
Prodigy
Prodigy là một công cụ chú thích có thể lập trình cho AI, Học máy và NLP, được …
Prodigy là một công cụ chú thích có thể lập trình cho AI, Học máy và NLP, được thiết kế cho các nhà phát triển. Nó cho phép tạo nhanh dữ liệu huấn luyện và đánh giá chất lượng cao thông qua các quy trình làm việc có sự hỗ trợ của mô hình và con người trong vòng lặp. Công cụ chạy trên cơ sở hạ tầng của riêng bạn, đảm bảo quyền riêng tư và kiểm soát dữ liệu hoàn toàn.
SmartOne.ai
SmartOne.ai cung cấp các dịch vụ chú thích và gán nhãn dữ liệu chất lượng cao, có khả …
SmartOne.ai cung cấp các dịch vụ chú thích và gán nhãn dữ liệu chất lượng cao, có khả năng mở rộng cho các mô hình AI và học máy. Chuyên về dữ liệu hình ảnh, video, âm thanh và văn bản, họ cung cấp một đội ngũ chuyên gia được quản lý toàn diện để xử lý các tác vụ chú thích phức tạp. Với trọng tâm là tác động xã hội, SmartOne.ai cung cấp dữ liệu đào tạo chính xác đồng thời tạo ra cơ hội nghề nghiệp tại các cộng đồng đang phát triển.
BasicAI
BasicAI cung cấp một nền tảng chú thích dữ liệu toàn diện và các dịch vụ được quản …
BasicAI cung cấp một nền tảng chú thích dữ liệu toàn diện và các dịch vụ được quản lý để tạo dữ liệu huấn luyện chất lượng cao cho các mô hình AI. Nền tảng này chuyên về dữ liệu 3D LiDAR, hình ảnh, video và NLP, cung cấp các công cụ hỗ trợ bởi AI, quy trình làm việc có thể mở rộng và bảo mật cấp doanh nghiệp để tăng tốc phát triển AI.
Athina
Athina là một nền tảng phát triển AI hợp tác được thiết kế để giúp các nhóm xây …
Athina là một nền tảng phát triển AI hợp tác được thiết kế để giúp các nhóm xây dựng, thử nghiệm và giám sát các ứng dụng LLM nhanh hơn 10 lần. Nó cung cấp một bộ công cụ toàn diện cho kỹ thuật prompt, đánh giá, thử nghiệm, chú thích và giám sát sản xuất. Athina hỗ trợ cả người dùng kỹ thuật và phi kỹ thuật, đảm bảo sự hợp tác liền mạch và triển khai các hệ thống AI chất lượng cao, đáng tin cậy.
balise
Balise là một nền tảng chú thích dữ liệu được hỗ trợ bởi AI, được thiết kế để …
Balise là một nền tảng chú thích dữ liệu được hỗ trợ bởi AI, được thiết kế để hợp lý hóa việc tạo dữ liệu huấn luyện chất lượng cao cho các mô hình học máy. Nó cung cấp một môi trường hợp tác với các công cụ thông minh để gán nhãn hình ảnh, văn bản, video và âm thanh, giúp tăng tốc chu kỳ phát triển cho các dự án thị giác máy tính và NLP.
