Rootly
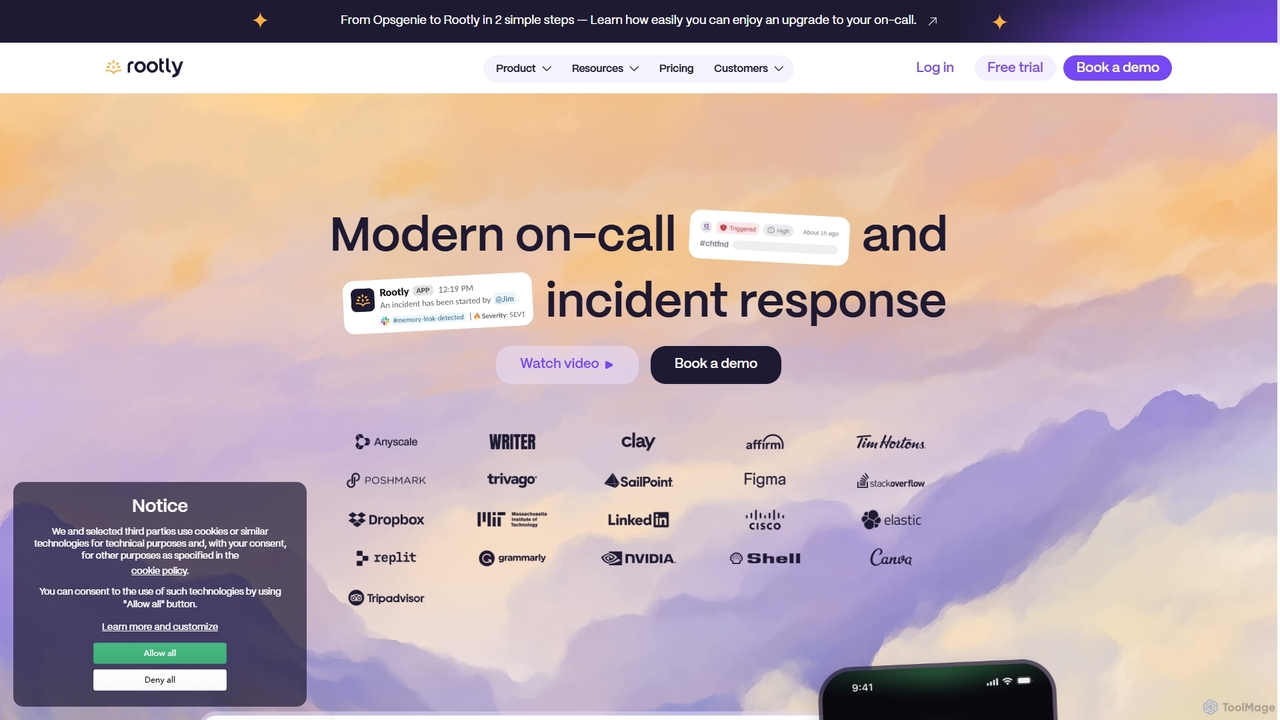
Rootly 是一款由 AI 驱动的端到端事件管理平台,专为工程和 SRE 团队设计。它能自动化整个事件生命周期,从待命调度、警报响应到问题解决和事后分析。通过与 Slack、Jira 和 Datadog 等工具的无缝集成,Rootly 简化了工作流程,减少了手动任务,帮助团队更快地解决问题,最终提高系统可靠性和运营效率。
Rootly 是一款由 AI 驱动的端到端事件管理平台,专为工程和 SRE 团队设计。它能自动化整个事件生命周期,从待命调度、警报响应到问题解决和事后分析。通过与 Slack、Jira 和 Datadog 等工具的无缝集成,Rootly 简化了工作流程,减少了手动任务,帮助团队更快地解决问题,最终提高系统可靠性和运营效率。
Resolve.ai
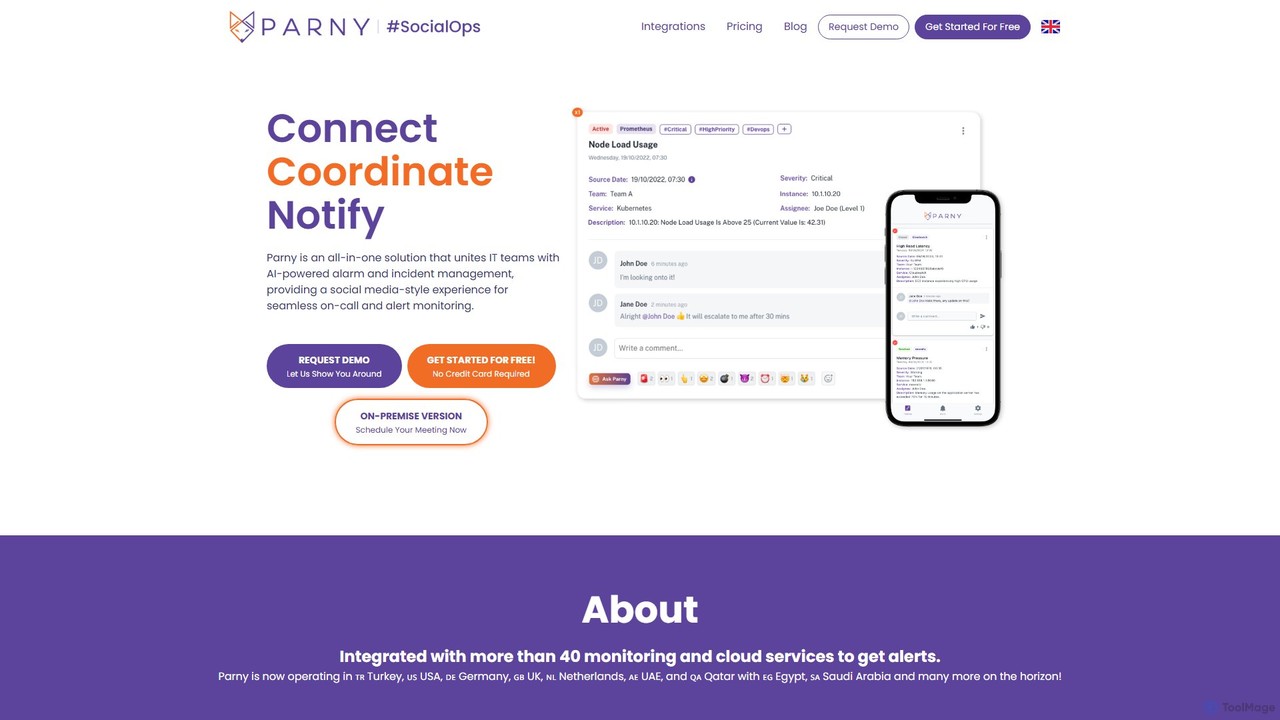
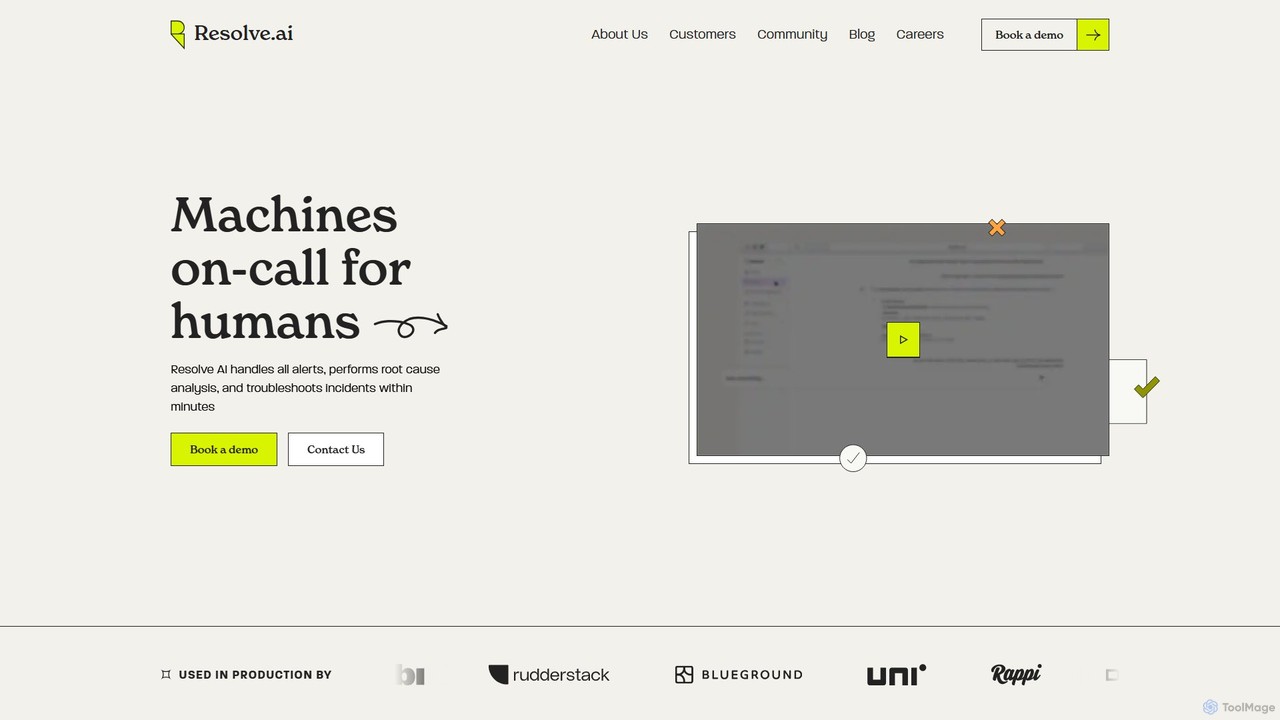
Resolve.ai 是一个代理式 AI SRE 平台,可自动执行事件响应和根本原因分析。它作为虚拟的待命团队成员,在几分钟内调查警报、测试假设并识别问题,以减少平均解决时间(MTTR)、减轻工程师倦怠并提高系统正常运行时间。
Resolve.ai 是一个代理式 AI SRE 平台,可自动执行事件响应和根本原因分析。它作为虚拟的待命团队成员,在几分钟内调查警报、测试假设并识别问题,以减少平均解决时间(MTTR)、减轻工程师倦怠并提高系统正常运行时间。


