
Ducky
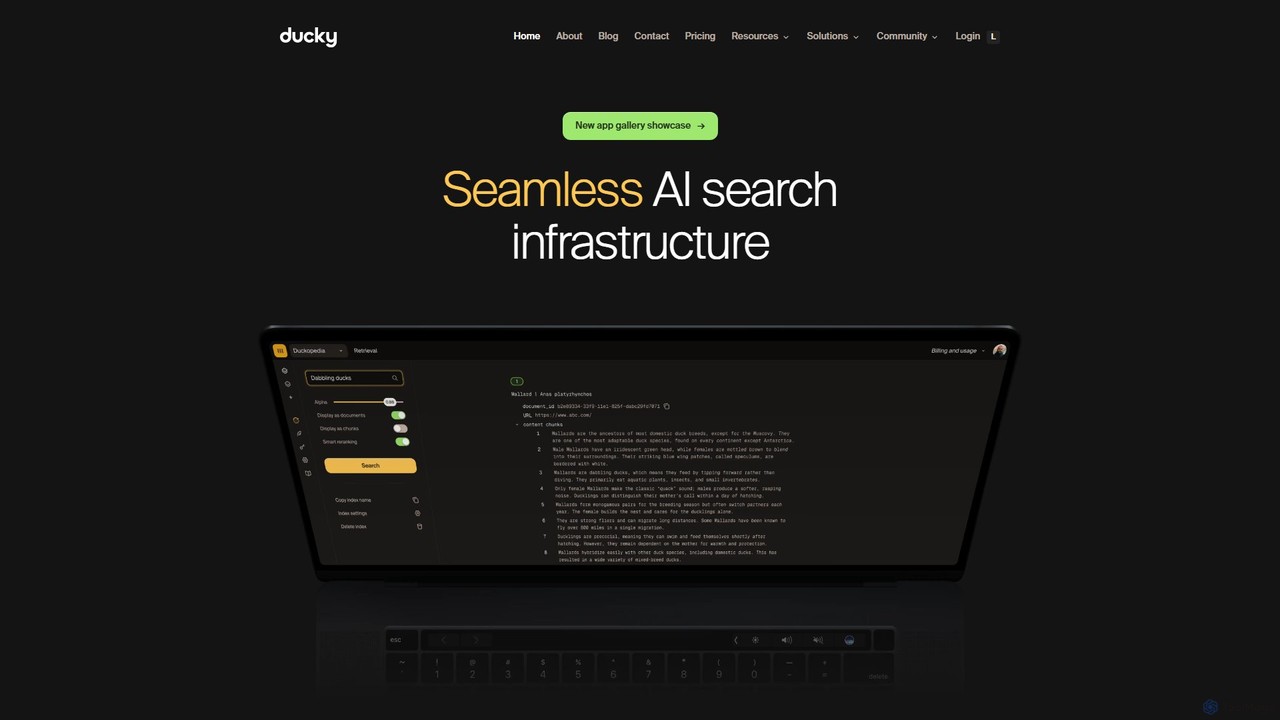
Ducky 是一个专为开发者设计的完全托管的 AI 搜索基础设施。它通过处理数据分块、嵌入和重排序等复杂任务,简化了检索增强生成(RAG)的实现。借助简单的 Python SDK,Ducky 使开发者能够快速地在应用中构建快速、准确且可扩展的语义搜索功能,从而为大语言模型(LLM)提供具有上下文感知能力且无幻觉的响应。
Ducky 是一个专为开发者设计的完全托管的 AI 搜索基础设施。它通过处理数据分块、嵌入和重排序等复杂任务,简化了检索增强生成(RAG)的实现。借助简单的 Python SDK,Ducky 使开发者能够快速地在应用中构建快速、准确且可扩展的语义搜索功能,从而为大语言模型(LLM)提供具有上下文感知能力且无幻觉的响应。
关于 向量搜索
向量搜索工具是一类专业的数据检索系统,它基于语义相似性而非精确关键词匹配来查找信息。其工作原理是将文本、图像或音频等数据转换为称为“向量”的数值表示,然后在高维空间中搜索最接近的向量。这使得应用程序能够理解上下文和含义,从而驱动更直观、更准确的搜索体验、推荐引擎和AI知识库。与传统搜索不同,向量搜索在处理复杂查询和非结构化数据方面表现出色。
核心功能
- 语义相似性搜索:即使不共享关键词,也能识别概念上相关的项目。
- 高维索引:采用专门的算法(如HNSW)从数十亿个向量中实现快速检索。
- 多模态能力:支持跨不同数据类型进行搜索,例如使用图像查找相关文本。
- 实时可扩展性:旨在以低延迟处理海量数据集和高查询负载。
- 混合搜索:将向量相似性与传统的元数据或关键词过滤相结合,以获得更精确的结果。
适用场景
向量搜索对于构建现代AI应用的开发者和数据科学家至关重要。它是AI聊天机器人检索增强生成(RAG)系统、电商视觉推荐引擎以及内容去重平台的支柱技术。此外,它还应用于安全领域的异常检测和科学研究中复杂数据集的模式匹配。
选择要点
选择向量搜索工具时,需考虑其在预期负载下的可扩展性和性能。评估其支持的索引算法以及在速度和准确性之间的权衡。考察其与嵌入模型和现有数据基础设施的集成能力。此外,还应比较部署选项(云托管、自托管)以及相关的定价模式和技术开销。
向量搜索应用场景
驱动AI聊天机器人知识库(RAG)
一位AI开发者负责构建一个客户支持聊天机器人,该机器人需要能根据庞大的技术文档库回答复杂问题。他们没有选择微调大型语言模型,而是使用了向量搜索系统。首先,所有文档被分块并转换为向量嵌入。当用户提问时,问题也被转换为向量。然后,系统执行向量搜索,找到语义上最相似的文档块。这些相关的文档块作为上下文提供给一个语言模型,由该模型生成一个准确且有来源依据的回答。这种被称为“检索增强生成”(RAG)的方法,显著提高了回答的准确性并减少了“幻觉”现象的发生。
