Sinkove
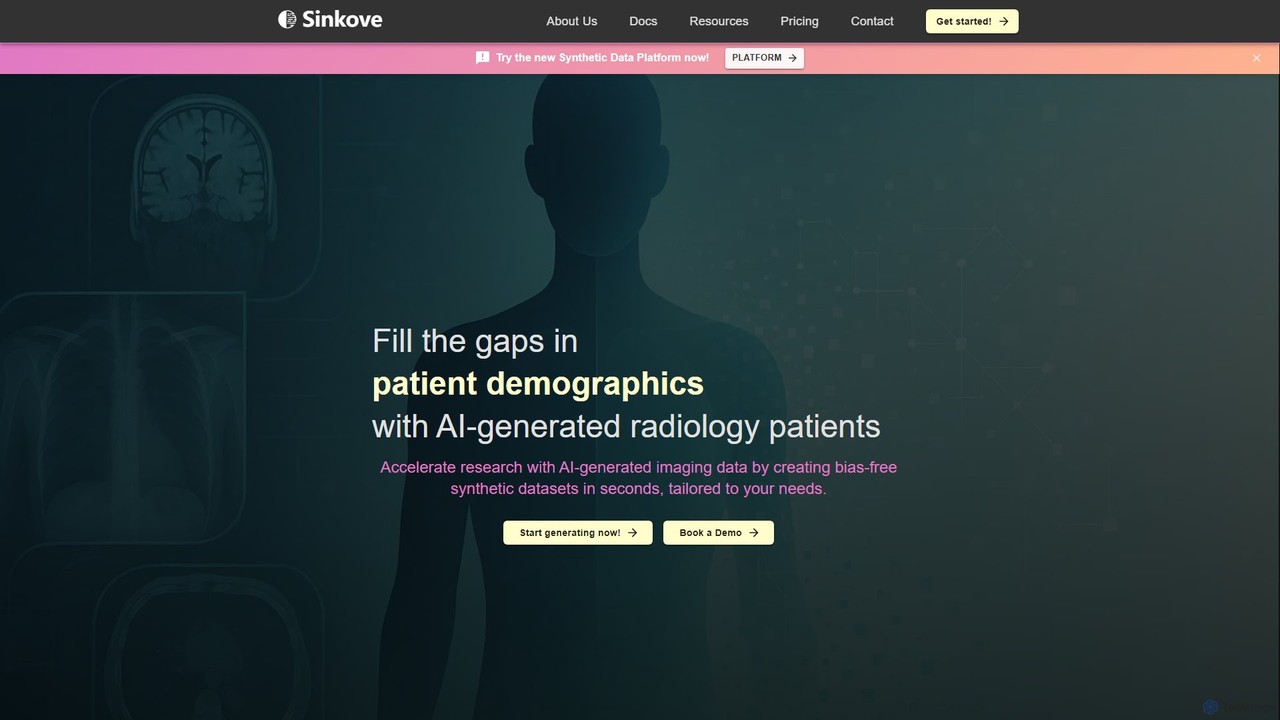
Sinkove là một nền tảng AI tạo ra dữ liệu X-quang tổng hợp chất lượng cao. Nó giúp …
Sinkove là một nền tảng AI tạo ra dữ liệu X-quang tổng hợp chất lượng cao. Nó giúp các nhà nghiên cứu y khoa và bác sĩ lâm sàng đẩy nhanh nghiên cứu, loại bỏ sai lệch dữ liệu và giảm chi phí bằng cách tạo ra các bộ dữ liệu hình ảnh tùy chỉnh, đa dạng và đạt tiêu chuẩn quy định trong vài giây.

maketafi
Tafi là nhà cung cấp hàng đầu về bộ dữ liệu nhân vật 3D cấp doanh nghiệp cho …
Tafi là nhà cung cấp hàng đầu về bộ dữ liệu nhân vật 3D cấp doanh nghiệp cho việc huấn luyện AI, mô phỏng và sáng tạo nội dung. Nền tảng này cung cấp các nhân vật 3D có thể mở rộng, đồng nhất về cấu trúc liên kết và được tạo theo tham số, hoàn chỉnh với siêu dữ liệu phong phú, để cung cấp năng lượng cho các mô hình AI tiên tiến trong lĩnh vực robot, trò chơi, XR và học đa phương thức.
