
The Foundry AI
The Foundry AI 是一个专为构建 AI 网络代理的开发者设计的平台。它提供了一个确定性的网络模拟器和先进的标注框架,用于在可复现的环境中测试、基准测试和调试代理,摆脱了真实网络不可预测性的困扰。
The Foundry AI 是一个专为构建 AI 网络代理的开发者设计的平台。它提供了一个确定性的网络模拟器和先进的标注框架,用于在可复现的环境中测试、基准测试和调试代理,摆脱了真实网络不可预测性的困扰。
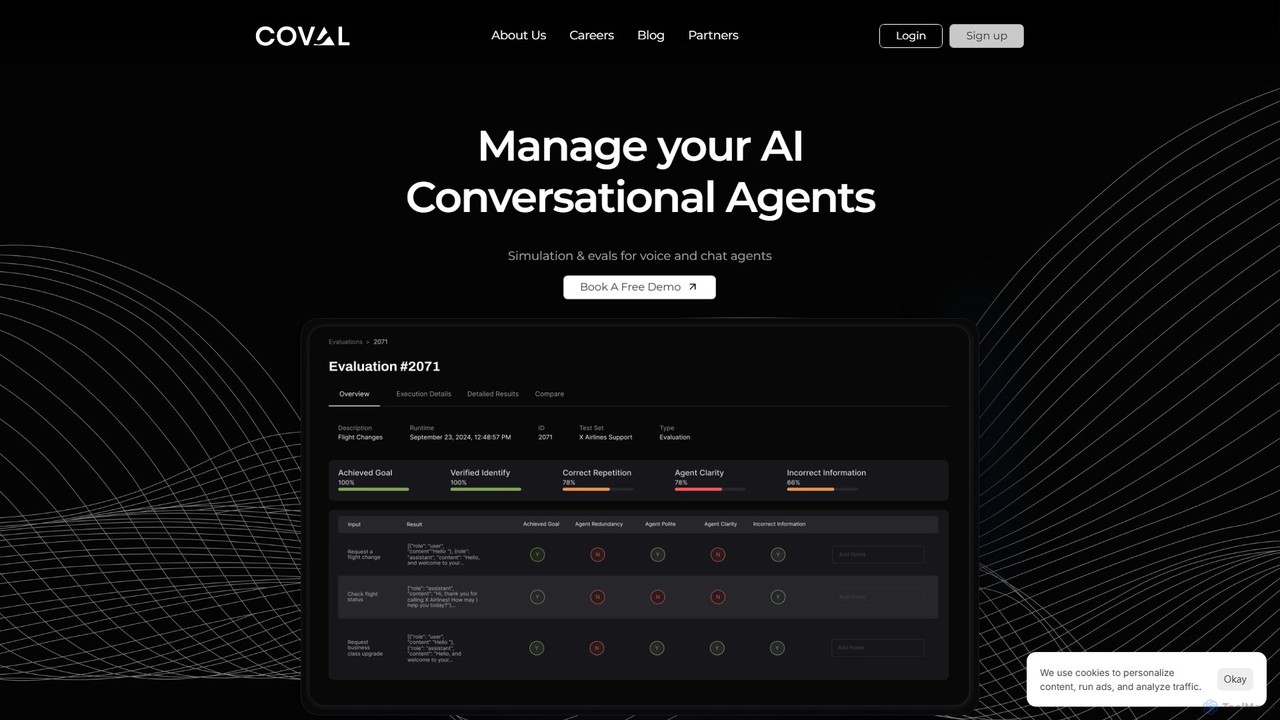
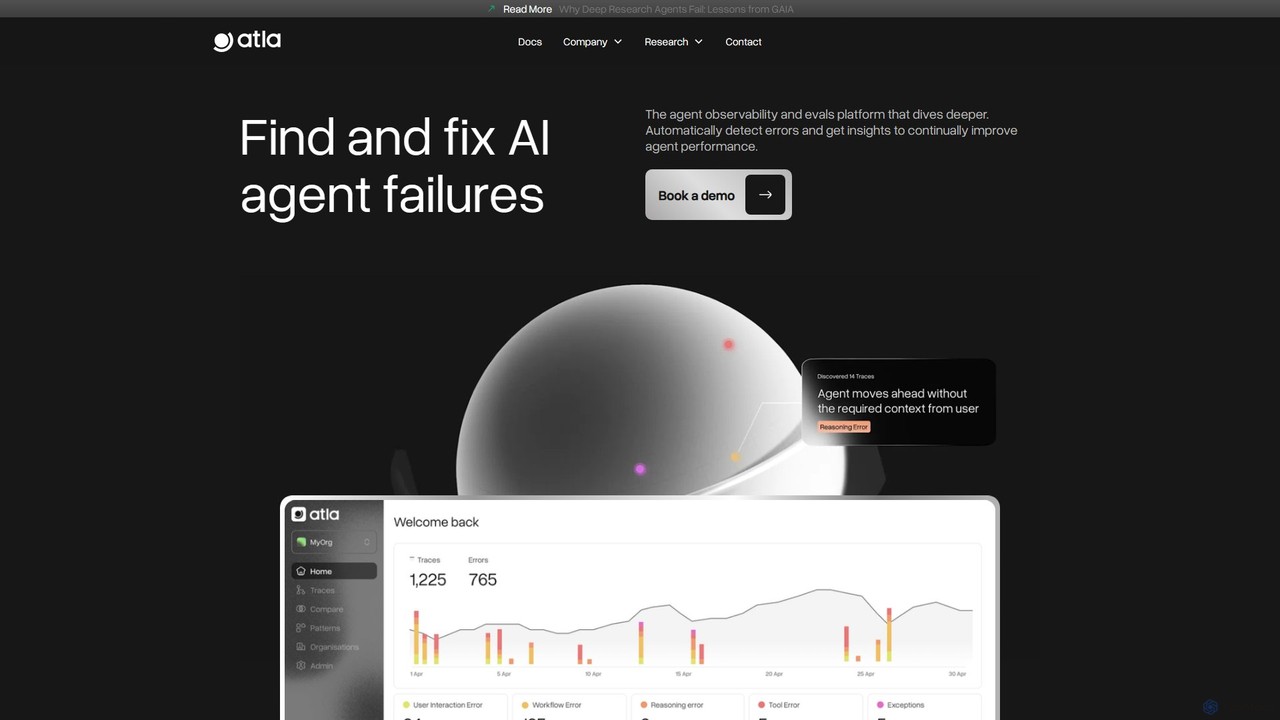
关于 模型评估
模型评估工具是一类专业的AI基础设施,旨在系统性地评测机器学习模型的性能、公平性和可靠性。这些平台能够自动计算准确率、精确率和召回率等关键指标,同时提供偏见检测、可解释性分析和鲁棒性测试等高级功能。其核心价值在于提供客观、数据驱动的洞察,帮助开发者选择性能最佳的模型,确保AI实践的合乎道德,并验证模型是否为生产环境就绪。这种严谨的评估是MLOps生命周期中的关键一步,确保部署的模型高效、可信并与业务目标保持一致。
核心功能
- 性能指标追踪:自动计算并可视化分类(准确率、F1分数、AUC)和回归(MSE、MAE、R²)任务的标准指标。
- 偏见与公平性审计:识别模型在不同人口子群体间的性能差异,以检测并缓解预测中潜在的偏见。
- 可解释性 (XAI) 分析:使用SHAP、LIME等技术生成对模型决策的洞察,提高黑箱模型的透明度。
- 鲁棒性与压力测试:评估模型在面对对抗性攻击、数据漂移和边缘案例时的稳定性,确保其在真实世界中的可靠表现。
