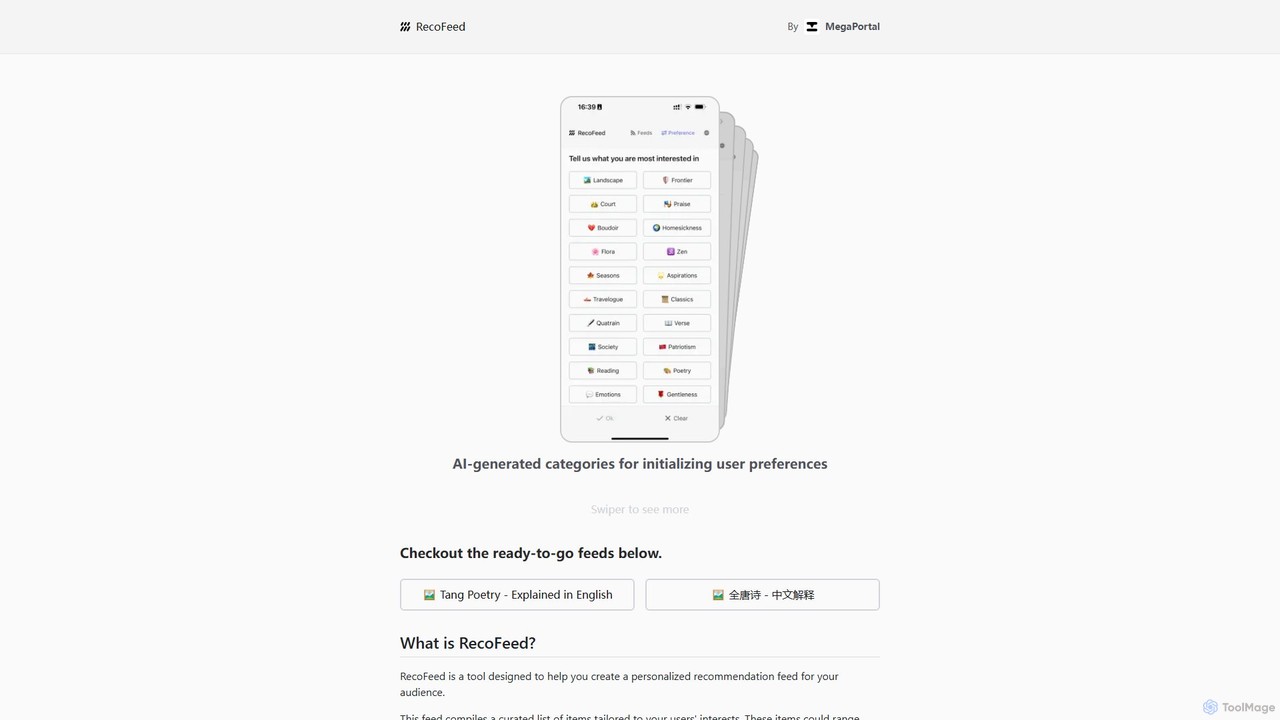
RecoFeed
RecoFeed là một công cụ tập trung vào nhà phát triển để tạo các luồng đề xuất được …
RecoFeed là một công cụ tập trung vào nhà phát triển để tạo các luồng đề xuất được cá nhân hóa. Nó sử dụng cơ sở dữ liệu vector trên thiết bị, CloseVector, để tạo ra các đề xuất thời gian thực ngay trên thiết bị của người dùng, đảm bảo quyền riêng tư dữ liệu tối đa và độ trễ thấp. Nó được thiết kế cho các ứng dụng và trang web trong nhiều lĩnh vực như thương mại điện tử, nền tảng nội dung và mạng xã hội.
Về Cơ sở dữ liệu vector
Cơ sở dữ liệu vector là một hệ thống cơ sở dữ liệu chuyên dụng được thiết kế để lưu trữ, quản lý và tìm kiếm các nhúng vector đa chiều một cách hiệu quả. Không giống như các cơ sở dữ liệu truyền thống lập chỉ mục dữ liệu dựa trên các giá trị chính xác, cơ sở dữ liệu vector sử dụng thuật toán Láng giềng gần nhất xấp xỉ (ANN) để tìm các mục tương tự nhất dựa trên biểu diễn vector của chúng. Khả năng này là nền tảng để cung cấp năng lượng cho các ứng dụng AI tiên tiến như tìm kiếm ngữ nghĩa, công cụ đề xuất và thế hệ tăng cường truy xuất (RAG) cho các mô hình ngôn ngữ lớn. Chúng cung cấp tốc độ và khả năng mở rộng vượt trội cho các tác vụ tìm kiếm tương đồng trên các bộ dữ liệu phi cấu trúc khổng lồ như văn bản, hình ảnh và âm thanh.