Về Tạo dữ liệu tổng hợp
Công cụ Tạo dữ liệu tổng hợp là một loại ứng dụng AI tạo ra dữ liệu nhân tạo theo chương trình nhằm phản ánh các thuộc tính thống kê của dữ liệu trong thế giới thực. Các công cụ này thường tận dụng các mô hình học máy tiên tiến, chẳng hạn như Mạng đối nghịch tạo sinh (GAN), để học các mẫu từ một tập dữ liệu gốc và sau đó tạo ra các điểm dữ liệu mới, không tồn tại. Giá trị chính nằm ở việc cho phép huấn luyện mô hình AI mạnh mẽ và thử nghiệm phần mềm trong các tình huống dữ liệu thực khan hiếm, nhạy cảm hoặc bị hạn chế bởi các quy định về quyền riêng tư. Cách tiếp cận này cung cấp một phương pháp có thể mở rộng và tuân thủ quyền riêng tư để tăng cường tập dữ liệu và khám phá các trường hợp đặc biệt mà không để lộ thông tin thực tế.
Tính năng cốt lõi
- Tổng hợp loại dữ liệu: Tạo ra các định dạng dữ liệu khác nhau, bao gồm dữ liệu dạng bảng, chuỗi thời gian, hình ảnh và văn bản, để phù hợp với nhu cầu cụ thể.
- Độ trung thực thống kê: Đảm bảo dữ liệu tổng hợp duy trì cùng phân phối thống kê, tương quan và các mẫu giống như dữ liệu gốc.
- Bảo vệ quyền riêng tư: Triển khai các kỹ thuật như Quyền riêng tư vi phân để đảm bảo rằng dữ liệu được tạo ra không thể truy ngược lại bất kỳ cá nhân thực nào.
- Tăng cường dữ liệu: Tạo ra các biến thể của các điểm dữ liệu hiện có để cân bằng các tập dữ liệu không cân bằng hoặc mở rộng tập huấn luyện để cải thiện độ bền của mô hình.
- Mô phỏng kịch bản: Cho phép tạo ra dữ liệu đại diện cho các kịch bản cụ thể, hiếm gặp hoặc giả định không có trong tập dữ liệu gốc.
Trường hợp sử dụng
Các công cụ này được sử dụng rộng rãi trong các ngành xử lý thông tin nhạy cảm, chẳng hạn như y tế để tạo hồ sơ bệnh nhân ẩn danh cho nghiên cứu, và tài chính để lập mô hình các mẫu gian lận mà không sử dụng dữ liệu giao dịch thực. Chúng cũng rất cần thiết cho các công ty công nghệ, đặc biệt là trong việc huấn luyện xe tự hành bằng cách mô phỏng các điều kiện lái xe hiếm gặp và cho các nhà phát triển phần mềm cần dữ liệu người dùng thực tế để thử nghiệm ứng dụng mà không ảnh hưởng đến quyền riêng tư.
Cách chọn
Khi chọn một công cụ Tạo dữ liệu tổng hợp, trước tiên hãy xem xét các loại dữ liệu mà nó hỗ trợ (ví dụ: dạng bảng, hình ảnh, văn bản). Đánh giá chất lượng và độ trung thực của dữ liệu được tạo bằng cách kiểm tra các chỉ số tương đồng thống kê. Đánh giá sức mạnh của các tính năng bảo vệ quyền riêng tư của nó, chẳng hạn như hỗ trợ Quyền riêng tư vi phân. Cuối cùng, hãy xem xét khả năng mở rộng của nó đối với các tập dữ liệu lớn và liệu nó có cung cấp giao diện thân thiện với người dùng hay yêu cầu chuyên môn kỹ thuật sâu thông qua API.
Tạo dữ liệu tổng hợpTrường hợp sử dụng
Huấn luyện mô hình AI với dữ liệu nhạy cảm về quyền riêng tư
Một viện nghiên cứu y tế cần phát triển một mô hình học máy để dự đoán sự bùng phát dịch bệnh nhưng bị hạn chế bởi các luật bảo vệ quyền riêng tư nghiêm ngặt của bệnh nhân như HIPAA. Việc sử dụng dữ liệu bệnh nhân thực không phải là một lựa chọn. Các nhà khoa học dữ liệu sử dụng một công cụ tạo dữ liệu tổng hợp để phân tích cấu trúc thống kê của hồ sơ bệnh nhân bí mật. Công cụ sau đó tạo ra một tập dữ liệu mới, hoàn toàn nhân tạo, bắt chước các mẫu, tương quan và phân phối của dữ liệu gốc mà không chứa bất kỳ thông tin sức khỏe cá nhân thực nào. Điều này cho phép các nhà nghiên cứu huấn luyện, kiểm tra và xác thực các mô hình dự đoán của họ một cách hiệu quả và an toàn, đẩy nhanh nghiên cứu y tế trong khi đảm bảo tính bảo mật hoàn toàn cho bệnh nhân.