PagerDuty
PagerDuty 是一个以 AI 为先的运营平台,专为实时事件管理和自动化而设计。它赋能 DevOps、IT 和安全团队,以更快地检测、分类和解决关键事件。通过利用 AIOps 和自动化,PagerDuty 帮助减少停机时间、提高团队生产力并保障客户体验,成为现代数字运营的中心枢纽。
PagerDuty 是一个以 AI 为先的运营平台,专为实时事件管理和自动化而设计。它赋能 DevOps、IT 和安全团队,以更快地检测、分类和解决关键事件。通过利用 AIOps 和自动化,PagerDuty 帮助减少停机时间、提高团队生产力并保障客户体验,成为现代数字运营的中心枢纽。
关于 事件管理
AI事件管理工具是开发者工具中的一类专业平台,它利用机器学习自动完成软件系统事件的检测、诊断和解决。这些工具通过分析日志、指标和追踪等海量遥测数据,在影响用户前识别异常并预测潜在问题。其核心价值在于大幅缩短平均解决时间(MTTR)并减少待命团队的人工负担。通过提供富含上下文的警报和可行的洞察,它们使工程师能更快地解决复杂问题。
核心功能
- 智能警报与分类:利用AI将相关警报分组、抑制噪音并优先处理关键事件,减轻警报疲劳。
- 自动根因分析(RCA):分析系统数据,自动定位事件的可能原因,如特定的代码部署或配置变更。
- 自动化修复工作流:针对常见事件,建议或自动执行预定义的修复操作(应急预案)。
- 事件时间线与复盘报告生成:自动构建事件的时间顺序记录,并起草事后复盘报告以促进团队学习。
适用场景
