Webcrawlerapi
Visitar Site Oficial
Webcrawlerapi Visão Geral
Webcrawlerapi é uma API especializada projetada para otimizar o processo de rastreamento da web e extração de dados para desenvolvedores. Em uma era onde os dados são cruciais para treinar grandes modelos de linguagem (LLMs) e alimentar aplicações de IA, a raspagem de dados tradicional apresenta desafios significativos. Estes incluem lidar com conteúdo dinâmico renderizado por JavaScript, contornar sistemas anti-bot sofisticados, gerenciar proxies e limpar HTML bagunçado em formatos utilizáveis. A Webcrawlerapi abstrai todas essas complexidades, fornecendo uma interface simples, mas poderosa, para transformar qualquer site em uma fonte de dados estruturada.
Com uma taxa de sucesso relatada de 98% e um tempo médio de rastreamento de apenas 6 segundos, o serviço é construído para eficiência e confiabilidade. Ele permite que os desenvolvedores se concentrem na lógica principal de sua aplicação, em vez de se prenderem às complexidades de construir e manter uma infraestrutura de rastreamento escalável. Ao fornecer um link, os desenvolvedores podem receber conteúdo limpo e pronto para uso em formatos como Markdown, texto ou HTML bruto, tornando-o perfeito para alimentar pipelines de treinamento de modelos de IA ou bases de conhecimento para sistemas RAG.
Como usar Webcrawlerapi
Integrar a Webcrawlerapi em seu projeto é projetado para ser simples. O processo geralmente envolve apenas algumas linhas de código. Primeiro, você precisa se inscrever no site da Webcrawlerapi para obter sua chave de acesso única da API. Em seguida, você pode usar uma de suas bibliotecas de cliente fornecidas para linguagens de programação populares.
Por exemplo, em um ambiente NodeJS, você começaria instalando a biblioteca do cliente via npm: npm i webcrawlerapi-js. Então, em seu código, você importa a biblioteca, cria uma nova instância do cliente com sua chave de API e chama o método `crawl`. Este método aceita parâmetros como a `url` de destino, o `scrape_type` desejado (por exemplo, 'markdown') e limites opcionais como `items_limit`. A API então lida com todo o processo de rastreamento em segundo plano e retorna uma resposta JSON estruturada com os dados extraídos. Padrões de integração simples semelhantes estão disponíveis para Python, PHP e .NET, tornando-o acessível a uma ampla gama de desenvolvedores.
Recursos principais do Webcrawlerapi
- Manuseio Automatizado de Links: A API descobre e gerencia inteligentemente todos os links internos em um site, garantindo um rastreamento abrangente enquanto lida automaticamente com duplicatas e limpa URLs.
- Renderização Avançada de JavaScript: Renderiza efetivamente conteúdo dinâmico do lado do cliente usando um sistema estável e robusto, superando a instabilidade e os problemas de memória frequentemente associados a ferramentas como Puppeteer ou Playwright.
- Evasão Robusta de Anti-Bot: A Webcrawlerapi vem com mecanismos integrados para lidar com CAPTCHAs, bloqueios de IP, limites de taxa e outras defesas anti-bot comuns, garantindo uma alta taxa de sucesso.
- Limpeza Automática de Dados: Inclui regras de análise poderosas para converter HTML bruto e complexo em formatos limpos e estruturados como Markdown ou texto simples, economizando um tempo significativo de pós-processamento para os desenvolvedores.
- Infraestrutura Escalável: O serviço gerencia uma infraestrutura distribuída de rastreadores e proxies, permitindo que você dimensione seus esforços de extração de dados de algumas páginas para milhões sem se preocupar com o hardware subjacente ou o gerenciamento de rede.
- API e SDKs Amigáveis para Desenvolvedores: Oferece uma API simples e bibliotecas de cliente oficiais para as principais linguagens como NodeJS, Python, PHP e .NET, completas com documentação clara.
Casos de uso para Webcrawlerapi
A Webcrawlerapi é versátil e pode ser aplicada a uma variedade de tarefas intensivas em dados. Seus principais casos de uso giram em torno de IA e análise de dados.
- Coleta de Dados para Treinamento de LLM: Rastreie sistematicamente sites, blogs e fóruns para coletar grandes quantidades de dados de texto de alta qualidade e específicos de domínio para treinar ou ajustar modelos de linguagem grandes personalizados.