Tăng cường tập dữ liệu không cân bằng để phát hiện gian lận
Một công ty dịch vụ tài chính đang xây dựng một mô hình để phát hiện các giao dịch gian lận. Thách thức là các trường hợp gian lận cực kỳ hiếm so với các trường hợp hợp pháp, tạo ra một tập dữ liệu rất không cân bằng làm sai lệch mô hình. Một kỹ sư ML sử dụng một công cụ tạo dữ liệu tổng hợp để tạo ra các ví dụ thực tế, chất lượng cao về các giao dịch gian lận. Bằng cách lấy mẫu quá mức lớp thiểu số (gian lận) với dữ liệu tổng hợp này, họ tạo ra một tập huấn luyện cân bằng. Mô hình kết quả trở nên chính xác hơn đáng kể trong việc xác định các mẫu gian lận hiếm gặp, giảm tổn thất tài chính mà không làm tăng các trường hợp dương tính giả đối với các giao dịch hợp pháp.
Mô phỏng các trường hợp đặc biệt để huấn luyện xe tự hành
Một công ty ô tô đang phát triển hệ thống nhận thức của xe tự lái. Hệ thống cần được huấn luyện trên vô số kịch bản, đặc biệt là các 'trường hợp đặc biệt' hiếm gặp và nguy hiểm như người đi bộ đột ngột xuất hiện từ phía sau xe buýt hoặc điều kiện thời tiết khắc nghiệt. Việc thu thập đủ dữ liệu thực tế cho tất cả các tình huống này là không thực tế và không an toàn. Các kỹ sư sử dụng một nền tảng tạo dữ liệu tổng hợp để tạo ra các mô phỏng chân thực như ảnh của các trường hợp đặc biệt cụ thể này. Điều này cho phép họ tạo ra một lượng lớn dữ liệu huấn luyện cho các sự kiện hiếm gặp, cải thiện đáng kể độ tin cậy và an toàn của AI trong các tình huống quan trọng trước khi triển khai trong thế giới thực.
Tăng tốc kiểm thử phần mềm và đảm bảo chất lượng
Một nhóm phát triển phần mềm đang tạo ra một nền tảng quản lý quan hệ khách hàng (CRM) mới. Để đảm bảo phần mềm hoạt động ổn định, họ cần kiểm thử nó với một cơ sở dữ liệu lớn, đa dạng về hồ sơ người dùng, tương tác và lịch sử. Việc tạo dữ liệu này theo cách thủ công rất chậm và thường thiếu tính thực tế. Nhóm QA sử dụng một công cụ dữ liệu tổng hợp để nhanh chóng tạo ra hàng nghìn tài khoản người dùng thực tế nhưng hoàn toàn hư cấu, với đầy đủ tên, chi tiết liên hệ và nhật ký hoạt động. Điều này cho phép họ thực hiện kiểm thử tải toàn diện, tìm lỗi và xác thực tính năng trên một loạt các kịch bản dữ liệu, dẫn đến việc ra mắt sản phẩm chất lượng cao hơn.
Tạo dữ liệu thực tế cho các buổi giới thiệu sản phẩm
Một công ty phần mềm B2B cần giới thiệu nền tảng phân tích dữ liệu mạnh mẽ của mình cho các khách hàng tiềm năng. Việc sử dụng dữ liệu khách hàng thực trong một buổi giới thiệu trực tiếp là một rủi ro lớn về bảo mật và quyền riêng tư. Các nhóm tiếp thị và bán hàng sử dụng một công cụ tạo dữ liệu tổng hợp để tạo ra một tập dữ liệu phong phú, đáng tin cậy phản ánh ngành mục tiêu của họ. Tập dữ liệu này điền vào môi trường giới thiệu với tên khách hàng, số liệu bán hàng và chỉ số tương tác thực tế. Kết quả là, họ có thể cung cấp các buổi giới thiệu sản phẩm hấp dẫn, tương tác, làm nổi bật toàn bộ khả năng của nền tảng mà không bao giờ để lộ thông tin nhạy cảm, xây dựng lòng tin với khách hàng tiềm năng.
Mô hình hóa các kịch bản tương lai để phân tích rủi ro tài chính
Một nhóm quản lý rủi ro tại một ngân hàng đầu tư cần kiểm tra sức chịu đựng của danh mục đầu tư của họ trước các sự cố thị trường tiềm ẩn hoặc các sự kiện kinh tế không lường trước được. Dữ liệu lịch sử có hạn và có thể không bao gồm các kịch bản mới. Nhóm sử dụng một công cụ tạo dữ liệu tổng hợp để tạo dữ liệu chuỗi thời gian mô phỏng các điều kiện thị trường căng thẳng cao khác nhau, chẳng hạn như lạm phát nhanh hoặc bong bóng tài sản vỡ đột ngột. Bằng cách chạy các mô hình rủi ro của họ trên dữ liệu tổng hợp này, họ có thể hiểu rõ hơn về các lỗ hổng tiềm ẩn trong chiến lược đầu tư của mình và phát triển các kế hoạch tài chính linh hoạt hơn, cải thiện sự chuẩn bị của họ cho sự biến động của thị trường trong tương lai.