
Browserless
Browserless là một nền tảng Trình duyệt dưới dạng Dịch vụ (BaaS) mạnh mẽ được thiết kế để …
Browserless là một nền tảng Trình duyệt dưới dạng Dịch vụ (BaaS) mạnh mẽ được thiết kế để scraping web và tự động hóa trình duyệt có khả năng mở rộng. Nó giúp các nhà phát triển vượt qua CAPTCHA và các trình phát hiện bot một cách dễ dàng bằng cách sử dụng Puppeteer, Playwright hoặc ngôn ngữ BrowserQL độc quyền của nó. Dịch vụ này quản lý cơ sở hạ tầng trình duyệt, cho phép người dùng tập trung vào việc xây dựng các kịch bản tự động hóa mà không cần lo lắng về việc cập nhật, rò rỉ bộ nhớ hoặc mở rộng quy mô.

Crawlbase
Crawlbase là một nền tảng thu thập dữ liệu web và cào dữ liệu được hỗ trợ bởi …
Crawlbase là một nền tảng thu thập dữ liệu web và cào dữ liệu được hỗ trợ bởi AI dành cho các nhà phát triển và doanh nghiệp. Nó cung cấp một bộ công cụ, bao gồm API Thu thập dữ liệu và Proxy Thông minh, để trích xuất dữ liệu ẩn danh từ bất kỳ trang web nào ở quy mô lớn, vượt qua các rào cản và CAPTCHA với tỷ lệ thành công cao. Nó đơn giản hóa việc thu thập dữ liệu cho SEO, nghiên cứu thị trường, tình báo thương mại điện tử và đào tạo các mô hình AI.

Scrappey
Scrappey là một API cào dữ liệu web tiên tiến được thiết kế để các nhà phát triển …
Scrappey là một API cào dữ liệu web tiên tiến được thiết kế để các nhà phát triển dễ dàng trích xuất dữ liệu từ bất kỳ trang web nào. Nó xử lý tất cả các phức tạp như proxy xoay vòng, trình duyệt không đầu và vượt qua các biện pháp chống bot như Cloudflare và CAPTCHA. Với tỷ lệ thành công cao và mô hình trả tiền theo mức sử dụng đơn giản, Scrappey hợp lý hóa việc thu thập dữ liệu cho các ứng dụng khác nhau.

Apify
Apify là một nền tảng tự động hóa và trích xuất dữ liệu web toàn diện (full-stack) cho …
Apify là một nền tảng tự động hóa và trích xuất dữ liệu web toàn diện (full-stack) cho phép các nhà phát triển xây dựng, triển khai và xuất bản các công cụ trích xuất dữ liệu, được gọi là 'Actors'. Nền tảng này cung cấp một thị trường rộng lớn các công cụ trích xuất dữ liệu dựng sẵn cho các trang web phổ biến như Google Maps, Instagram và TikTok, cùng với một cơ sở hạ tầng đám mây mạnh mẽ để tạo ra các giải pháp tùy chỉnh. Với sự hỗ trợ cho Python và JavaScript, các thư viện mã nguồn mở và tích hợp liền mạch, Apify đơn giản hóa việc thu thập dữ liệu web ở mọi quy mô.

Crawlbase
Crawlbase là một nền tảng cào và thu thập dữ liệu web được hỗ trợ bởi AI, được …
Crawlbase là một nền tảng cào và thu thập dữ liệu web được hỗ trợ bởi AI, được thiết kế cho các nhà phát triển và doanh nghiệp. Nó đơn giản hóa việc trích xuất dữ liệu bằng cách xử lý proxy, CAPTCHA và các hệ thống chống bot, cho phép bạn thu thập dữ liệu ẩn danh từ bất kỳ trang web nào và lấy dữ liệu sạch, có cấu trúc ở quy mô lớn. Nền tảng này cung cấp một bộ công cụ bao gồm API Crawling, Smart Proxy và Cloud Storage.