这些工具对于负责维护关键应用正常运行时间和性能的网站可靠性工程(SRE)、开发运维(DevOps)和平台工程团队至关重要。它们广泛应用于技术公司、电商平台和金融服务等对系统可靠性要求极高的行业。例如,待命工程师可以用它即时了解数据库故障的影响范围。
选择要点
选择AI事件管理工具时,应考虑其与现有监控技术栈(如Datadog、Prometheus)的集成能力。评估其AI模型在异常检测和根因分析方面的成熟度。此外,还需考察其自动化和工作流功能的灵活性,并确保它支持团队使用的协作渠道,如Slack或Microsoft Teams。
事件管理应用场景
自动化待命警报分类
对于一个管理微服务架构的网站可靠性工程(SRE)团队来说,警报疲劳是一个持续的挑战。AI事件管理工具与他们的监控系统集成,接收数千个原始警报。AI不会因为每次微小的波动就呼叫待命工程师,而是将相关事件关联起来,将它们组合成一个可操作的事件,并抑制低优先级的噪音。这意味着工程师只会在真正发生高影响问题时才被唤醒,让他们能将精力集中在解决实际问题上,并显著改善工作与生活的平衡。
加速根因分析
一位开发运维工程师正在调查API延迟突然飙升的问题。手动筛选来自数十个服务的日志、指标和部署历史可能需要数小时。通过使用AI事件管理工具,工程师可以看到一个整合视图,其中AI已经分析了所有相关数据。该工具将认证服务中最近的一次代码部署标记为最可能的原因,并指出了一个错误率增加的特定函数。这将调查时间从数小时缩短到几分钟,从而实现更快的代码回滚和问题解决。
简化事件沟通流程