Tính năng cốt lõi
- Lập chỉ mục Vector đa chiều: Tổ chức dữ liệu vector một cách hiệu quả bằng các thuật toán như HNSW hoặc IVF để truy xuất nhanh chóng.
- Tìm kiếm tương đồng: Thực hiện tìm kiếm dựa trên sự gần gũi của vector (ví dụ: độ tương đồng cosine, khoảng cách Euclidean) để tìm các mục tương tự về mặt ngữ nghĩa.
- Khả năng mở rộng và Hiệu suất: Được thiết kế để xử lý hàng tỷ vector và tải truy vấn cao với độ trễ thấp, rất quan trọng cho các ứng dụng thời gian thực.
- Lọc siêu dữ liệu: Kết hợp tìm kiếm tương đồng vector với lọc siêu dữ liệu truyền thống để có kết quả chính xác và nhận biết ngữ cảnh hơn.
Trường hợp sử dụng
Cơ sở dữ liệu vector rất cần thiết cho các kỹ sư AI/ML, nhà khoa học dữ liệu và nhà phát triển xây dựng các ứng dụng đòi hỏi sự hiểu biết về các mối quan hệ ngữ nghĩa trong dữ liệu. Chúng được sử dụng rộng rãi trong thương mại điện tử để tìm kiếm bằng hình ảnh và đề xuất, trong các hệ thống doanh nghiệp để tìm kiếm cơ sở kiến thức thông minh, và trong AI tạo sinh để cung cấp ngữ cảnh thực tế cho các mô hình ngôn ngữ lớn, giảm thiểu sự thiếu chính xác.
Cách chọn
Khi chọn một cơ sở dữ liệu vector, hãy đánh giá các thuật toán lập chỉ mục và các tiêu chuẩn hiệu suất của nó đối với loại dữ liệu cụ thể của bạn. Xem xét mô hình triển khai — các dịch vụ được quản lý trên đám mây mang lại sự dễ sử dụng, trong khi các tùy chọn tự lưu trữ cung cấp nhiều quyền kiểm soát hơn. Ngoài ra, hãy kiểm tra các SDK mạnh mẽ bằng ngôn ngữ lập trình ưa thích của bạn và tích hợp với các framework AI phổ biến như LangChain hoặc LlamaIndex. Cuối cùng, hãy đánh giá khả năng mở rộng và mô hình định giá của nó để đảm bảo nó đáp ứng nhu cầu lâu dài của bạn.
Cơ sở dữ liệu vectorTrường hợp sử dụng
Cung cấp năng lượng cho Chatbot AI bằng Thế hệ tăng cường truy xuất (RAG)
Một nhà phát triển AI được giao nhiệm vụ xây dựng một chatbot hỗ trợ khách hàng phải cung cấp câu trả lời chính xác từ một cơ sở kiến thức riêng, chẳng hạn như hướng dẫn sử dụng sản phẩm và các câu hỏi thường gặp nội bộ. Để đạt được điều này, các tài liệu được phân đoạn, chuyển đổi thành các nhúng vector và được lưu trữ trong một cơ sở dữ liệu vector. Khi người dùng đặt câu hỏi, truy vấn của họ được vector hóa và được sử dụng để tìm kiếm các đoạn tài liệu phù hợp nhất trong cơ sở dữ liệu. Các đoạn được truy xuất này sau đó được chuyển đến một Mô hình Ngôn ngữ Lớn (LLM) làm ngữ cảnh, cho phép chatbot tạo ra các câu trả lời chính xác, nhận biết ngữ cảnh dựa trên dữ liệu độc quyền và giảm đáng kể nguy cơ ảo giác.
Triển khai Tìm kiếm Ngữ nghĩa cho Tài liệu Nội bộ
Một người quản lý kiến thức trong một tập đoàn lớn cần cải thiện cách nhân viên tìm kiếm thông tin qua hàng nghìn báo cáo nội bộ và tài liệu chính sách. Tìm kiếm từ khóa truyền thống không hiệu quả, thường không thể hiển thị nội dung có liên quan về mặt khái niệm. Bằng cách triển khai cơ sở dữ liệu vector, tất cả các tài liệu được vector hóa để nắm bắt ý nghĩa ngữ nghĩa của chúng. Nhân viên giờ đây có thể tìm kiếm bằng các câu hỏi ngôn ngữ tự nhiên. Hệ thống thực hiện tìm kiếm tương đồng để truy xuất tài liệu dựa trên sự liên quan về khái niệm, không chỉ là khớp từ khóa. Điều này giúp cải thiện tốc độ truy xuất thông tin lên đến 80%, thúc đẩy năng suất và chia sẻ kiến thức.
