Diffbot
Truy cập trang web chính thức
Diffbot Tổng quan
Diffbot cung cấp một bộ công cụ do AI cung cấp được thiết kế để hiểu và cấu trúc nội dung của trang web công cộng, biến nó một cách hiệu quả thành cơ sở dữ liệu lớn nhất và toàn diện nhất thế giới. Cốt lõi của nó là Đồ thị tri thức Diffbot, một kho lưu trữ dữ liệu khổng lồ, được kết nối với nhau về các tổ chức, con người, bài báo, sản phẩm, v.v. Không giống như các trình thu thập dữ liệu web truyền thống yêu cầu các quy tắc thủ công cho mỗi trang web, Diffbot sử dụng thị giác máy tính và xử lý ngôn ngữ tự nhiên để tự động diễn giải các trang web như con người, trích xuất dữ liệu có cấu trúc mà không cần cấu hình dành riêng cho trang web.
Công nghệ này cho phép các nhà phát triển và doanh nghiệp ngừng vật lộn với bản chất ồn ào, hỗn loạn của dữ liệu web và thay vào đó truy cập nó như thể nó là một cơ sở dữ liệu sạch, có cấu trúc. Cho dù bạn cần theo dõi tin tức, làm phong phú hồ sơ khách hàng, tiến hành nghiên cứu thị trường hay cung cấp năng lượng cho mô hình học máy, Diffbot đều cung cấp các nguồn cấp dữ liệu sạch, đáng tin cậy cần thiết để xây dựng các ứng dụng thông minh.
Cách sử dụng Diffbot
Bắt đầu với Diffbot được thiết kế đơn giản cho các nhà phát triển và nhóm dữ liệu. Tương tác chính là thông qua các API mạnh mẽ của nó.
- Đăng ký: Bắt đầu bằng cách tạo một tài khoản. Diffbot cung cấp gói miễn phí với 10.000 tín dụng và quyền truy cập API đầy đủ, cho phép bạn kiểm tra khả năng của nền tảng mà không cần thẻ tín dụng.
- Nhận mã thông báo API của bạn: Sau khi đăng ký, bạn sẽ nhận được mã thông báo API từ bảng điều khiển của mình. Mã thông báo này được sử dụng để xác thực tất cả các yêu cầu của bạn đến các API của Diffbot.
- Chọn API phù hợp: Diffbot cung cấp một số API riêng biệt cho các tác vụ khác nhau:
- API trích xuất (Extract): Hướng nó vào bất kỳ URL nào (như một bài báo, trang sản phẩm hoặc cuộc thảo luận trên diễn đàn), và nó sẽ tự động trả về dữ liệu JSON có cấu trúc. Không cần quy tắc.
- API thu thập thông tin (Crawl): Cung cấp một URL bắt đầu và Diffbot sẽ thu thập thông tin toàn bộ trang web một cách có hệ thống, sử dụng API trích xuất để biến mọi trang có liên quan thành dữ liệu có cấu trúc. Điều này lý tưởng để xây dựng cơ sở dữ liệu từ một trang web cụ thể.
- API tìm kiếm đồ thị tri thức (Knowledge Graph Search): Truy vấn Đồ thị tri thức được xây dựng sẵn để tìm thông tin về hơn 246 triệu tổ chức, 1,6 tỷ bài báo, v.v. Bạn có thể tìm kiếm các thực thể và xây dựng các nguồn cấp dữ liệu chính xác.
- API nâng cao đồ thị tri thức (Knowledge Graph Enhance): Cung cấp dữ liệu của riêng bạn (ví dụ: tên công ty) và Diffbot sẽ làm phong phú nó bằng dữ liệu toàn diện từ Đồ thị tri thức, chẳng hạn như doanh thu, số lượng nhân viên, hồ sơ xã hội và tin tức gần đây.
- API ngôn ngữ tự nhiên (Natural Language): Gửi văn bản thô để suy ra các thực thể, mối quan hệ giữa chúng và thực hiện phân tích tình cảm.
