma chave de API e fazer solicitações para vários endpoints de modelo (por exemplo, a série Meta Llama 3.1). O processo envolve uma implementação de código simples, semelhante a outras APIs de IA, permitindo uma integração perfeita em aplicações existentes sem gerenciar nenhuma infraestrutura.
- Configurando Implantações Dedicadas: Para usuários que precisam executar modelos personalizados do HuggingFace ou requerem recursos dedicados para alto rendimento consistente, a Avian oferece instâncias de GPU dedicadas. Os usuários podem selecionar o tipo de GPU desejado (por exemplo, NVIDIA H200 SXM), configurar a duração da implantação e implantar seu modelo na infraestrutura otimizada da Avian. Isso é ideal para cargas de trabalho de produção que exigem desempenho e alocação de recursos garantidos.
Recursos principais do Avian
- Velocidade de Inferência Recorde: Atinge velocidades de até 351 tokens por segundo, superando significativamente as médias da indústria e permitindo aplicações de IA em tempo real.
- API Serverless: Fornece acesso pago conforme o uso a uma variedade de modelos de alto desempenho como Meta Llama 3.1 e DeepSeek R1, sem limites de taxa.
- Implantações de GPU Dedicadas: Oferece instâncias dedicadas com as mais recentes GPUs NVIDIA (B200, H200, H100) para implantar qualquer modelo do HuggingFace, garantindo máximo desempenho e controle.
- Segurança de Nível Empresarial: Apresenta medidas de segurança robustas, incluindo conformidade com SOC2 Tipo 2 (em andamento), adesão ao GDPR, criptografia TLS 1.2+ e Autenticação Multifator (MFA). Os dados não são armazenados permanentemente, garantindo a privacidade do usuário.
- Escalável e Pronto para Produção: Construído para lidar com cargas de trabalho de produção de alto volume sem degradação de desempenho, apoiando as empresas à medida que escalam.
- Conectores de Dados: Oferece um conjunto de conectores para plataformas como Looker Studio e Google Sheets, permitindo a integração perfeita de dados de fontes como Google Analytics, Facebook Ads e muito mais.
Casos de uso para Avian
A infraestrutura de alta velocidade da Avian é adequada para uma ampla gama de aplicações de IA exigentes:
- Chatbots e Assistentes de IA em Tempo Real: Potencializando IA conversacional que pode responder instantaneamente, proporcionando uma experiência de usuário natural e fluida.
- Geração de Conteúdo em Larga Escala: Permitindo que plataformas gerem artigos, textos de marketing e código em uma escala e velocidade sem precedentes.
- Análise e Resumo de Dados Complexos: Processando e analisando grandes volumes de dados de texto em tempo real para análise financeira, pesquisa e inteligência de negócios.
- Implantação de Modelos Proprietários: Empresas com modelos treinados ou ajustados personalizados podem implantá-los na infraestrutura dedicada da Avian para obter desempenho ideal em ambientes de produção.
Vantagens do Avian
A Avian se destaca no competitivo mercado de infraestrutura de IA com várias vantagens importantes:
- Desempenho Inigualável: Oferece velocidades de inferência de 3 a 10 vezes mais rápidas em comparação com outros grandes provedores de nuvem e serviços de inferência.
- Flexibilidade: Suporta tanto modelos padrão por meio de uma API simples quanto modelos personalizados em hardware dedicado, atendendo a todos os níveis de desenvolvimento de IA.
- Custo-Benefício: Oferece preços competitivos tanto para sua API quanto para instâncias dedicadas, proporcionando um desempenho superior por dólar.
- Confiabilidade e Escalabilidade: A ausência de limites de taxa e o uso de infraestrutura de nível de produção garantem que as aplicações possam escalar sem problemas, sem atingir gargalos de desempenho.
- Postura de Segurança Sólida: Um compromisso claro com a segurança e privacidade dos dados constrói confiança para clientes empresariais que lidam com informações sensíveis.
Preços e planos
A Avian oferece uma estrutura de preços transparente e flexível, adaptada a diferentes padrões de uso:
- API Avian (Pague-pelo-uso): Os usuários são cobrados por milhão de tokens para entrada e saída. Os preços são competitivos e variam por modelo. Por exemplo:
- Meta Llama 3.1 8B Instruct: $0.10 por milhão de tokens de entrada/saída.
- Meta Llama 3.1 70B Instruct: $0.45 por milhão de tokens de entrada/saída.
- Meta Llama 3.1 405B Instruct: $1.50 por milhão de tokens de entrada/saída.
- Implantações Dedicadas: Cobrado por segundo para instâncias de GPU reservadas. Isso é ideal para cargas de trabalho de alto rendimento. Taxas de exemplo para instâncias reservadas:
- NVIDIA H100 SXM (80GB HBM3): A partir de $0.00139/segundo.
- NVIDIA H200 SXM (141GB HBM3): A partir de $0.00208/segundo.
