关于 基准测试
AI基准测试工具是用于系统性评估和比较人工智能模型与系统性能的专业平台。它们通过在不同模型上运行标准化测试或自定义提示,来衡量准确性、速度、成本和输出质量等关键指标。这使得开发者、研究人员和企业在选择、微调或部署AI解决方案时能够做出数据驱动的决策。作为生产力生态系统的重要组成部分,这些工具确保所选的AI组件对于特定任务是最高效和最有效的,从而直接优化工作流程和成果。
核心功能
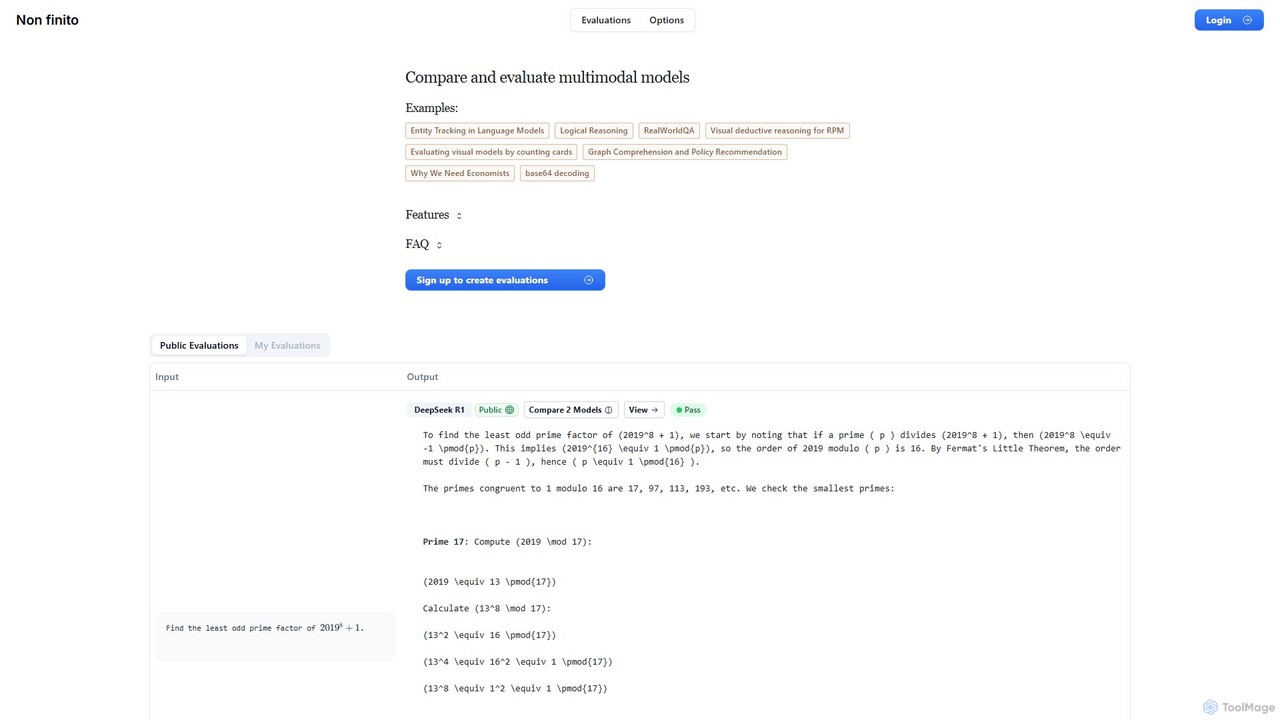
- 模型性能指标:衡量客观标准,如准确率、延迟、吞吐量及其他相关评分(如BLEU、ROUGE)。
- 对比排行榜:在相同任务上提供多个AI模型的并排比较,以便清晰评估。
- 标准化数据集:利用行业公认的基准(如MMLU、HumanEval)进行客观且可复现的评估。
- 成本效益分析:计算并比较不同模型的API成本与输出质量,以确定投资回报率。
- 自定义测试创建:允许用户使用其特定的数据、提示和评估标准来构建和运行专有测试。
适用场景
这些工具被AI开发者广泛用于模型选择,被数据科学家用于验证微调模型,以及被产品经理用于评估不同AI集成的投资回报率。在企业环境中,它们对于回归测试和确保模型更新后AI性能的持续稳定至关重要。
选择要点
在选择AI基准测试工具时,应考虑其支持的模型范围(如大型语言模型、图像模型)、相关行业基准的可用性,以及创建自定义评估套件的灵活性。此外,还应评估其与现有开发工作流程的集成能力,以及其报告和分析仪表板的清晰度。
基准测试应用场景
为客户支持选择最佳的大语言模型
一家科技公司需要构建一个AI聊天机器人来处理客户咨询。他们使用基准测试工具,在一个包含1000张真实客户支持工单的数据集上,测试三个领先的大语言模型(如GPT-4、Claude 3、Gemini Pro)。该工具自动为每个模型测量响应准确性、礼貌度得分和API延迟。最终的排行榜清晰地显示,其中一个模型在质量和速度之间达到了最佳平衡,最符合他们的特定需求,从而使其开发团队能够做出一个自信且有数据支持的决策。
评估微调模型的改进效果
一个数据科学团队为法律文件分析微调了一个开源模型。为了证明其价值,他们使用一个基准测试平台,将微调后的版本与原始模型及一个专有模型进行比较。通过运行一个包含200个法律查询的自定义测试套件,他们生成了一份报告,显示在合同条款识别方面的准确性提高了15%。这个量化结果证明了在微调上的投资是合理的,并向利益相关者提供了性能提升的明确证据。
优化用于营销文案的提示
一个营销团队需要大规模生成高质量的广告文案。他们使用基准测试工具,在多个AI模型上对20种不同的提示变体进行A/B测试。该工具自动化了整个过程,并根据预定义的质量标准(如清晰度和行动号召力)对输出进行评分。这种数据驱动的方法帮助他们识别出表现最佳的提示与模型组合,然后可以将其集成到内容工作流程中,以持续产出更有效的营销材料。
AI系统回归测试
一家企业更新了其内部知识管理系统中的核心AI模型。在部署之前,质量保证团队使用基准测试工具运行一套预定义的500个测试,覆盖关键功能。该工具将新模型的结果与前一版本的基线进行比较,并标记出任何显著的性能下降。这确保了更新不会无意中引入回归问题,从而维护了系统的可靠性和用户信任。
控制AI API成本
一家初创公司的应用严重依赖一个文本到图像的API,成本不断上升。他们使用基准测试工具来评估三个更便宜的替代模型。他们在100个代表性提示上测试了所有模型,比较了输出图像质量、风格一致性和每张图像的成本。分析显示,有一个模型便宜40%,同时满足了他们90%的质量要求。这些数据使他们能够进行战略性转换,在不大幅牺牲产品质量的情况下显著降低运营成本。
关于模型能力的学术研究
大学研究人员正在研究新兴大语言模型的推理能力。他们利用一个基准测试平台,系统地在五个不同的开源模型上运行ARC(AI2推理挑战)基准测试。该平台自动化了执行过程,收集结果,并提供可视化工具进行分析。这极大地加速了他们的研究进程,使他们能够专注于解读数据和发表比较性研究结果,而不是手动设置和执行测试。