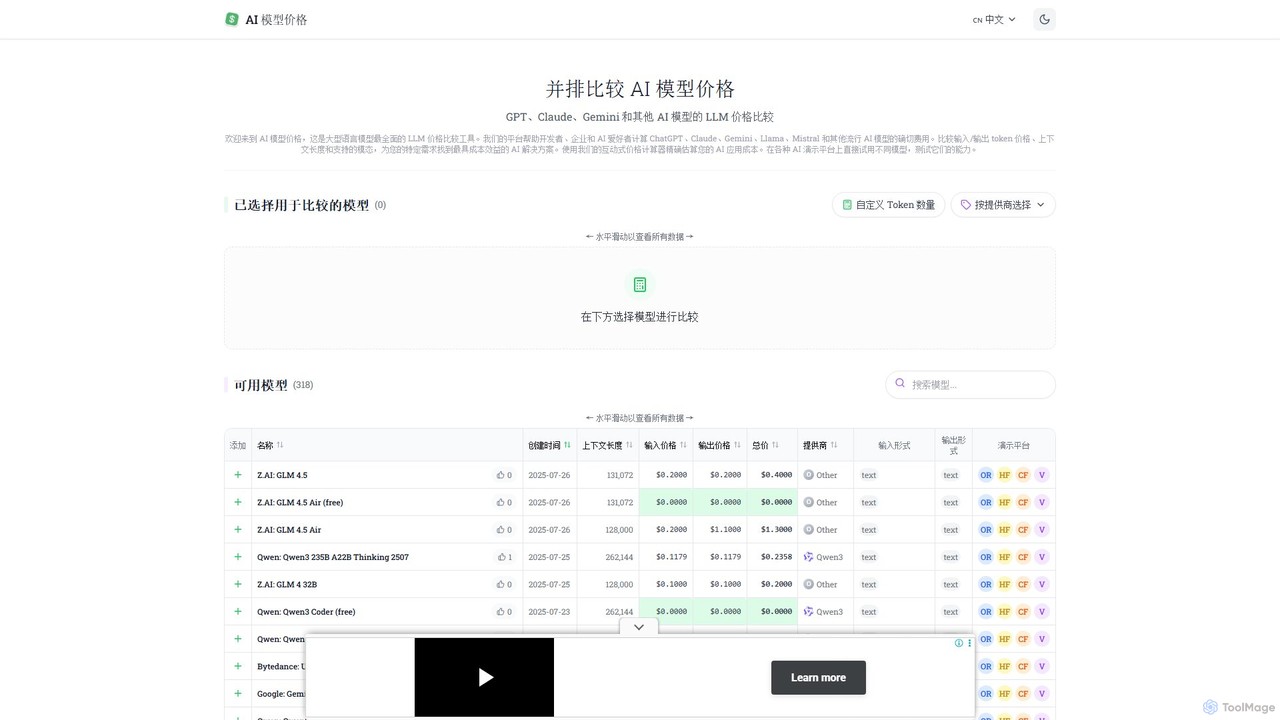
llm_price
llm_price 是一个用于大型语言模型(LLM)API 定价的综合比较工具。它使开发人员、企业和 AI 爱好者能够轻松比较来自 OpenAI、谷歌、Anthropic 和 Mistral 等提供商的数百个模型的成本。通过交互式成本计算器以及对令牌价格、上下文长度和模态的并排分析,它简化了为任何项目选择最具成本效益的 AI 解决方案的过程。
llm_price 是一个用于大型语言模型(LLM)API 定价的综合比较工具。它使开发人员、企业和 AI 爱好者能够轻松比较来自 OpenAI、谷歌、Anthropic 和 Mistral 等提供商的数百个模型的成本。通过交互式成本计算器以及对令牌价格、上下文长度和模态的并排分析,它简化了为任何项目选择最具成本效益的 AI 解决方案的过程。

abcdindex
abcdindex(学术商业动态数据索引)是一个面向学术界的免费、综合性平台。它提供了一个经过验证的、结构化的国际期刊、研究论文、资金机会、奖学金和其他学术资源的数据库。该平台旨在通过提供可靠、集中的信息,帮助研究人员、学生和出版商高效地驾驭学术领域,并避开掠夺性或不活跃的出版物。
abcdindex(学术商业动态数据索引)是一个面向学术界的免费、综合性平台。它提供了一个经过验证的、结构化的国际期刊、研究论文、资金机会、奖学金和其他学术资源的数据库。该平台旨在通过提供可靠、集中的信息,帮助研究人员、学生和出版商高效地驾驭学术领域,并避开掠夺性或不活跃的出版物。
关于 数据库
AI数据库是经过精心整理的结构化数据集,是训练、测试和部署人工智能模型的基础资源。这些资源专为机器使用而准备,通常包含大量带标签或无标签的数据,如图像、文本或数值。它们为机器学习、自然语言处理和计算机视觉任务提供了必要的原材料。这些数据库的质量、规模和相关性直接决定了AI系统的性能和能力。
核心功能
- 结构化与标注数据:数据经过组织,并常常附有标签,使其适用于监督学习算法。
- 大规模:通常包含数百万甚至数十亿个数据点,以确保模型能够学习到可泛化的模式。
- 领域特定性:专注于特定领域,如医疗、金融或自动驾驶,以构建专业化AI。
- 数据质量与一致性:经过清洗和验证,以最大程度地减少噪音和偏见,这对于构建可靠模型至关重要。
适用场景
AI数据库对数据科学家、机器学习工程师和研究人员至关重要。它们被用于通过图像数据集训练人脸识别系统,利用海量文本语料库开发语言模型,以及根据历史交易数据构建欺诈检测算法。学术机构也使用标准化的数据集来衡量新型AI算法的性能基准。
选择要点
选择AI数据库时,需考虑其与特定问题领域的相关性。评估数据质量、标签的准确性以及潜在偏见的存在。检查许可条款,确保其可用于预期目的(如学术研究或商业应用)。最后,评估数据格式和大小,确认其与您的计算资源和工具链兼容。