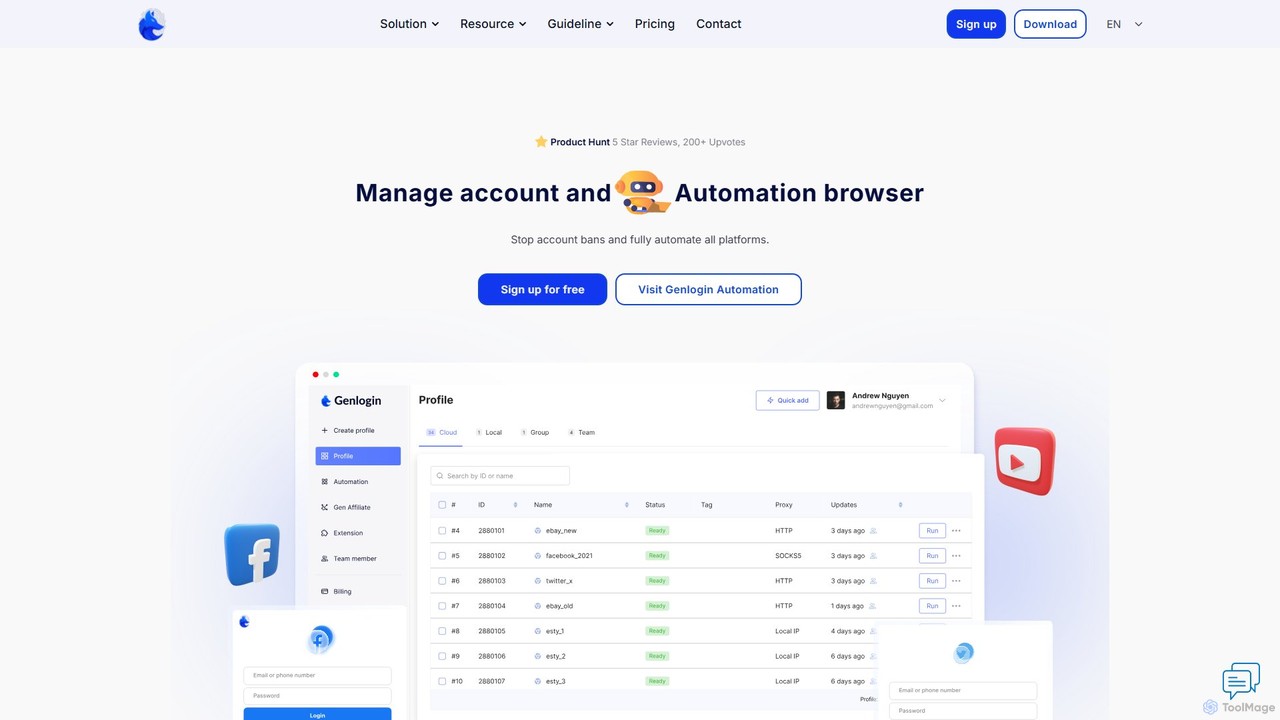
Genlogin
Genlogin là một trình duyệt chống phát hiện tiên tiến được thiết kế để quản lý nhiều tài …
Genlogin là một trình duyệt chống phát hiện tiên tiến được thiết kế để quản lý nhiều tài khoản trực tuyến một cách an toàn và hiệu quả. Nó ngăn chặn việc bị cấm tài khoản bằng cách tạo ra các dấu vân tay trình duyệt độc đáo, dựa trên dữ liệu thực cho mỗi hồ sơ. Với các tính năng như tự động hóa không cần code, đồng bộ hóa hành động thời gian thực và dịch vụ proxy tích hợp, Genlogin là lựa chọn lý tưởng cho thương mại điện tử, tiếp thị truyền thông xã hội, trích xuất dữ liệu và tiếp thị liên kết, giúp người dùng mở rộng quy mô hoạt động trực tuyến của mình.