- Pré-encomendas de Novo Hardware: A Avian também oferece pré-encomendas de hardware de ponta como o NVIDIA B200, permitindo que os clientes garantam acesso à tecnologia mais recente. Por exemplo, uma implantação de 7 dias de um DeepSeek R1 em uma configuração de 8x NVIDIA B200 tem o preço de $14,000.
Avian Comentários (0)
Faça login para comentar
Entrar agoraAvianAnálise de Tráfego do Site
Dados de Tráfego Mais Recentes
Status
Tendência Mensal de Tráfego
Localização Geográfica
Top 5 Países/Regiões
-
🇺🇸 United States34,45%
-
🇻🇳 Vietnam30,53%
-
🇬🇧 United Kingdom20,68%
-
🇮🇳 India14,34%
Palavras-chave Populares
| Palavra-chave | Custo por Clique (CPC) |
|---|---|
|
$0,23
|
|
|
$0,00
|
|
|
$0,96
|
|
|
$0,00
|
|
|
$0,00
|
Avian Alternativas
Ver Tudo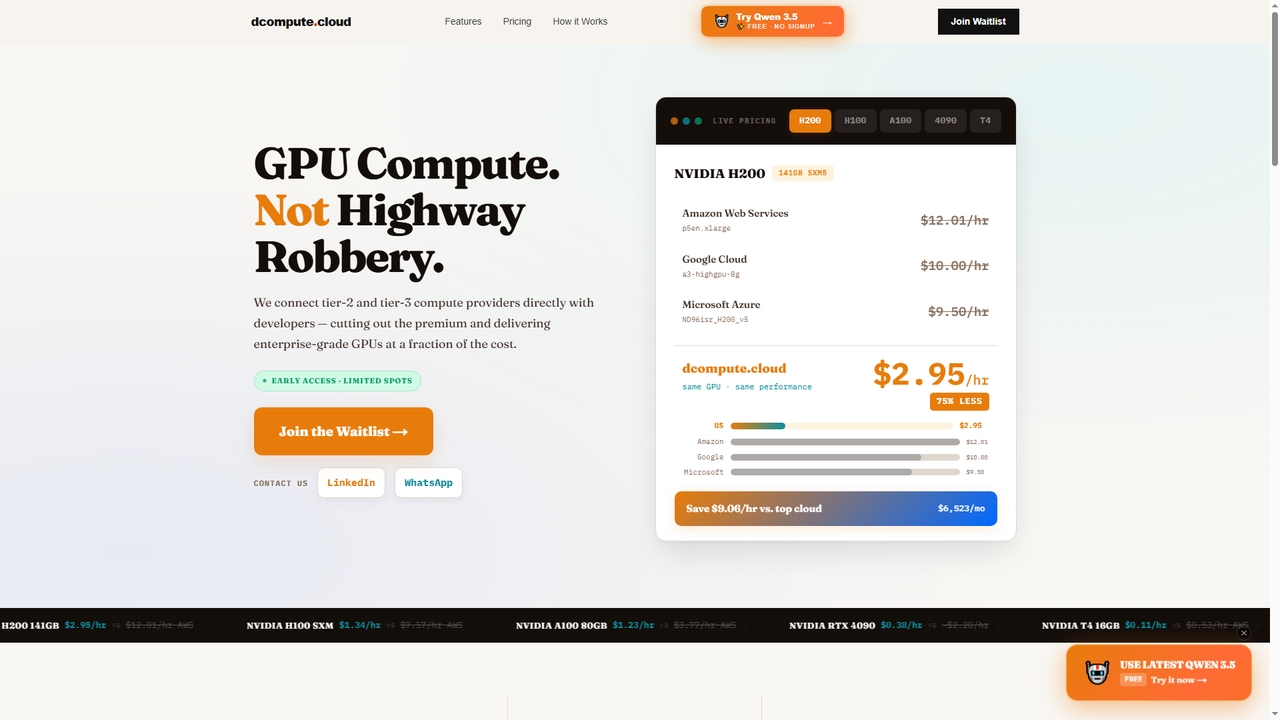
Dcompute
Dcompute é um mercado de computação GPU descentralizado que conecta desenvolvedores diretamente a provedores de datacenter de nível …
Dcompute é um mercado de computação GPU descentralizado que conecta desenvolvedores diretamente a provedores de datacenter de nível 2 e 3. Oferece GPUs NVIDIA de nível empresarial (H200, H100, A100, RTX 4090, T4) por uma fração do custo dos principais provedores de nuvem, prometendo economia de até 90%. A plataforma possui implantação instantânea, API/painel unificado, orquestração completa e cobrança puramente por uso por segundo, sem mínimos.
Zetic.ai
Zetic.ai é uma plataforma que permite aos desenvolvedores implantar modelos de IA diretamente em dispositivos de borda, eliminando …
Zetic.ai é uma plataforma que permite aos desenvolvedores implantar modelos de IA diretamente em dispositivos de borda, eliminando a necessidade de servidores GPU caros. Seu pipeline automatizado, ZETIC.MLange, otimiza e converte modelos para execução no dispositivo, alcançando um desempenho até 60x mais rápido com aceleração NPU, garantindo a privacidade dos dados e reduzindo a latência.