- Geração Aumentada por Recuperação (RAG): Construa e mantenha bases de conhecimento atualizadas para sistemas RAG. Rastreie documentação de produtos, centrais de ajuda ou sites de notícias para fornecer aos LLMs informações precisas e em tempo real para responder às perguntas dos usuários.
- Pesquisa de Mercado e Análise Competitiva: Extraia automaticamente detalhes de produtos, informações de preços, avaliações de clientes e conteúdo de marketing de sites de concorrentes para obter insights estratégicos.
- Agregação de Conteúdo: Potencialize agregadores de notícias, quadros de empregos ou sites de listagem de imóveis, rastreando regularmente várias fontes и consolidando os dados em uma plataforma unificada.
Vantagens do Webcrawlerapi
A principal vantagem da Webcrawlerapi é sua simplicidade e eficiência. Ela permite que as equipes de desenvolvimento terceirizem toda a infraestrutura de rastreamento da web e o ônus da manutenção. Isso significa um tempo de lançamento mais rápido para produtos orientados a dados. A alta taxa de sucesso (98%) e os recursos robustos anti-bot garantem que os pipelines de dados sejam confiáveis. Além disso, seu modelo de preços transparente e de pagamento conforme o uso é altamente econômico, pois você paga apenas por solicitações bem-sucedidas, eliminando o risco e a sobrecarga associados a assinaturas ou à construção de uma solução interna.
Preços e planos
A Webcrawlerapi emprega um modelo de preços 'pague pelo uso' direto e transparente, evitando completamente assinaturas e taxas ocultas. Os custos são calculados com base no número de páginas que você rastreia com sucesso a cada mês. O serviço inclui trabalhos de rastreamento ilimitados, uma rede de proxy ilimitada e gerenciada automaticamente, e suporte por e-mail em seu preço. Para uma estimativa de custo clara, o site fornece uma calculadora. Como exemplo, rastrear 10.000 páginas em um mês custaria aproximadamente $20. Este modelo é ideal para projetos de todos os tamanhos, desde experimentos em pequena escala até operações de dados em grande escala, pois os custos escalam diretamente com o uso. A plataforma também permite que os usuários experimentem o serviço antes de fazer uma compra, provavelmente através de uma alocação de crédito gratuito para novas contas.
Webcrawlerapi Comentários (0)
Faça login para comentar
Entrar agoraWebcrawlerapiAnálise de Tráfego do Site
Dados de Tráfego Mais Recentes
Status
Tendência Mensal de Tráfego
Localização Geográfica
Top 5 Países/Regiões
-
🇺🇸 United States51,51%
-
🇮🇳 India14,82%
-
🇩🇪 Germany12,24%
-
🇪🇸 Spain11,01%
-
🇧🇷 Brazil10,42%
Palavras-chave Populares
| Palavra-chave | Custo por Clique (CPC) |
|---|---|
|
$0,00
|
|
|
$0,00
|
|
|
$0,00
|
|
|
$0,00
|
|
|
$0,00
|
Webcrawlerapi Alternativas
Ver Tudo
UseScraper
UseScraper é uma poderosa API de crawler e scraper da web projetada para desenvolvedores e aplicações de IA. …
UseScraper é uma poderosa API de crawler e scraper da web projetada para desenvolvedores e aplicações de IA. Extrai dados de qualquer site de forma eficiente, com renderização completa de JavaScript, infraestrutura de autoescalonamento e formatos de saída limpos como Markdown, ideal para alimentar dados em LLMs como o ChatGPT.

Foxscrape
O FoxScrape é uma API REST de web scraping com IA para desenvolvedores. Ele simplifica a extração de …
O FoxScrape é uma API REST de web scraping com IA para desenvolvedores. Ele simplifica a extração de dados convertendo qualquer site em dados JSON estruturados, usando recursos como análise orientada por IA a partir de inglês simples, renderização de JavaScript para sites dinâmicos e rotação automática de proxy para evitar bloqueios.
Browser Use
O Browser Use é um agente de navegador alimentado por IA que automatiza tarefas online repetitivas sem a …
O Browser Use é um agente de navegador alimentado por IA que automatiza tarefas online repetitivas sem a necessidade de código. Ele pode lidar com extração de dados complexa, preenchimento de formulários e outros fluxos de trabalho baseados na web. Apoiado pela Y Combinator, oferece uma interface de chat simples para usuários e uma API poderosa para desenvolvedores otimizarem suas atividades online.