Xây dựng Công cụ Tìm kiếm bằng Hình ảnh cho Thương mại điện tử
Một nhà phát triển thương mại điện tử cho một nhà bán lẻ thời trang trực tuyến muốn tạo ra tính năng 'mua sắm theo phong cách', cho phép khách hàng tìm sản phẩm bằng cách tải lên một hình ảnh. Để thực hiện điều này, toàn bộ danh mục hình ảnh sản phẩm được xử lý bởi một mô hình thị giác để tạo ra các nhúng vector, sau đó được lưu trữ trong một cơ sở dữ liệu vector. Khi người dùng tải lên một hình ảnh, nó cũng được chuyển đổi tương tự thành một vector. Cơ sở dữ liệu sau đó thực hiện tìm kiếm tương đồng tốc độ cao để tìm và hiển thị các hình ảnh sản phẩm có vector gần nhất. Trải nghiệm tìm kiếm trực quan này cải thiện đáng kể việc khám phá sản phẩm và đã được chứng minh là làm tăng tỷ lệ chuyển đổi bằng cách giúp khách hàng tìm thấy các mặt hàng tương tự về mặt hình ảnh ngay lập tức.
Tạo Hệ thống Đề xuất Nội dung Cá nhân hóa
Một nhà khoa học dữ liệu tại một dịch vụ phát trực tuyến phương tiện truyền thông nhằm mục đích tăng cường sự tương tác của người dùng bằng cách cung cấp các đề xuất nội dung có liên quan cao. Họ biểu diễn mỗi mẩu nội dung (ví dụ: phim, bài báo) và hồ sơ của mỗi người dùng dưới dạng các vector đa chiều. Khi người dùng tương tác với nội dung, vector hồ sơ của họ được cập nhật. Một cơ sở dữ liệu vector được sử dụng để thực hiện tìm kiếm tương đồng thời gian thực, tìm kiếm các vector nội dung gần nhất với vector sở thích của người dùng. Điều này cho phép nền tảng cung cấp các đề xuất động, cá nhân hóa thích ứng với sở thích thay đổi của người dùng, dẫn đến thời gian phiên dài hơn và tỷ lệ giữ chân người dùng cao hơn.
Phát hiện Bất thường trong Lưu lượng Mạng An ninh mạng
Một nhà phân tích an ninh mạng cần xác định các mối đe dọa tiềm ẩn trong khối lượng lớn dữ liệu lưu lượng mạng trong thời gian thực. Dữ liệu hoạt động bình thường, chẳng hạn như các mục nhật ký và các gói mạng, được chuyển đổi thành các nhúng vector để thiết lập một cụm cơ sở của hoạt động 'bình thường' trong không gian vector. Một cơ sở dữ liệu vector liên tục nhập dữ liệu mới, chuyển đổi nó thành vector và so sánh với cơ sở này. Bất kỳ điểm dữ liệu nào có vector nằm xa cụm bình thường sẽ ngay lập tức được gắn cờ là bất thường. Cách tiếp cận này cho phép phát hiện nhanh chóng các mối đe dọa zero-day hoặc lỗi hệ thống không khớp với các chữ ký đã biết, cung cấp một lớp bảo mật chủ động quan trọng.
Loại bỏ trùng lặp trong các bộ dữ liệu hình ảnh quy mô lớn
Một kỹ sư học máy đang chuẩn bị một bộ dữ liệu hình ảnh khổng lồ để huấn luyện một mô hình thị giác máy tính. Để đảm bảo chất lượng dữ liệu và ngăn chặn sự thiên vị của mô hình, việc loại bỏ các hình ảnh trùng lặp hoặc gần như trùng lặp là rất quan trọng. Mỗi hình ảnh trong bộ dữ liệu được chuyển đổi thành một nhúng vector và được lập chỉ mục trong một cơ sở dữ liệu vector. Sau đó, kỹ sư chạy một tìm kiếm tương đồng cho mỗi hình ảnh để tìm các hình ảnh khác trong một ngưỡng khoảng cách rất nhỏ. Quá trình này xác định và gắn cờ hiệu quả tất cả các bộ hình ảnh gần như trùng lặp để loại bỏ, dẫn đến một bộ dữ liệu huấn luyện sạch hơn, đa dạng hơn. Điều này cải thiện độ chính xác và khả năng tổng quát hóa của mô hình cuối cùng.