OpenTrain AI
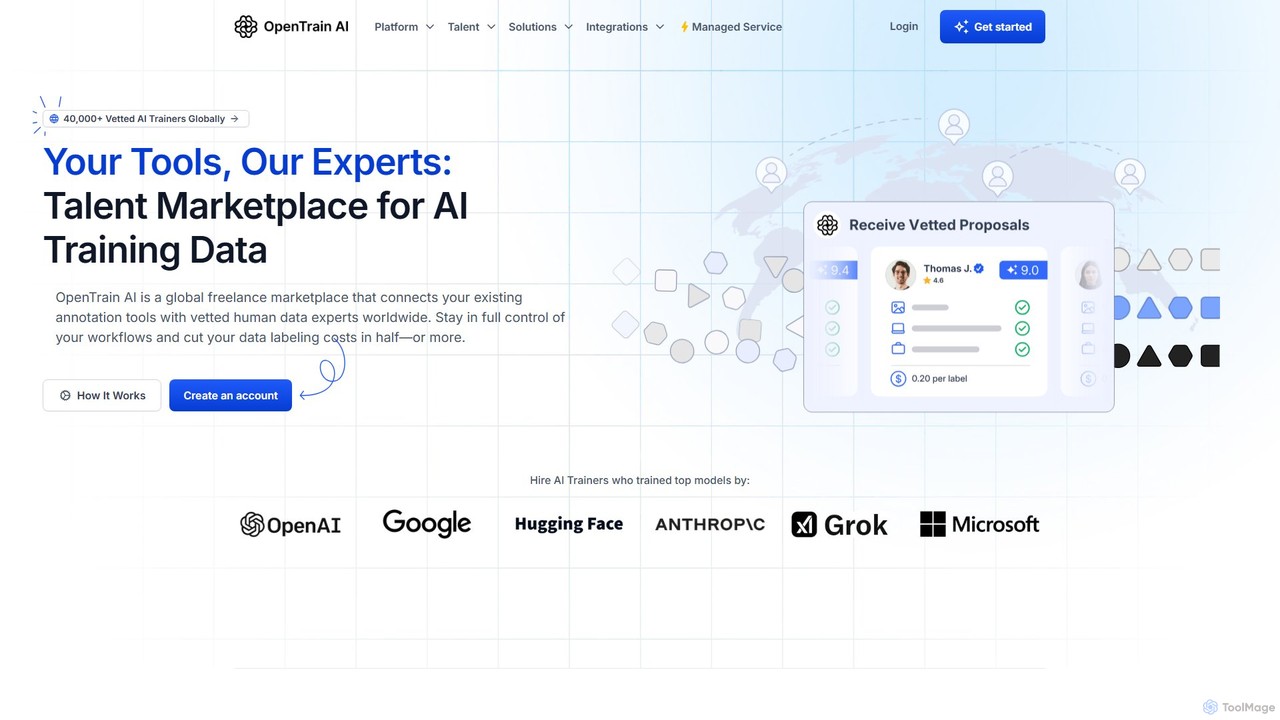
OpenTrain AI là một thị trường nhân tài toàn cầu kết nối doanh nghiệp với hơn 40.000 chuyên …
OpenTrain AI là một thị trường nhân tài toàn cầu kết nối doanh nghiệp với hơn 40.000 chuyên gia dữ liệu con người đã được kiểm duyệt để đào tạo AI và chú thích dữ liệu. Nền tảng này cho phép bạn sử dụng các công cụ chú thích hiện có của mình trong khi thuê các freelancer chuyên môn hoặc các nhóm được quản lý từ hơn 110 quốc gia. Cách tiếp cận linh hoạt này giúp bạn duy trì toàn quyền kiểm soát quy trình làm việc, cải thiện chất lượng dữ liệu và giảm đáng kể chi phí ghi nhãn.
Playment
Playment là một nền tảng giải pháp dữ liệu cấp doanh nghiệp, hiện là một phần của TELUS …
Playment là một nền tảng giải pháp dữ liệu cấp doanh nghiệp, hiện là một phần của TELUS International. Nền tảng này chuyên cung cấp dữ liệu chất lượng cao do con người chú thích để huấn luyện và xác thực các mô hình AI và học máy. Tận dụng cộng đồng toàn cầu với hơn một triệu người đóng góp, Playment cung cấp các dịch vụ như thu thập, chú thích và xác thực dữ liệu cho thị giác máy tính, NLP và AI tạo sinh, đảm bảo tốc độ, quy mô và độ chính xác cho các dự án AI đầy tham vọng.