Isomeric
Isomeric é uma API alimentada por IA que transforma texto desestruturado e confuso de qualquer fonte em dados …
Isomeric é uma API alimentada por IA que transforma texto desestruturado e confuso de qualquer fonte em dados JSON limpos e estruturados. Ao definir um esquema JSON simples, você pode extrair automaticamente informações específicas de sites, documentos legais, transcrições de suporte ao cliente e muito mais, otimizando pipelines de dados e automação.
Skrape
Skrape é uma API de web scraping alimentada por LLM, projetada para transformar qualquer site em dados limpos, …
Skrape é uma API de web scraping alimentada por LLM, projetada para transformar qualquer site em dados limpos, estruturados e prontos para LLM. Simplifica a extração de dados convertendo páginas da web em JSON estruturado ou markdown limpo, tornando-o ideal para treinamento de IA, sistemas RAG e análise de dados. Com recursos como manipulação de conteúdo dinâmico e rastreamento inteligente, o Skrape oferece uma solução confiável para desenvolvedores e empresas automatizarem seus pipelines de coleta de dados.
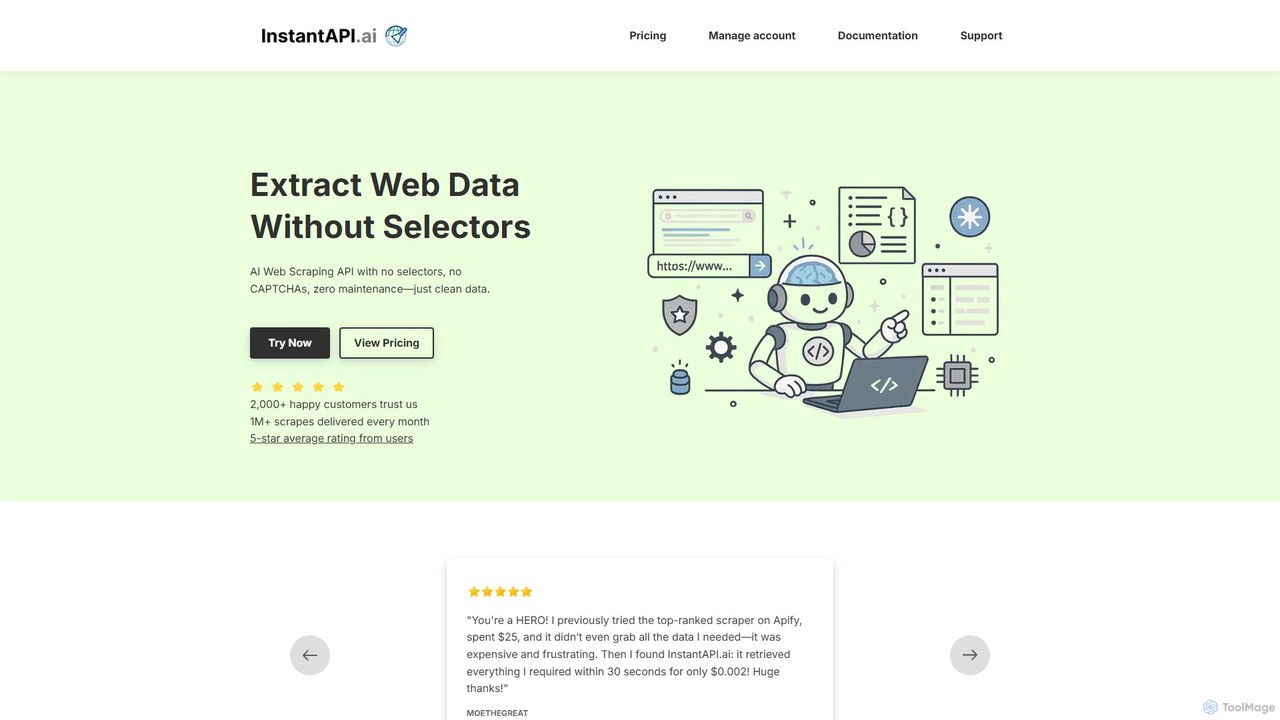
instantapi
O instantapi é uma API de web scraping alimentada por IA, projetada para simplicidade e velocidade. Permite que …
O instantapi é uma API de web scraping alimentada por IA, projetada para simplicidade e velocidade. Permite que os usuários extraiam dados estruturados de qualquer site com uma única chamada de API, eliminando a necessidade de codificação complexa ou configuração manual. Ideal para desenvolvedores, analistas de dados e empresas que precisam de extração de dados rápida, acessível e confiável sem o incômodo dos raspadores da web tradicionais.