WebScraping.AI
WebScraping.AI là một API nâng cao dành cho nhà phát triển giúp đơn giản hóa việc cào dữ …
WebScraping.AI là một API nâng cao dành cho nhà phát triển giúp đơn giản hóa việc cào dữ liệu web bằng AI. Nó có các proxy xoay vòng, kết xuất JavaScript và nhắm mục tiêu theo địa lý để vượt qua các rào cản và truy cập nội dung động. Sức mạnh cốt lõi của nó nằm ở các công cụ được hỗ trợ bởi LLM, có thể trích xuất dữ liệu phi cấu trúc, tạo tóm tắt và trả lời câu hỏi trực tiếp từ các trang web, hợp lý hóa việc thu thập dữ liệu cho bất kỳ dự án nào.

FetchFox
FetchFox là một công cụ cào web được hỗ trợ bởi AI cho phép người dùng trích xuất …
FetchFox là một công cụ cào web được hỗ trợ bởi AI cho phép người dùng trích xuất dữ liệu từ bất kỳ trang web nào bằng các lời nhắc văn bản đơn giản. Nó loại bỏ nhu cầu về mã hóa phức tạp hoặc bộ chọn CSS, tự động xử lý các biện pháp chống bot. Có sẵn dưới dạng API, thư viện JavaScript và tiện ích mở rộng Chrome, nó được thiết kế cho cả nhà phát triển và người dùng không chuyên về kỹ thuật để tự động hóa việc thu thập dữ liệu một cách dễ dàng.

CapSolver
CapSolver là một dịch vụ giải CAPTCHA tự động được hỗ trợ bởi AI, được thiết kế cho …
CapSolver là một dịch vụ giải CAPTCHA tự động được hỗ trợ bởi AI, được thiết kế cho các nhà phát triển và chuyên gia RPA. Nó cung cấp một giải pháp có độ chính xác cao, nhanh chóng và có thể mở rộng để vượt qua các loại CAPTCHA khác nhau, bao gồm reCAPTCHA, hCaptcha và FunCaptcha, tạo điều kiện cho việc cào web, trích xuất dữ liệu và tự động hóa quy trình một cách liền mạch.
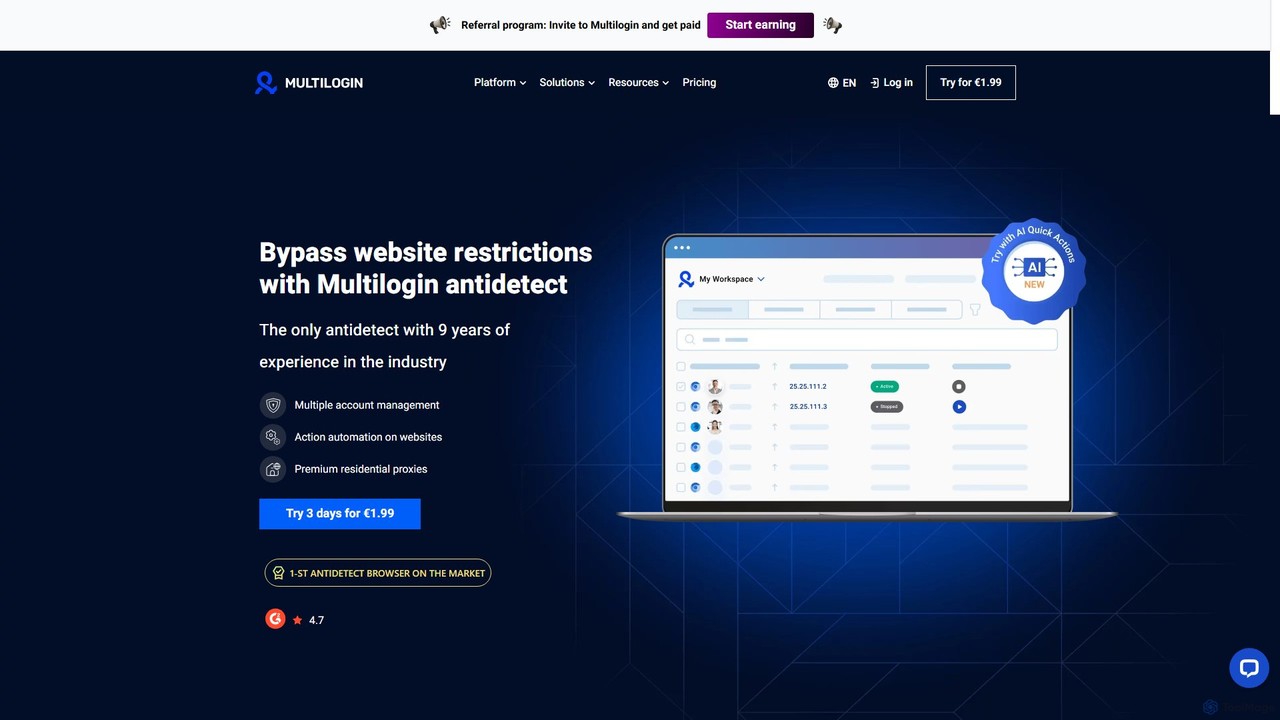
Multilogin
Multilogin là một trình duyệt chống phát hiện hàng đầu cho phép người dùng tạo và quản lý …