Encord
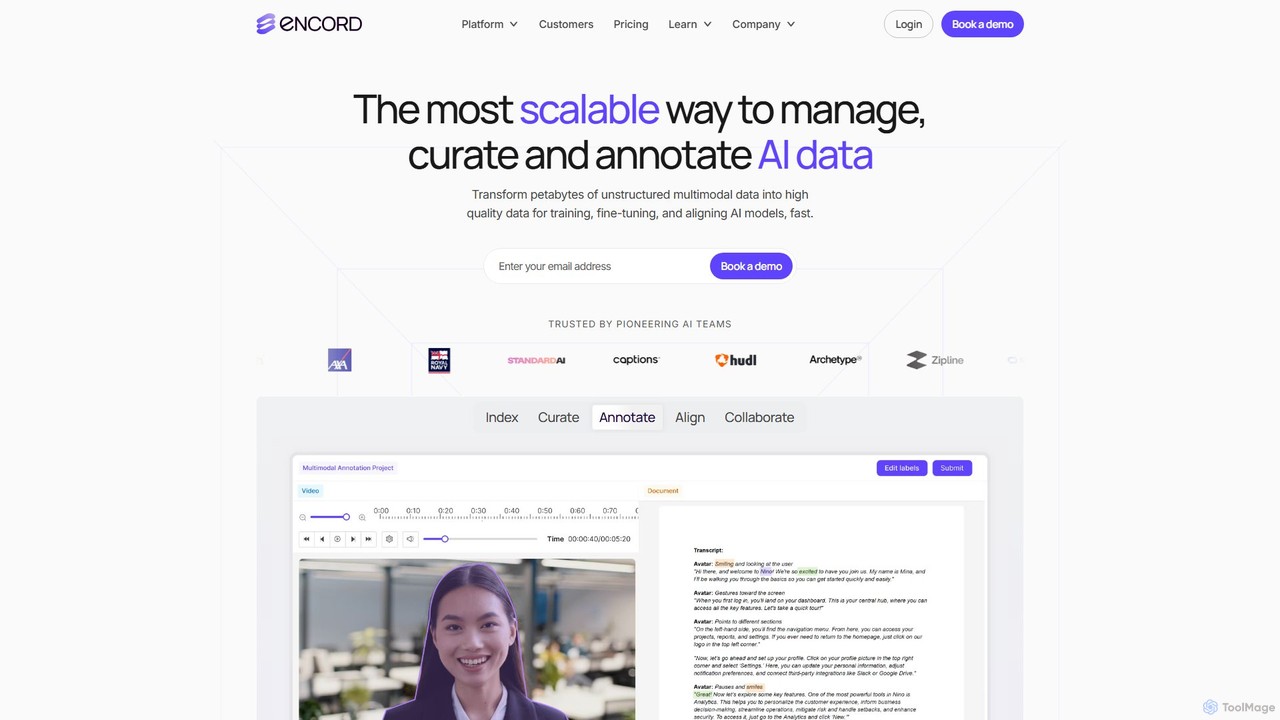
Encord là một nền tảng phát triển dữ liệu toàn diện cho AI thị giác và đa phương …
Encord là một nền tảng phát triển dữ liệu toàn diện cho AI thị giác và đa phương thức. Nó cung cấp các công cụ để quản lý, giám tuyển và chú thích dữ liệu phi cấu trúc quy mô lớn như hình ảnh, video và tệp DICOM. Nền tảng này giúp các nhóm AI xây dựng bộ dữ liệu chất lượng cao, cải thiện hiệu suất mô hình và tăng tốc triển khai các ứng dụng AI sẵn sàng cho sản xuất thông qua việc gán nhãn nâng cao, đánh giá mô hình và quy trình làm việc có sự tham gia của con người.