在一次重大服务中断期间,事件指挥官需要协调多个团队的工作并向利益相关者通报情况。AI事件管理工具可以自动化此过程。在宣布事件后,它会自动创建一个专用的Slack频道,邀请相关服务的待命工程师,并设置一个视频会议桥。它还会向状态页面发布实时更新,并为高管利益相关者总结关键进展。这种自动化将事件指挥官从繁琐的后勤任务中解放出来,让他们能够完全专注于策略和解决方案。
生成可行的事后复盘报告
事件解决后,产品团队需要进行事后复盘以从失败中学习。手动编制事件时间线、收集聊天记录和确定关键决策既繁琐又容易出错。AI事件管理工具会自动生成一份复盘报告草稿。该报告包括事件期间警报、所采取的行动和关键指标的精确时间线。它甚至可以根据过去事件的模式建议促成因素和行动项。这为团队节省了数小时的手动工作,并确保了更准确、更有见地的审查过程。
主动异常检测
一个平台工程团队希望在事件发生前就进行预防。他们配置AI事件管理工具来监控数据库查询时间和内存使用等关键性能指标(KPI)。该工具的机器学习模型学习系统的正常基线行为。当它检测到一个偏离此基线的、细微且缓慢增长的内存泄漏时,它会为团队创建一个低优先级的工单,供其在工作时间内调查。这种主动警报使他们能够在可用内存耗尽并导致严重中断之前修复潜在问题。
自动化修复工作流
一个云运营团队经常处理一个已知问题,即需要重启特定服务以清除其缓存。他们不再在每次警报触发时手动执行此任务,而是在其AI事件管理工具中创建了一个自动化的应急预案。现在,当工具检测到与此问题相关的特定警报模式时,它会自动触发该应急预案。应急预案会安全地连接到生产环境并执行重启命令。这不仅在无需人工干预的情况下在几秒钟内解决了问题,还在事件时间线中记录了该操作,以实现完全的可审计性。