Multilogin là một trình duyệt chống phát hiện hàng đầu cho phép người dùng tạo và quản lý nhiều hồ sơ trình duyệt độc đáo. Nó được thiết kế để ngăn chặn các hạn chế của trang web và lệnh cấm tài khoản bằng cách che giấu dấu vân tay kỹ thuật số, lý tưởng cho tiếp thị truyền thông xã hội, thương mại điện tử, web scraping và các hoạt động đa tài khoản khác. Nó bao gồm các tính năng như cộng tác nhóm, hỗ trợ tự động hóa và proxy dân cư tích hợp.
Horseman
Horseman là một trình thu thập dữ liệu web trên máy tính để bàn có khả năng cấu …
Horseman là một trình thu thập dữ liệu web trên máy tính để bàn có khả năng cấu hình vô hạn dành cho các nhà phát triển, chuyên gia SEO và nhà phân tích hiệu suất. Nó tận dụng các đoạn mã JavaScript tùy chỉnh và tích hợp GPT-3.5 để trích xuất, phân tích và thao tác dữ liệu trang web, cung cấp thông tin chuyên sâu trên toàn bộ trang web mà không yêu cầu kiến thức lập trình nâng cao.

ScrapingBee
ScrapingBee là một API cào web mạnh mẽ, xử lý các trình duyệt không đầu và xoay vòng …
ScrapingBee là một API cào web mạnh mẽ, xử lý các trình duyệt không đầu và xoay vòng proxy để tránh bị chặn. Nó có một công cụ trích xuất sáng tạo do AI cung cấp cho phép bạn mô tả dữ liệu bạn cần bằng tiếng Anh đơn giản, loại bỏ nhu cầu về các bộ chọn CSS phức tạp. Lý tưởng cho các nhà phát triển, nhà tiếp thị và nhà phân tích dữ liệu cho các nhiệm vụ như theo dõi giá, tạo khách hàng tiềm năng và phân tích SERP.

PageLlama
PageLlama là một công cụ AI được thiết kế cho các nhà phát triển và nhà nghiên cứu. …
PageLlama là một công cụ AI được thiết kế cho các nhà phát triển và nhà nghiên cứu. Nó dễ dàng chuyển đổi nội dung của bất kỳ trang web nào thành Markdown sạch, có cấu trúc và sẵn sàng cho LLM. Bằng cách loại bỏ sự lộn xộn như quảng cáo và điều hướng, nó cung cấp dữ liệu có độ trung thực cao, tối ưu hóa việc sử dụng token và cải thiện độ chính xác của các ứng dụng AI như hệ thống RAG và mô hình phân tích dữ liệu.