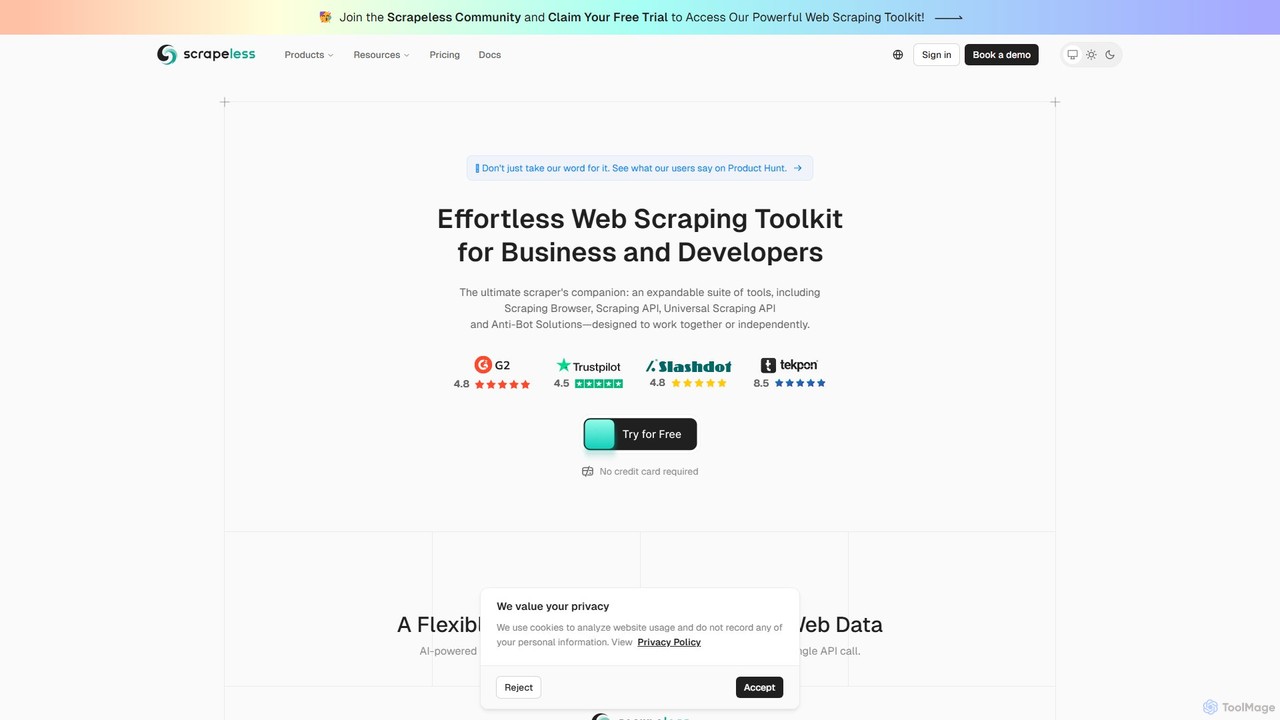
Scrapeless
Um kit de ferramentas de web scraping com tecnologia de IA para desenvolvedores e empresas. Oferece um conjunto …
Um kit de ferramentas de web scraping com tecnologia de IA para desenvolvedores e empresas. Oferece um conjunto de ferramentas, incluindo um Navegador de Scraping, API de Scraping Universal e API Deep SERP para extrair dados públicos da web em escala sem esforço. É especializado em contornar medidas anti-bot, fornecendo dados estruturados para e-commerce, pesquisa de mercado e treinamento de modelos de IA, com foco em confiabilidade e facilidade de uso.