Symphony
Symphony é uma interface LLM universal que oferece uma API compatível com OpenAI para implantar, gerenciar e escalar …
Symphony é uma interface LLM universal que oferece uma API compatível com OpenAI para implantar, gerenciar e escalar aplicativos de IA. Com confiabilidade de nível empresarial, custos até 20% menores e suporte a mais de 100 modelos de IA importantes como GPT-5 e Llama 4, é a solução ideal para desenvolvedores e empresas que buscam uma infraestrutura de IA eficiente e robusta.
SiliconFlow
SiliconFlow é uma plataforma de infraestrutura de IA unificada, projetada para inferência de alto desempenho de Modelos de …
SiliconFlow é uma plataforma de infraestrutura de IA unificada, projetada para inferência de alto desempenho de Modelos de Linguagem Grandes (LLMs) e modelos multimodais. Ela oferece a desenvolvedores e empresas opções de implantação escaláveis, econômicas e flexíveis, incluindo APIs sem servidor, GPUs reservadas e capacidades de ajuste fino, tudo acessível através de uma única API compatível com OpenAI.

Baseten
Baseten é uma plataforma de inferência de nível de produção para implantar, escalar e gerenciar modelos de IA. …
Baseten é uma plataforma de inferência de nível de produção para implantar, escalar e gerenciar modelos de IA. Oferece runtimes de alto desempenho, fluxos de trabalho de desenvolvedor contínuos e opções de implantação flexíveis (nuvem, auto-hospedado, híbrido). Ideal para equipes de engenharia e ML que constroem aplicações de IA de missão crítica.
Nexlayer
Nexlayer é a primeira plataforma de nuvem nativa de agentes, projetada para capacitar agentes de codificação de IA …
Nexlayer é a primeira plataforma de nuvem nativa de agentes, projetada para capacitar agentes de codificação de IA a implantar aplicativos prontos para produção rapidamente. Ela automatiza infraestruturas complexas, permitindo que desenvolvedores e fundadores lancem aplicativos full-stack, APIs e bancos de dados em minutos, sem sobrecarga de DevOps.

Truefoundry
Truefoundry é uma plataforma pronta para empresas para implantar, gerenciar e escalar aplicações de IA agêntica. Ela fornece …
Truefoundry é uma plataforma pronta para empresas para implantar, gerenciar e escalar aplicações de IA agêntica. Ela fornece um Gateway de IA unificado para orquestrar fluxos de trabalho complexos de IA, gerenciar modelos e garantir segurança, governança e observabilidade. Projetada para desenvolvedores e equipes de MLOps, suporta implantações on-premise, na nuvem e híbridas, otimizando a utilização de GPU e acelerando o tempo de lançamento no mercado.
Vespa.ai
Vespa.ai é uma plataforma de busca de IA de alto desempenho para construir aplicações em larga escala. Unifica …
Vespa.ai é uma plataforma de busca de IA de alto desempenho para construir aplicações em larga escala. Unifica a busca vetorial, a busca de texto e a classificação por aprendizado de máquina para potencializar casos de uso avançados como Geração Aumentada por Recuperação (RAG), motores de recomendação e busca inteligente. Projetado para inferência em tempo real e escalabilidade, é confiado por empresas líderes como Spotify e Perplexity para lidar com enormes conjuntos de dados com baixa latência.

Nebius
Nebius é uma plataforma de nuvem de alto desempenho projetada especificamente para cargas de trabalho exigentes de IA …
Nebius é uma plataforma de nuvem de alto desempenho projetada especificamente para cargas de trabalho exigentes de IA e Machine Learning. Oferece acesso escalável às mais recentes GPUs NVIDIA, desde instâncias únicas a clusters massivos, complementado por um conjunto de serviços gerenciados e um AI Studio integrado para otimizar todo o ciclo de vida de ML, do treinamento à inferência.
novita.ai
Novita AI é uma plataforma em nuvem centrada no desenvolvedor que oferece acesso acessível e escalável a mais …
Novita AI é uma plataforma em nuvem centrada no desenvolvedor que oferece acesso acessível e escalável a mais de 200 modelos de IA através de APIs simples. Fornece GPUs sem servidor, instâncias de GPU dedicadas e implantação de modelos personalizados, permitindo que os desenvolvedores construam e escalem aplicações de IA sem gerenciar infraestrutura.
Avian Categoria
Avian Tags
Avian Profissões aplicáveis
Avian Ferramenta de IA
Avian Recurso de Incorporação
Basta copiar o código de incorporação abaixo e colá-lo em seu blog, artigo ou site oficial para exibir um selo elegante que direciona o tráfego diretamente para a página de detalhes desta ferramenta, aumentando rapidamente a visibilidade e o número de usuários!

Ainda não há comentários, seja o primeiro a comentar!