- Tích hợp và xây dựng: Sử dụng các phản hồi API (ở định dạng JSON) để cung cấp năng lượng cho các ứng dụng của bạn, điền vào cơ sở dữ liệu của bạn hoặc cung cấp dữ liệu cho bảng điều khiển phân tích của bạn. Đối với các nhu cầu thời gian thực, bạn có thể thiết lập webhook để nhận thông báo tức thì, chẳng hạn như các bài báo mới đề cập đến một công ty cụ thể.
Tính năng chính của Diffbot
- Đồ thị tri thức: Một đồ thị khổng lồ, được thu thập trước và liên tục cập nhật của web, chứa thông tin có cấu trúc về các tổ chức, con người, sản phẩm, bài báo và mối quan hệ của chúng.
- Trích xuất tự động: Công nghệ do AI điều khiển tự động xác định và trích xuất thông tin chính từ các loại trang khác nhau (bài báo, sản phẩm, thảo luận, v.v.) mà không cần thiết lập hoặc quy tắc thủ công.
- Crawlbot: Một trình thu thập thông tin web thông minh có thể biến toàn bộ một trang web thành một cơ sở dữ liệu có cấu trúc, tự động xác định và trích xuất nội dung từ các trang có liên quan.
- Xử lý ngôn ngữ tự nhiên (NLP): Khả năng NLP nâng cao để hiểu văn bản bằng hơn 20 ngôn ngữ, thực hiện nhận dạng thực thể (phân biệt công ty 'Apple' với quả 'táo') và tiến hành phân tích tình cảm ở cấp độ chủ đề.
- Làm giàu dữ liệu (API Enhance): Khả năng lấy một mẩu thông tin tối thiểu, như tên công ty hoặc email, và làm phong phú nó với hàng tá điểm dữ liệu từ Đồ thị tri thức.
- Giám sát thời gian thực: Xây dựng các nguồn cấp dữ liệu tùy chỉnh, không nhiễu cho tin tức và các đề cập thương hiệu với các cảnh báo thời gian thực qua email hoặc webhook.
Các trường hợp sử dụng Diffbot
Dữ liệu có cấu trúc của Diffbot có giá trị trên nhiều ngành và chức năng:
- Tình báo thị trường: Theo dõi đối thủ cạnh tranh, giám sát xu hướng ngành và phân tích các chuyển động của thị trường bằng cách khai thác tin tức toàn cầu, hồ sơ công ty và dữ liệu sản phẩm.
- Rủi ro & Tuân thủ: Thực hiện thẩm định đối với các công ty và cá nhân, giám sát chuỗi cung ứng để tìm tín hiệu rủi ro và đi trước các thay đổi quy định.
- Bán hàng & Tiếp thị: Làm phong phú dữ liệu khách hàng tiềm năng trong CRM, xác định khách hàng tiềm năng mới dựa trên các tiêu chí cụ thể (ví dụ: các công ty trong một ngành nhất định vừa nhận được tài trợ) và cá nhân hóa việc tiếp cận.
- Giám sát tin tức & Truyền thông: Tạo các nguồn cấp tin tức thời gian thực, rất cụ thể theo dõi các đề cập đến thương hiệu, con người hoặc chủ đề với sự đối sánh thực thể chính xác và phân tích tình cảm.
- Tuyển dụng: Xây dựng cơ sở dữ liệu về các ứng cử viên tiềm năng, xác định nhân tài và làm phong phú hồ sơ chuyên môn bằng dữ liệu từ khắp nơi trên web.
- Học máy: Sử dụng Đồ thị tri thức làm nguồn dữ liệu đào tạo có cấu trúc, chất lượng cao cho các mô hình AI và học máy khác nhau.
Ưu điểm của Diffbot
Ưu điểm chính của Diffbot là khả năng coi toàn bộ web như một cơ sở dữ liệu duy nhất có thể truy vấn. Nó trừu tượng hóa sự phức tạp của việc thu thập dữ liệu web và làm sạch dữ liệu. Các lợi ích chính bao gồm độ chính xác, quy mô và hiệu quả. Thay vì xây dựng và duy trì các trình thu thập dữ liệu dễ hỏng, dành riêng cho trang web, người dùng có thể dựa vào một API duy nhất, mạnh mẽ. NLP nhận biết thực thể đảm bảo chất lượng và sự liên quan của dữ liệu, trong khi Đồ thị tri thức được xây dựng sẵn cung cấp quyền truy cập ngay lập tức vào một bộ dữ liệu khổng lồ mà sẽ mất nhiều năm để xây dựng trong nội bộ.