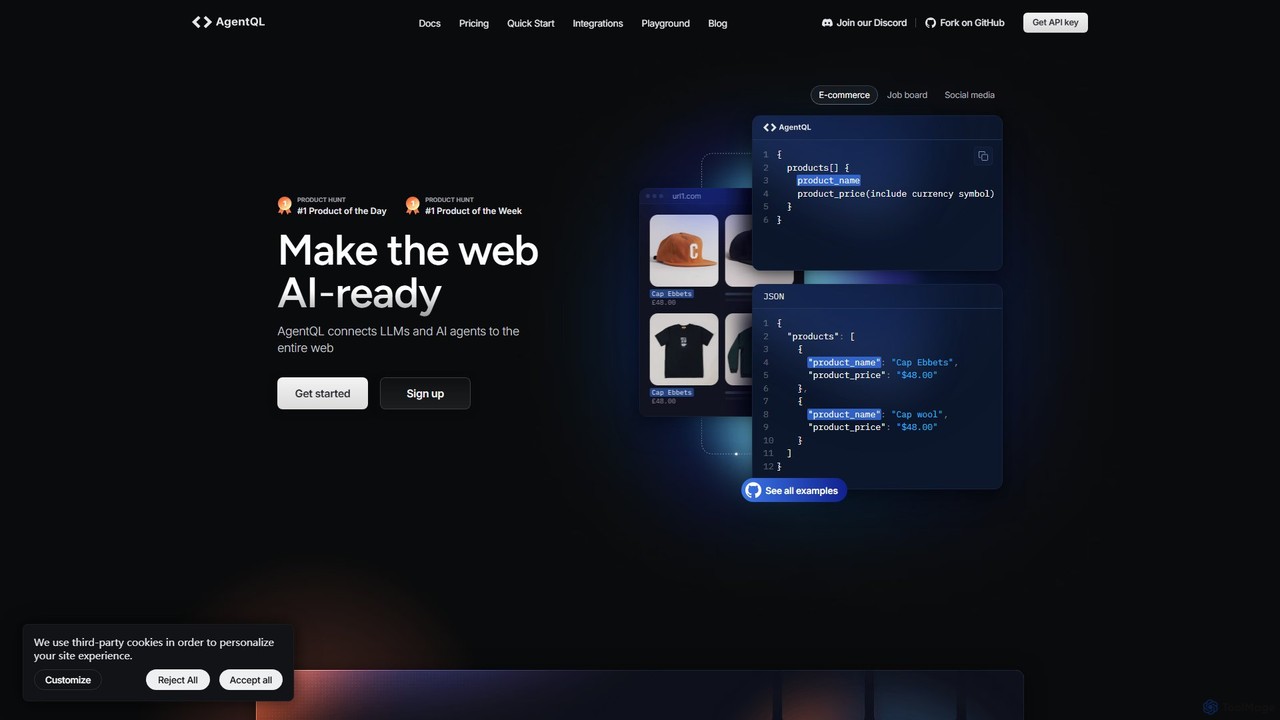
AgentQL
AgentQL là một bộ công cụ dành cho nhà phát triển giúp kết nối LLM và các agent …
AgentQL là một bộ công cụ dành cho nhà phát triển giúp kết nối LLM và các agent AI với web. Nó sử dụng ngôn ngữ truy vấn được hỗ trợ bởi AI để trích xuất dữ liệu có cấu trúc một cách mạnh mẽ và tự động hóa các tương tác web, đóng vai trò là một giải pháp thay thế mạnh mẽ, tự phục hồi cho các bộ chọn XPath và CSS dễ hỏng.
URLtoText
URLtoText là một công cụ hỗ trợ bởi AI giúp trích xuất văn bản sạch, có cấu trúc …
URLtoText là một công cụ hỗ trợ bởi AI giúp trích xuất văn bản sạch, có cấu trúc từ bất kỳ trang web hoặc tệp PDF nào. Nó thông minh loại bỏ quảng cáo, thanh bên và các nội dung lộn xộn khác để chỉ cung cấp nội dung chính. Với tính năng kết xuất JavaScript, proxy IP dân cư và API cho nhà phát triển, nó được thiết kế cho các nhà nghiên cứu, nhà phát triển và doanh nghiệp cần trích xuất dữ liệu đáng tin cậy từ cả trang web tĩnh và động.