Appen
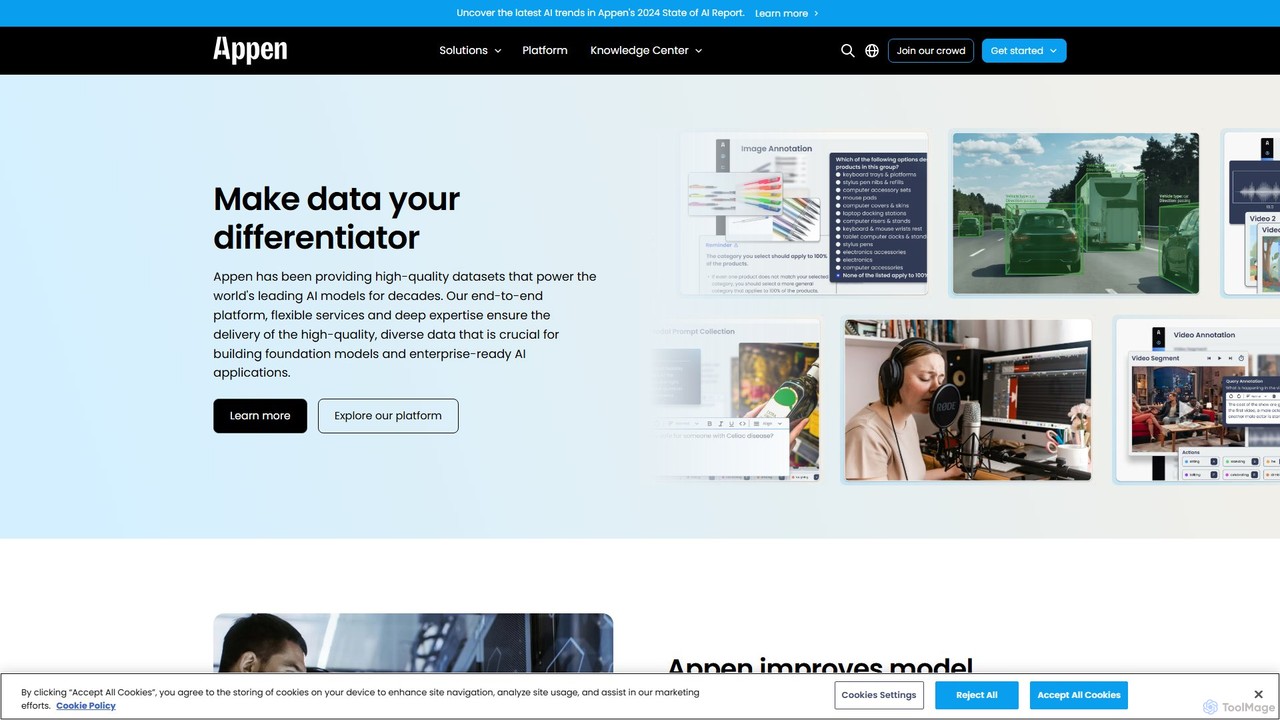
Appen là công ty hàng đầu thế giới trong việc cung cấp dữ liệu chất lượng cao do …
Appen là công ty hàng đầu thế giới trong việc cung cấp dữ liệu chất lượng cao do con người chú thích cho các mô hình AI và học máy. Nền tảng này cung cấp dịch vụ thu thập và chú thích dữ liệu quy mô lớn, tận dụng cộng đồng toàn cầu để thúc đẩy các ứng dụng AI trong thị giác máy tính, NLP, v.v. cho các thương hiệu hàng đầu thế giới.
Về Chú thích
Công cụ chú thích là các nền tảng chuyên dụng để gán nhãn dữ liệu, chẳng hạn như hình ảnh, văn bản và âm thanh, nhằm tạo ra các bộ dữ liệu huấn luyện chất lượng cao cho các mô hình học máy. Các công cụ này cung cấp một giao diện có cấu trúc và các chức năng chuyên biệt để gắn thẻ, phân loại hoặc phân đoạn dữ liệu thô một cách chính xác, biến chúng thành định dạng mà thuật toán AI có thể hiểu được. Chúng là một phần cơ bản của quy trình Dữ liệu cho học có giám sát, ảnh hưởng trực tiếp đến hiệu suất và độ chính xác của hệ thống AI. Nhiều nền tảng chú thích hiện đại tích hợp các tính năng được hỗ trợ bởi AI để đẩy nhanh quá trình gán nhãn thủ công tốn thời gian.
Tính Năng Cốt Lõi
- Gán nhãn đa phương thức: Hỗ trợ nhiều loại chú thích khác nhau như hộp giới hạn, đa giác, phân đoạn ngữ nghĩa, điểm mốc và nhận dạng thực thể có tên (NER).