Giá cả và gói dịch vụ
Diffbot cung cấp một cấu trúc giá theo cấp để đáp ứng các mức độ sử dụng khác nhau, từ các dự án sở thích đến các doanh nghiệp lớn.
- Gói miễn phí: $0/tháng. Bao gồm 10.000 tín dụng, quyền truy cập API đầy đủ và miễn phí mãi mãi. Lý tưởng để thử nghiệm và các dự án nhỏ.
- Gói khởi nghiệp: $299/tháng. Bao gồm 250.000 tín dụng và được thiết kế cho các nhóm nhỏ cần thu thập dữ liệu plug-and-play và truy cập Đồ thị tri thức.
- Gói Plus: $899/tháng. Bao gồm 1.000.000 tín dụng, quyền truy cập vào sản phẩm Crawl và tốc độ gọi API cao hơn. Phù hợp cho các doanh nghiệp đang phát triển có nhu cầu dữ liệu lớn hơn.
- Gói doanh nghiệp: Giá tùy chỉnh. Cung cấp các gói riêng biệt với phân bổ tín dụng tùy chỉnh, tốc độ gọi API cao nhất, hỗ trợ SLA cao cấp và các giải pháp được quản lý cho các hoạt động dữ liệu quy mô lớn.
Tín dụng được tiêu thụ dựa trên loại và độ phức tạp của lệnh gọi API. Phân tích chi tiết có sẵn trên trang web của họ.
Diffbot Bình luận (0)
Đăng nhập để bình luận
Đăng nhập ngayDiffbotPhân tích lưu lượng truy cập website
Tình hình lưu lượng truy cập mới nhất
Trạng thái
Xu hướng lưu lượng truy cập hàng tháng
Vị trí địa lý
Top 5 Quốc gia/Khu vực
-
🇺🇸 United States36,36%
-
🇮🇳 India28,03%
-
🇳🇬 Nigeria14,97%
-
🇨🇦 Canada10,37%
-
🇩🇪 Germany10,27%
Nguồn truy cập
| Loại nguồn | Phần trăm |
|---|---|
|
Truy cập trực tiếp
|
93,32% |
|
Giới thiệu
|
6,03% |
|
Email
|
0,65% |
Từ khóa phổ biến
| Từ khóa | Chi phí mỗi lượt nhấp |
|---|---|
|
$0,00
|
|
|
$4,94
|
|
|
$0,00
|
|
|
$0,00
|
|
|
$0,00
|
Diffbot Các lựa chọn thay thế
Xem tất cả
Oxylabs
Oxylabs là nhà cung cấp hàng đầu về dịch vụ proxy cao cấp và các giải pháp thu …
Oxylabs là nhà cung cấp hàng đầu về dịch vụ proxy cao cấp và các giải pháp thu thập dữ liệu web cấp doanh nghiệp. Tận dụng mạng lưới proxy khổng lồ được cung cấp một cách có đạo đức với hơn 177 triệu IP, Oxylabs cung cấp các API Scraper được hỗ trợ bởi AI, Trình mở khóa web và AI Studio mới để trích xuất dữ liệu bằng ngôn ngữ tự nhiên. Nó cho phép các doanh nghiệp thu thập dữ liệu web công khai ở quy mô lớn cho thương mại điện tử, an ninh mạng, bảo vệ thương hiệu và nghiên cứu thị trường mà không bị chặn.
SingleAPI
SingleAPI là một công cụ được hỗ trợ bởi GPT-4, có khả năng chuyển đổi tức thì bất …
SingleAPI là một công cụ được hỗ trợ bởi GPT-4, có khả năng chuyển đổi tức thì bất kỳ trang web nào thành một API JSON có cấu trúc. Nó đơn giản hóa việc cào web, trích xuất dữ liệu và làm giàu dữ liệu mà không cần viết bất kỳ mã lệnh hay bộ chọn nào, cho phép người dùng dễ dàng truy cập dữ liệu web cho các ứng dụng khác nhau.