数据库应用场景
训练医学图像分析模型
医疗领域的AI研究员需要开发一个能从X光或MRI等医学扫描中检测疾病早期迹象的模型。他们使用一个专业的高质量数据库,其中包含数千张经过匿名处理的医学图像,每张图像都由放射科医生精心标注。通过在这个数据集上训练计算机视觉模型,系统学会识别与特定病症相关的细微模式。最终的AI工具可以辅助放射科医生,高亮显示潜在的关注区域,从而实现更快、更准确的诊断。
开发自然语言处理(NLP)模型
一个数据科学团队的任务是为客户评论构建一个情感分析工具。为实现这一目标,他们利用一个大规模文本数据库,其中包含数百万条产品评论,每条评论都标注为正面、负面或中性。这个语料库作为训练NLP模型的基础事实。模型处理文本,学习语言的细微差别,并识别与不同情感相关的模式。训练完成后,该工具可以自动对新的、未见过的评论进行分类,为企业提供大规模的关于客户满意度的宝贵见解。
构建金融欺诈检测系统
一家金融科技公司旨在为用户减少欺诈性交易。他们的机器学习工程师使用一个庞大的历史交易数据库。该数据库包含交易金额、时间、地点和商户类型等特征,并且每笔交易都被标记为合法或欺诈。通过在这个数据上训练一个异常检测模型,系统学习了正常交易行为的特征。当新交易发生时,模型可以实时预测其为欺诈的可能性,使公司能够阻止可疑活动并保护其客户。
为新型AI算法进行基准测试
一个学术研究实验室开发了一种新颖的物体识别算法。为了证明其有效性,他们必须将其性能与现有的顶尖方法进行比较。他们使用像ImageNet或COCO这样的标准化公共数据库,这些数据库在研究界被广泛接受用于基准测试。通过在相同的数据集上运行他们的新算法和已有的算法,他们可以获得准确率和处理速度等客观指标。这使他们能够以可验证的结果发表他们的研究成果,为AI领域的进步做出贡献。
为基于知识的问答系统提供支持
一家法律科技公司希望创建一个能回答复杂法律问题的AI助手。他们不使用通用的文本语料库,而是采用一个专业的知识库——一个包含法律法规、判例法和学术文章的结构化数据库,所有内容都通过知识图谱相互连接。当律师提出问题时,AI不仅仅是搜索关键词,它会导航这个图谱来理解关系和上下文。这使得系统能够提供高度准确、具有上下文感知能力并由具体法律引文支持的答案,成为法律专业人士的强大研究工具。
为AI模型测试创建合成数据
一个AI开发团队正在构建一个自动驾驶系统,但缺乏足够的真实世界数据来应对罕见的边缘情况,例如动物突然穿过马路。他们使用一个基础的驾驶场景数据库来生成大量逼真的合成数据。这个过程使他们能够创建单个场景的数千种变体,改变天气条件、光照和物体速度。通过在这个全面的合成数据库上测试他们的模型,他们可以确保AI在那些过于危险或不常发生以至于无法在现实中捕捉到的情况下是稳健和可靠的,同时不损害用户隐私。