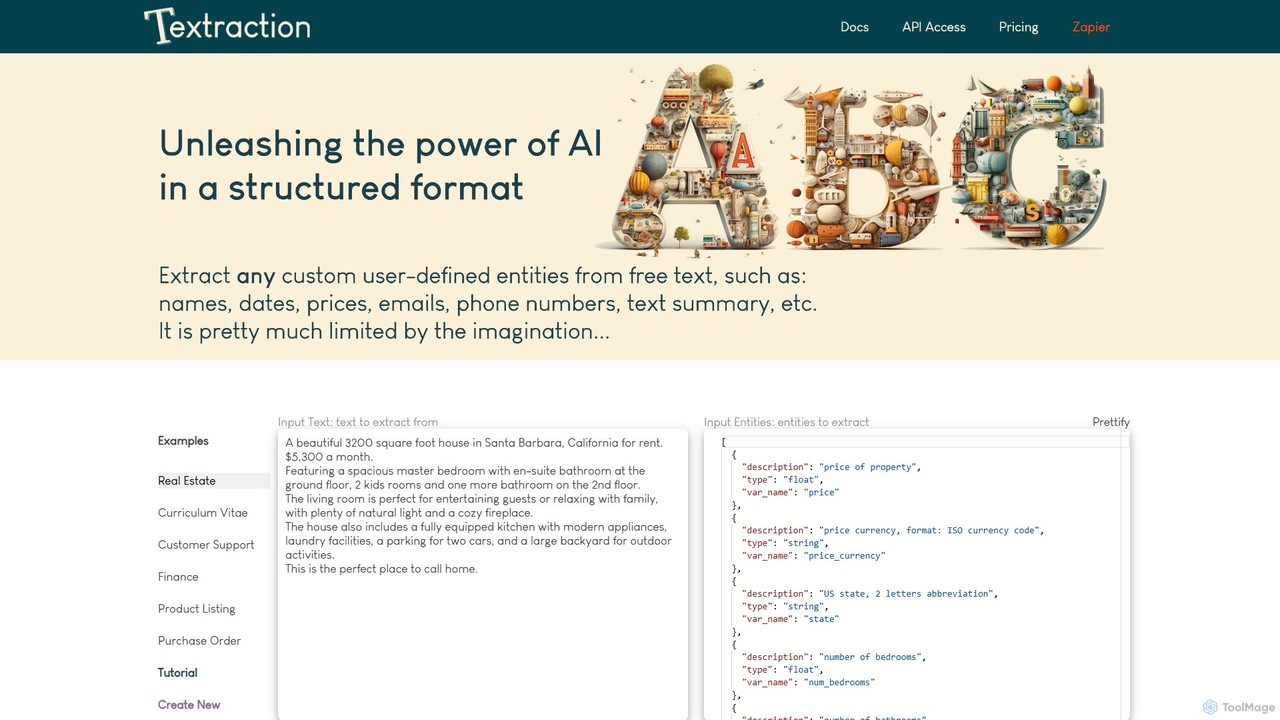
Textraction
Textraction é uma poderosa API alimentada por IA que transforma texto não estruturado em dados estruturados. Simplesmente descrevendo …
Textraction é uma poderosa API alimentada por IA que transforma texto não estruturado em dados estruturados. Simplesmente descrevendo as informações que você precisa em linguagem natural, você pode extrair qualquer entidade de documentos, e-mails ou conteúdo da web. Com integração perfeita de API e Zapier, ele automatiza a extração de dados, convertendo texto desorganizado em formato JSON limpo e pronto para tabelas, suportando múltiplos idiomas e infinitos casos de uso personalizados.

CapSolver
CapSolver é um serviço de resolução automática de CAPTCHA alimentado por IA, projetado para desenvolvedores e profissionais de …
CapSolver é um serviço de resolução automática de CAPTCHA alimentado por IA, projetado para desenvolvedores e profissionais de RPA. Ele fornece uma solução de alta precisão, rápida e escalável para contornar vários tipos de CAPTCHAs, incluindo reCAPTCHA, hCaptcha e FunCaptcha, facilitando a extração de dados da web e a automação de processos sem interrupções.

Apify
Apify é uma plataforma full-stack de web scraping e automação que permite aos desenvolvedores construir, implantar e publicar …
Apify é uma plataforma full-stack de web scraping e automação que permite aos desenvolvedores construir, implantar e publicar ferramentas de extração de dados, conhecidas como 'Actors'. Oferece um vasto mercado de scrapers pré-construídos para sites populares como Google Maps, Instagram e TikTok, juntamente com uma infraestrutura de nuvem robusta para criar soluções personalizadas. Com suporte para Python e JavaScript, bibliotecas de código aberto e integrações perfeitas, a Apify simplifica a coleta de dados da web em qualquer escala.
Webcrawlerapi Categoria
Webcrawlerapi Tags
Webcrawlerapi Ferramenta de IA
Webcrawlerapi Recurso de Incorporação
Basta copiar o código de incorporação abaixo e colá-lo em seu blog, artigo ou site oficial para exibir um selo elegante que direciona o tráfego diretamente para a página de detalhes desta ferramenta, aumentando rapidamente a visibilidade e o número de usuários!

Ainda não há comentários, seja o primeiro a comentar!