- Quản lý quy trình làm việc: Các công cụ để giao nhiệm vụ, theo dõi tiến độ và triển khai các chu trình xem xét và đảm bảo chất lượng (QA) đa giai đoạn.
- Chú thích được hỗ trợ bởi AI: Các tính năng như gán nhãn trước bằng các mô hình hiện có, phân đoạn tương tác và theo dõi đối tượng để tự động hóa một phần quy trình gán nhãn.
- Tương thích định dạng dữ liệu: Khả năng nhập dữ liệu thô và xuất các bộ dữ liệu đã được gán nhãn ở các định dạng tiêu chuẩn như COCO, YOLO, Pascal VOC hoặc JSON.
- Hợp tác & Kiểm soát chất lượng: Chức năng cho phép nhiều người chú thích làm việc trên các dự án với hướng dẫn rõ ràng, cơ chế đồng thuận và phân tích hiệu suất.
Trường Hợp Sử Dụng
Công cụ chú thích rất quan trọng trong các ngành công nghiệp phát triển giải pháp AI. Trong lĩnh vực lái xe tự hành, chúng được sử dụng để gán nhãn cho người đi bộ và phương tiện. Trong y tế, chúng giúp phân đoạn hình ảnh y tế để chẩn đoán. Đối với xử lý ngôn ngữ tự nhiên (NLP), chúng được sử dụng để gắn thẻ văn bản cho phân tích cảm xúc và huấn luyện chatbot. Các nền tảng thương mại điện tử sử dụng chúng để phân loại sản phẩm từ hình ảnh và mô tả.
Cách Lựa Chọn
Khi chọn một công cụ chú thích, trước tiên hãy xem xét các loại dữ liệu và độ phức tạp của chú thích mà nó hỗ trợ. Đánh giá các tính năng hợp tác và quản lý dự án của nó cho các quy trình làm việc theo nhóm. Đánh giá hiệu quả của các khả năng gán nhãn được hỗ trợ bởi AI để đo lường khả năng tiết kiệm thời gian. Cuối cùng, hãy kiểm tra các tùy chọn tích hợp và đảm bảo nó có thể xuất dữ liệu ở các định dạng tương thích với quy trình huấn luyện mô hình và yêu cầu bảo mật của bạn.
Chú thíchTrường hợp sử dụng
Huấn luyện Thị giác Máy tính cho Xe tự hành
Các nhóm chú thích dữ liệu tại các công ty ô tô và công nghệ sử dụng những công cụ này để xử lý lượng lớn dữ liệu video và LiDAR từ các phương tiện thử nghiệm. Người chú thích tỉ mỉ vẽ các hộp giới hạn xung quanh ô tô, người đi bộ và người đi xe đạp, áp dụng phân đoạn ngữ nghĩa cho lòng đường và vạch kẻ làn, và theo dõi các đối tượng qua nhiều khung hình. Dữ liệu được gán nhãn với độ chính xác cao này là cần thiết để huấn luyện các mô hình nhận thức cho phép xe tự lái hiểu môi trường xung quanh và đưa ra quyết định lái xe an toàn. Chất lượng của việc chú thích tương quan trực tiếp đến sự an toàn và độ tin cậy của hệ thống tự hành.
Phát triển AI để Phân tích Hình ảnh Y tế
Các bác sĩ X-quang và nhà nghiên cứu y học sử dụng các công cụ chú thích chuyên dụng để phân tích các bản quét y tế như X-quang, CT và MRI. Họ cẩn thận phác thảo các khối u, tổn thương hoặc các bất thường khác bằng các công cụ đa giác hoặc phân đoạn. Những chú thích này tạo ra các bộ dữ liệu để huấn luyện các mô hình AI có thể hỗ trợ phát hiện bệnh sớm, chẩn đoán và lập kế hoạch điều trị. Các công cụ này thường cần hỗ trợ các định dạng hình ảnh y tế cụ thể như DICOM và cung cấp các công cụ có độ chính xác cao để đảm bảo độ chính xác cần thiết cho các ứng dụng lâm sàng. Các tính năng hợp tác cho phép đánh giá ngang hàng và xác thực bởi nhiều chuyên gia.