电商平台的视觉产品推荐
一个电商平台希望改进其“相似产品”功能。基于标签和分类的传统方法常常无法捕捉视觉上的细微差别。通过实施向量搜索引擎,他们将每个产品图片转换为向量嵌入。当顾客查看某个产品时,该产品的图片向量被用来查询数据库中最近邻的向量。结果是一个在风格、颜色和图案上视觉相似的产品列表,即使它们的原数据描述完全不同。这带来了更具吸引力的用户体验,增加了产品发现率,并提高了转化率,因为顾客可以轻松找到符合其审美偏好的替代品。
内容去重与发现
一家大型媒体公司管理着数百万篇文章和图片。他们面临两个挑战:防止重复内容上传和帮助用户发现相关文章。他们使用向量搜索数据库来存储其所有内容的嵌入。当一篇新文章提交时,其内容被转换为向量并与数据库进行比对。如果一个非常接近的向量已经存在,该文章就会被标记为潜在的重复内容,从而节省了编辑时间。对于读者,当他们读完一篇文章时,该文章的向量被用来寻找其他具有相似语义内容的文章,从而提供比简单的基于分类的链接更相关的“下一篇阅读”建议。
网络安全中的异常检测
一位网络安全分析师需要监控网络流量,以发现可能预示威胁的异常活动。他们使用向量搜索系统来为正常的网络行为建模。每个网络事件(如登录尝试或数据传输)都根据其属性被转换为一个向量。随着时间的推移,这些向量形成了代表正常操作的集群。系统持续将新事件转换为向量,并搜索其最近邻。如果一个新事件的向量远离任何现有集群(即它没有近邻),它就会被标记为异常,需要立即进行调查。这使得能够检测到基于签名的系统会错过的、新颖的零日威胁。
反向图像搜索引擎
一位记者需要核实一张在社交媒体上流传的照片的真实性。他们使用一个由向量搜索驱动的反向图像搜索工具。记者上传图片,该工具立即将其转换为向量嵌入。然后,这个向量被用来在一个预先索引好的、包含全网海量图片的数据库中进行搜索。搜索在几毫秒内返回视觉上相似的图片,使记者能够识别照片的原始来源、上下文和日期。这个过程通过快速揭穿虚假或断章取义的图片来帮助打击虚假信息,而这是基于关键词的搜索无法完成的任务。
加速药物发现与基因组学研究
一位生物信息学家正在寻找与一种新发现的分子具有相似特性的化合物。将分子基于其结构和化学特性表示为向量嵌入,可以在海量规模上进行相似性搜索。研究人员将新分子的向量输入到一个包含数百万已知化合物的向量搜索数据库中。系统返回一个按相似度排序的分子列表,极大地缩小了实验室测试的候选范围。同样的原理也适用于基因组学,向量搜索可以识别具有相似功能模式的基因序列,从而加速对疾病和治疗方法的研究。