Import.io
Import.io là một nền tảng trích xuất dữ liệu web cấp doanh nghiệp, cung cấp dữ liệu có …
Import.io là một nền tảng trích xuất dữ liệu web cấp doanh nghiệp, cung cấp dữ liệu có cấu trúc, chất lượng cao từ bất kỳ trang web nào. Nền tảng này cung cấp cả dịch vụ được quản lý hoàn toàn và giải pháp tự phục vụ để cung cấp thông tin tình báo thị trường thương mại điện tử, giám sát thương hiệu và ra quyết định kinh doanh dựa trên dữ liệu, vượt qua các công nghệ chống cào dữ liệu phức tạp.
Hyperbrowser
Hyperbrowser là một nền tảng Trình duyệt dưới dạng Dịch vụ (BaaS) được thiết kế cho các tác …
Hyperbrowser là một nền tảng Trình duyệt dưới dạng Dịch vụ (BaaS) được thiết kế cho các tác nhân AI và nhà phát triển. Nó cung cấp các trình duyệt đám mây có khả năng mở rộng, tốc độ cực nhanh để tự động hóa các tác vụ web, trích xuất dữ liệu và cho phép các tương tác web do AI điều khiển. Với các tính năng như duyệt web ẩn danh, giải captcha tự động và API thân thiện với nhà phát triển, nó trao quyền cho các quy trình công việc phức tạp mà không có giới hạn.
Simplescraper
Simplescraper là một công cụ cào web mạnh mẽ giúp trích xuất dữ liệu từ bất kỳ trang …
Simplescraper là một công cụ cào web mạnh mẽ giúp trích xuất dữ liệu từ bất kỳ trang web nào trong vài giây. Nó cung cấp một tiện ích mở rộng Chrome thân thiện với người dùng để chọn dữ liệu không cần mã, tự động hóa dựa trên đám mây để cào dữ liệu quy mô lớn và tính năng AI Enhance sáng tạo để lấy thông tin chi tiết bằng các câu lệnh đơn giản. Biến các trang web thành dữ liệu có cấu trúc (CSV, JSON) hoặc API tức thì và tích hợp với các công cụ như Google Sheets và Airtable.
Nimbleway
Nimbleway là một nền tảng cấp doanh nghiệp để thu thập dữ liệu web do AI điều khiển …
Nimbleway là một nền tảng cấp doanh nghiệp để thu thập dữ liệu web do AI điều khiển và các đường ống dữ liệu có thể mở rộng. Nó trao quyền cho các doanh nghiệp tương tác với dữ liệu web thời gian thực, cung cấp các công cụ như tìm kiếm web đại lý, đám mây kiến thức trực tuyến và SDK mạnh mẽ. Lý tưởng cho bán lẻ, tài chính và AI, nó cung cấp dữ liệu có cấu trúc, siêu chi tiết để phân tích cạnh tranh, theo dõi giá và cung cấp dữ liệu cho LLM, đảm bảo việc thu thập dữ liệu có đạo đức và tuân thủ.
Kadoa
Kadoa là một nền tảng cào web không cần mã, được hỗ trợ bởi AI, tự động hóa …
Kadoa là một nền tảng cào web không cần mã, được hỗ trợ bởi AI, tự động hóa việc trích xuất dữ liệu từ bất kỳ trang web hoặc tài liệu nào. Nó cho phép người dùng xây dựng các đường ống dữ liệu có khả năng mở rộng, tự phục hồi trong vài phút, loại bỏ các nút thắt kỹ thuật và cung cấp thông tin chi tiết theo thời gian thực cho tài chính, bán lẻ và tình báo thị trường.