Về Web Scraping
Các công cụ Web Scraping là giải pháp được hỗ trợ bởi AI, được thiết kế để tự động trích xuất dữ liệu từ các trang web. Các công cụ này tận dụng các thuật toán tiên tiến, thường kết hợp xử lý ngôn ngữ tự nhiên và học máy, để điều hướng các trang web, xác định và thu thập thông tin có cấu trúc hoặc phi cấu trúc. Chúng rất cần thiết để tự động hóa việc thu thập dữ liệu thủ công tẻ nhạt, cung cấp khả năng thu thập dữ liệu có thể mở rộng và hiệu quả cho các nhu cầu phân tích khác nhau. Khả năng này làm cho chúng trở nên vô giá đối với các doanh nghiệp và nhà nghiên cứu muốn thu thập thông tin chi tiết từ lượng lớn dữ liệu web công khai.
Tính năng cốt lõi
- Trích xuất dữ liệu tự động: Thu thập có hệ thống các điểm dữ liệu cụ thể như văn bản, hình ảnh và liên kết từ các trang web.
- Xử lý nội dung động: Tương tác với nội dung được hiển thị bằng JavaScript, biểu mẫu và phân trang để truy cập tất cả dữ liệu liên quan.
- Vượt qua chống Scraping: Sử dụng các kỹ thuật để vượt qua các biện pháp chống bot phổ biến như CAPTCHA và chặn IP.
- Cấu trúc và xuất dữ liệu: Tổ chức dữ liệu đã trích xuất thành các định dạng có thể sử dụng như CSV, JSON hoặc XML để dễ dàng phân tích và tích hợp.
- Lập lịch và giám sát: Cho phép người dùng lên lịch các tác vụ scraping và giám sát các trang web để tìm thông tin mới hoặc cập nhật.
Các trường hợp ứng dụng
Các công cụ web scraping được sử dụng rộng rãi trong việc thu thập thông tin thị trường cho các doanh nghiệp, cho phép họ theo dõi giá cả và thông tin sản phẩm của đối thủ cạnh tranh trong thời gian thực. Chúng cũng rất quan trọng đối với các nhà nghiên cứu học thuật thu thập các bộ dữ liệu lớn từ các nguồn công khai để phân tích thống kê. Các nền tảng thương mại điện tử sử dụng các công cụ này để theo dõi giá cả và tồn kho theo thời gian thực trên nhiều nhà bán lẻ trực tuyến khác nhau.
Cách chọn
Khi chọn một công cụ web scraping, hãy xem xét khả năng xử lý độ phức tạp của các trang web mục tiêu, bao gồm nội dung động và các biện pháp chống scraping. Đánh giá khả năng mở rộng và lập lịch của nó dựa trên khối lượng và tần suất dữ liệu yêu cầu. Đánh giá mức độ dễ sử dụng, cho dù thông qua giao diện không mã hóa hay API mạnh mẽ dành cho nhà phát triển. Cuối cùng, đảm bảo công cụ hỗ trợ các thực hành scraping có đạo đức và tuân thủ các quy định về quyền riêng tư dữ liệu.
Web ScrapingTrường hợp sử dụng
Giám sát giá cạnh tranh cho thương mại điện tử
Các doanh nghiệp thương mại điện tử sử dụng các công cụ web scraping để liên tục giám sát giá của đối thủ cạnh tranh trên các nền tảng trực tuyến khác nhau. Điều này cho phép họ theo dõi sự thay đổi giá, xác định các ưu đãi khuyến mãi và điều chỉnh chiến lược giá của riêng mình theo thời gian thực để duy trì tính cạnh tranh. Bằng cách tự động hóa quy trình này, các doanh nghiệp có thể tiết kiệm đáng kể công sức thủ công và đảm bảo các sản phẩm của họ luôn được định giá tối ưu, dẫn đến tăng doanh số và thị phần.