- 模型比较与版本控制:提供一个框架,用于在标准化数据集上并排比较多个模型或同一模型的不同版本。
适用场景
模型评估工具对于数据科学家、机器学习工程师和MLOps团队至关重要,尤其是在金融、医疗和保险等受监管行业。它们在开发周期中用于基准测试和选择候选模型,在部署前检查中用于验证合规性和公平性,以及用于对线上模型进行定期审计,以确保持续的性能和可靠性。
选择要点
选择模型评估工具时,应考虑其与您的机器学习框架(如TensorFlow、PyTorch、Scikit-learn)的兼容性。评估其功能的广度——是否涵盖性能、公平性和可解释性。考察其与现有MLOps技术栈(如实验跟踪器和模型注册中心)的集成能力。最后,还需考量其可视化和报告功能的质量,以便向技术和非技术相关方清晰地传达结果。
模型评估应用场景
审计金融模型的公平性
一家金融机构的数据科学家负责确保新的信用评分模型不会歧视受保护的人口群体。通过使用模型评估工具,他们上传模型在测试数据集上的预测结果。该工具会自动生成一份公平性报告,突出显示不同性别和种族之间的假正率等性能指标。通过分析这些结果,科学家可以在模型部署前识别并缓解偏见,确保遵守公平借贷法规,并降低声誉风险。
比较计算机视觉模型的不同架构
一位机器学习工程师正在为移动应用开发图像分类功能,需要在三种不同的模型架构(如ResNet、MobileNet、Vision Transformer)之间做出选择。他使用一个模型评估平台,在相同的验证数据集上运行这三个模型。该平台提供了一个并排比较的仪表板,显示了每个模型的准确率、F1分数、推理延迟和模型大小。这种全面的视图使工程师能够进行权衡决策,选择在准确性和设备端性能之间达到最佳平衡的模型。
为医疗诊断生成可解释性报告