Zyte
Zyte là một nền tảng web scraping toàn diện cung cấp API full-stack và dịch vụ trích xuất …
Zyte là một nền tảng web scraping toàn diện cung cấp API full-stack và dịch vụ trích xuất dữ liệu. Nó đơn giản hóa việc thu thập dữ liệu bằng cách quản lý proxy, trình duyệt không đầu và các hệ thống chống chặn tiên tiến. Được hỗ trợ bởi AI, Zyte cung cấp dữ liệu web đáng tin cậy, có cấu trúc ở quy mô lớn cho các doanh nghiệp trong lĩnh vực thương mại điện tử, nghiên cứu thị trường, v.v.
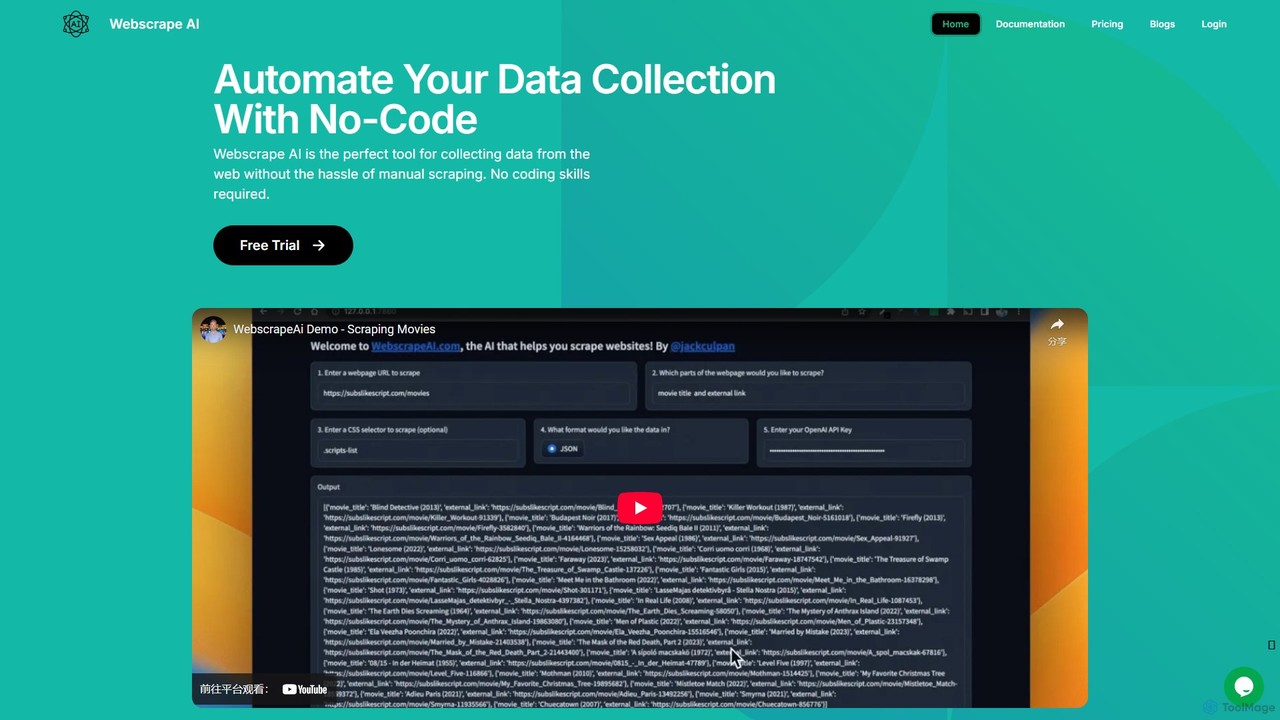
webscrapeai
WebscrapeAI là một nền tảng không cần mã, được hỗ trợ bởi AI, được thiết kế để tự …
WebscrapeAI là một nền tảng không cần mã, được hỗ trợ bởi AI, được thiết kế để tự động hóa việc thu thập dữ liệu web. Chỉ cần cung cấp URL và chỉ định dữ liệu bạn cần, AI sẽ xử lý toàn bộ quá trình cào dữ liệu. Nó hỗ trợ các trang web động, cào hàng loạt, tích hợp proxy và cung cấp API cho nhà phát triển, giúp việc trích xuất dữ liệu nhanh chóng, chính xác và dễ tiếp cận với mọi người.