Tạo khách hàng tiềm năng và thông tin tình báo bán hàng
Các nhóm bán hàng và tiếp thị tận dụng web scraping để trích xuất thông tin khách hàng tiềm năng có giá trị từ các thư mục công khai, trang web mạng lưới chuyên nghiệp hoặc cổng thông tin chuyên ngành. Điều này bao gồm chi tiết liên hệ, hồ sơ công ty và chức danh công việc, sau đó được sử dụng để xây dựng danh sách khách hàng tiềm năng mục tiêu. Tự động hóa việc tạo khách hàng tiềm năng giúp giảm đáng kể thời gian dành cho việc nhập dữ liệu thủ công, cho phép các chuyên gia bán hàng tập trung vào tương tác và chuyển đổi, từ đó cải thiện hiệu quả quy trình bán hàng.
Nghiên cứu thị trường và phân tích xu hướng
Các nhà nghiên cứu và phân tích sử dụng web scraping để thu thập lượng lớn dữ liệu công khai từ các bài báo, diễn đàn, mạng xã hội và trang web đánh giá. Dữ liệu này sau đó được xử lý để phân tích cảm xúc, xác định xu hướng và thông tin tình báo cạnh tranh. Bằng cách tự động hóa việc thu thập dữ liệu, họ có thể nhanh chóng có được thông tin cập nhật về ý kiến người tiêu dùng, xu hướng thị trường mới nổi và nhận thức của công chúng về thương hiệu hoặc sản phẩm, cho phép đưa ra các quyết định chiến lược sáng suốt hơn.
Tổng hợp nội dung cho cổng thông tin tức
Các công ty truyền thông và công cụ tổng hợp tin tức sử dụng các công cụ web scraping để tự động thu thập các bài báo, tiêu đề, hình ảnh và video từ nhiều nguồn tin tức và blog khác nhau. Điều này cho phép họ điền vào các nguồn cấp tin tức hoặc nền tảng nội dung của riêng mình với nội dung mới mẻ, đa dạng mà không cần tuyển chọn thủ công. Tự động hóa đảm bảo luồng thông tin liên tục, giữ cho khán giả của họ tương tác và được thông báo, đồng thời giảm đáng kể khối lượng công việc biên tập.
Phân tích danh sách bất động sản
Các chuyên gia và nhà đầu tư bất động sản sử dụng web scraping để thu thập danh sách tài sản từ nhiều nền tảng trực tuyến, bao gồm các cổng thông tin bất động sản và rao vặt. Dữ liệu tổng hợp này cho phép phân tích thị trường toàn diện, xác định xu hướng về giá trị tài sản, tỷ lệ thuê và tính khả dụng trên các khu vực khác nhau. Bằng cách tự động hóa việc thu thập dữ liệu này, họ có thể đưa ra các quyết định nhanh hơn, sáng suốt hơn về việc mua lại, bán và chiến lược đầu tư tài sản, giành được lợi thế cạnh tranh.
Thu thập dữ liệu nghiên cứu học thuật
Các học giả và nhà nghiên cứu thường xuyên sử dụng web scraping để xây dựng các bộ dữ liệu lớn cho các nghiên cứu của họ. Điều này liên quan đến việc trích xuất thông tin từ các ấn phẩm khoa học, cơ sở dữ liệu chính phủ, kho lưu trữ công cộng và các diễn đàn chuyên biệt. Khả năng nhanh chóng thu thập và cấu trúc lượng lớn dữ liệu từ các nguồn trực tuyến đa dạng là rất quan trọng cho nghiên cứu thực nghiệm, phân tích thống kê và xác nhận giả thuyết, giúp tăng tốc đáng kể quá trình nghiên cứu và mang lại những hiểu biết sâu sắc hơn.