Xây dựng Bộ dữ liệu cho Chatbot AI đàm thoại
Các chuyên gia Xử lý Ngôn ngữ Tự nhiên (NLP) và nhà ngôn ngữ học sử dụng các công cụ chú thích văn bản để chuẩn bị dữ liệu cho việc huấn luyện chatbot và trợ lý ảo. Họ thực hiện các nhiệm vụ như Nhận dạng Thực thể có tên (NER) để xác định tên, địa điểm và ngày tháng, và phân loại ý định để hiểu mục tiêu của người dùng (ví dụ: 'đặt chuyến bay', 'kiểm tra số dư'). Bằng cách gán nhãn cho hàng nghìn truy vấn của người dùng, họ tạo ra một bộ dữ liệu có cấu trúc để dạy AI hiểu các cách diễn đạt đa dạng và phản hồi chính xác. Quá trình này rất quan trọng để xây dựng các tác nhân đàm thoại có cảm giác tự nhiên và thực sự hữu ích cho người dùng.
Nâng cao Tìm kiếm Sản phẩm Thương mại điện tử bằng AI
Các nhà khoa học dữ liệu thương mại điện tử sử dụng các công cụ chú thích để cải thiện các công cụ khám phá và đề xuất sản phẩm. Họ gán nhãn cho hình ảnh sản phẩm với các thuộc tính như 'màu: đỏ', 'phong cách: thường ngày' hoặc 'chất liệu: cotton'. Họ cũng phân loại tiêu đề và mô tả sản phẩm vào một hệ thống phân loại có cấu trúc. Dữ liệu được làm giàu này cho phép các mô hình AI hiểu sâu hơn về các đặc tính của sản phẩm, dẫn đến kết quả tìm kiếm phù hợp hơn và các đề xuất được cá nhân hóa. Ví dụ, một người dùng tìm kiếm 'váy hè màu đỏ' có nhiều khả năng tìm thấy chính xác những gì họ muốn, cải thiện trải nghiệm người dùng và tỷ lệ chuyển đổi.
Tự động hóa Kiểm soát Chất lượng trong Sản xuất
Trong môi trường công nghiệp, các kỹ sư AI sử dụng các công cụ chú thích để xây dựng hệ thống kiểm tra bằng hình ảnh. Họ gán nhãn cho hình ảnh của các sản phẩm trên dây chuyền lắp ráp, đánh dấu các khiếm khuyết như vết trầy xước, vết nứt hoặc lệch vị trí. Một mô hình AI được huấn luyện trên dữ liệu này sau đó có thể tự động xác định các mặt hàng bị lỗi trong thời gian thực, vượt xa tốc độ và tính nhất quán của các thanh tra viên con người. Ứng dụng này của thị giác máy tính giúp các nhà sản xuất cải thiện chất lượng sản phẩm, giảm lãng phí và tăng hiệu quả sản xuất tổng thể. Quá trình chú thích rất quan trọng để dạy AI phân biệt giữa các biến thể chấp nhận được và các khiếm khuyết thực tế.
Tạo Bộ dữ liệu cho AI kiểm duyệt nội dung
Các nhóm tin cậy và an toàn tại các công ty truyền thông xã hội và nền tảng trực tuyến sử dụng các công cụ chú thích để xây dựng hệ thống kiểm duyệt nội dung do AI cung cấp. Người chú thích xem xét nội dung do người dùng tạo (văn bản, hình ảnh, video) và gán nhãn cho nó theo các chính sách cụ thể, chẳng hạn như 'lời nói căm thù', 'thư rác' hoặc 'nội dung phản cảm'. Dữ liệu được gán nhãn này được sử dụng để huấn luyện các mô hình học máy có thể tự động gắn cờ hoặc xóa nội dung có hại trên quy mô lớn. Quá trình này rất quan trọng để duy trì một môi trường trực tuyến an toàn và đòi hỏi các công cụ có thể xử lý khối lượng lớn các loại nội dung đa dạng đồng thời đảm bảo sức khỏe cho người chú thích.