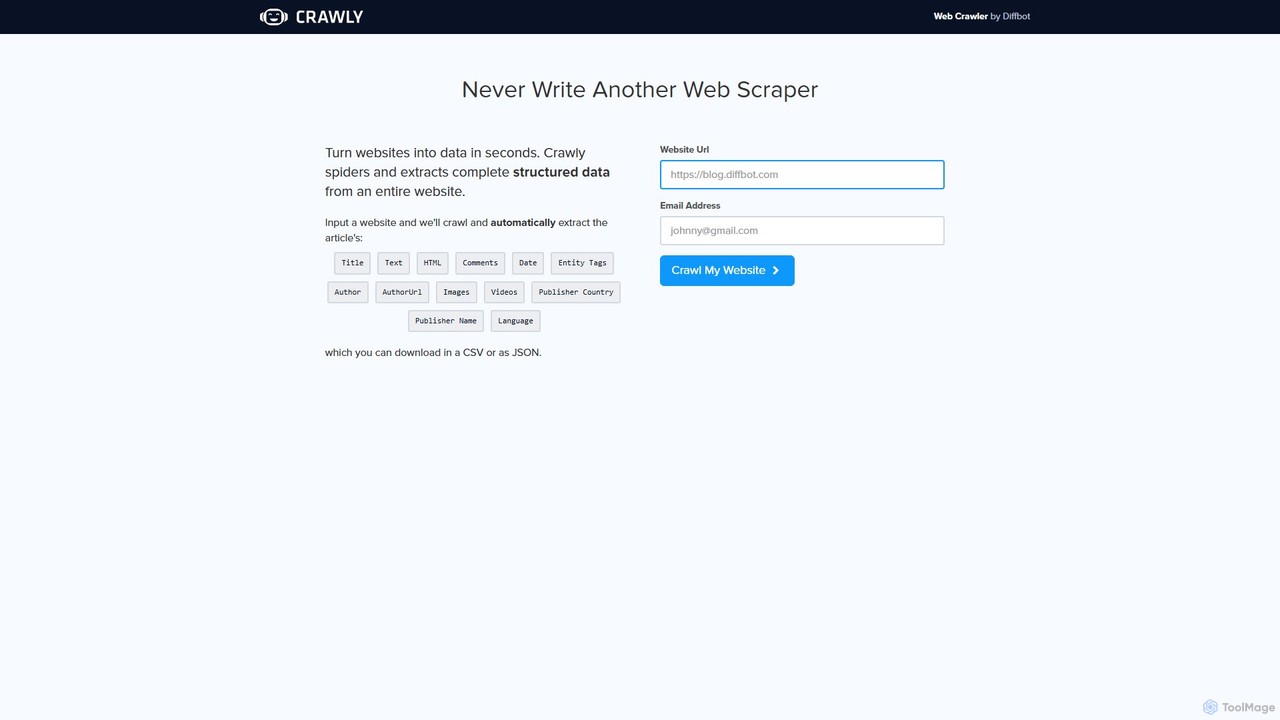
Crawly
Crawly là một trình thu thập thông tin web do AI cung cấp bởi Diffbot, tự động trích …
Crawly là một trình thu thập thông tin web do AI cung cấp bởi Diffbot, tự động trích xuất dữ liệu có cấu trúc từ toàn bộ trang web. Chỉ cần nhập URL, Crawly sẽ quét trang web để lấy thông tin chính như bài viết, sản phẩm và thảo luận, chuyển đổi chúng thành dữ liệu JSON hoặc CSV sạch mà không cần viết mã.
Diffbot Danh mục
Diffbot Thẻ
Diffbot Công cụ AI
Diffbot Tính năng nhúng
Chỉ cần sao chép mã nhúng bên dưới, dán huy hiệu đẹp mắt vào blog, bài viết hoặc trang web chính thức của ứng dụng để hướng lưu lượng truy cập trực tiếp đến trang chi tiết của công cụ này, giúp nhanh chóng tăng độ hiển thị và số lượng người dùng!

Chưa có bình luận nào, hãy là người đầu tiên bình luận!