在医疗场景中,放射科医生使用一个AI模型来检测医学扫描图像中的异常。为了建立信任并辅助诊断,他们使用模型评估工具中的可解释性(XAI)功能。当模型标记出潜在问题时,该工具会生成一个热力图(如SHAP或LIME可视化)叠加在原始扫描图像上。这个热力图会高亮显示对模型决策影响最大的特定像素和区域。这使得放射科医生能够根据自己的专业知识快速验证AI的推理过程,从而做出更自信、更透明的临床决策。
对自动驾驶感知模型进行压力测试
一个汽车工程团队需要确保自动驾驶汽车中的感知模型极其可靠。他们使用模型评估工具的鲁棒性测试模块来模拟恶劣条件。这包括通过编程方式向测试图像中添加数字噪声、雾和雨,并运行对抗性攻击以找到模型的盲点。该工具会报告模型在每种条件下准确率下降的程度。这种严格的压力测试帮助团队识别弱点并加固模型以应对现实世界的挑战,这是确保安全的关键一步。
为客服聊天机器人基准测试NLP模型
一位AI聊天机器人的产品经理希望升级其底层的自然语言处理(NLP)模型。团队已经筛选出两个新模型。他们使用一个模型评估套件,在一个包含历史客户对话的“黄金数据集”上,对这两个新模型和当前模型进行基准测试。评估工具测量了意图识别准确率、实体提取F1分数和响应相关性。结果以排行榜的形式显示,让产品经理能够清楚地看到哪个模型在他们的特定数据上表现最好,并为升级做出有数据支持的决策。
为满足监管合规性验证模型行为
一家保险公司的合规官需要向监管机构提供证据,证明他们的理赔处理AI是公平和透明的。他们使用一个模型评估平台进行全面的审计。该平台生成一份详细的报告,其中包括:
- 整体性能指标(例如,欺诈检测的准确率)。
- 跨年龄、性别和地区子群体的公平性分析。
- 针对特定拒赔决策的基于示例的可解释性(XAI)说明。