

WebScraping.AI
WebScraping.AI 是一款面向开发人员的高级API,利用AI简化网络爬虫。它具备轮换代理、JavaScript渲染和地理定位功能,可绕过封锁并访问动态内容。其核心优势在于由LLM驱动的工具,能直接从网页中提取非结构化数据、生成摘要并回答问题,极大地简化了任何项目的数据收集流程。
WebScraping.AI 是一款面向开发人员的高级API,利用AI简化网络爬虫。它具备轮换代理、JavaScript渲染和地理定位功能,可绕过封锁并访问动态内容。其核心优势在于由LLM驱动的工具,能直接从网页中提取非结构化数据、生成摘要并回答问题,极大地简化了任何项目的数据收集流程。

ScrapingBee
ScrapingBee 是一款功能强大的网络爬虫 API,可处理无头浏览器和代理轮换,以防止被封锁。它具有创新的 AI 驱动提取器,让您可以用简单的英语描述所需数据,无需使用复杂的 CSS 选择器。非常适合开发人员、营销人员和数据分析师用于价格监控、潜在客户生成和搜索引擎结果页面(SERP)分析等任务。
ScrapingBee 是一款功能强大的网络爬虫 API,可处理无头浏览器和代理轮换,以防止被封锁。它具有创新的 AI 驱动提取器,让您可以用简单的英语描述所需数据,无需使用复杂的 CSS 选择器。非常适合开发人员、营销人员和数据分析师用于价格监控、潜在客户生成和搜索引擎结果页面(SERP)分析等任务。
UseScraper
UseScraper 是一款功能强大的网络爬虫和抓取 API,专为开发人员和 AI 应用而设计。它能高效地从任何网站提取数据,具有完整的 JavaScript 渲染、自动扩展的基础设施以及清晰的 Markdown 等输出格式,非常适合为 ChatGPT 等大语言模型提供数据。
UseScraper 是一款功能强大的网络爬虫和抓取 API,专为开发人员和 AI 应用而设计。它能高效地从任何网站提取数据,具有完整的 JavaScript 渲染、自动扩展的基础设施以及清晰的 Markdown 等输出格式,非常适合为 ChatGPT 等大语言模型提供数据。
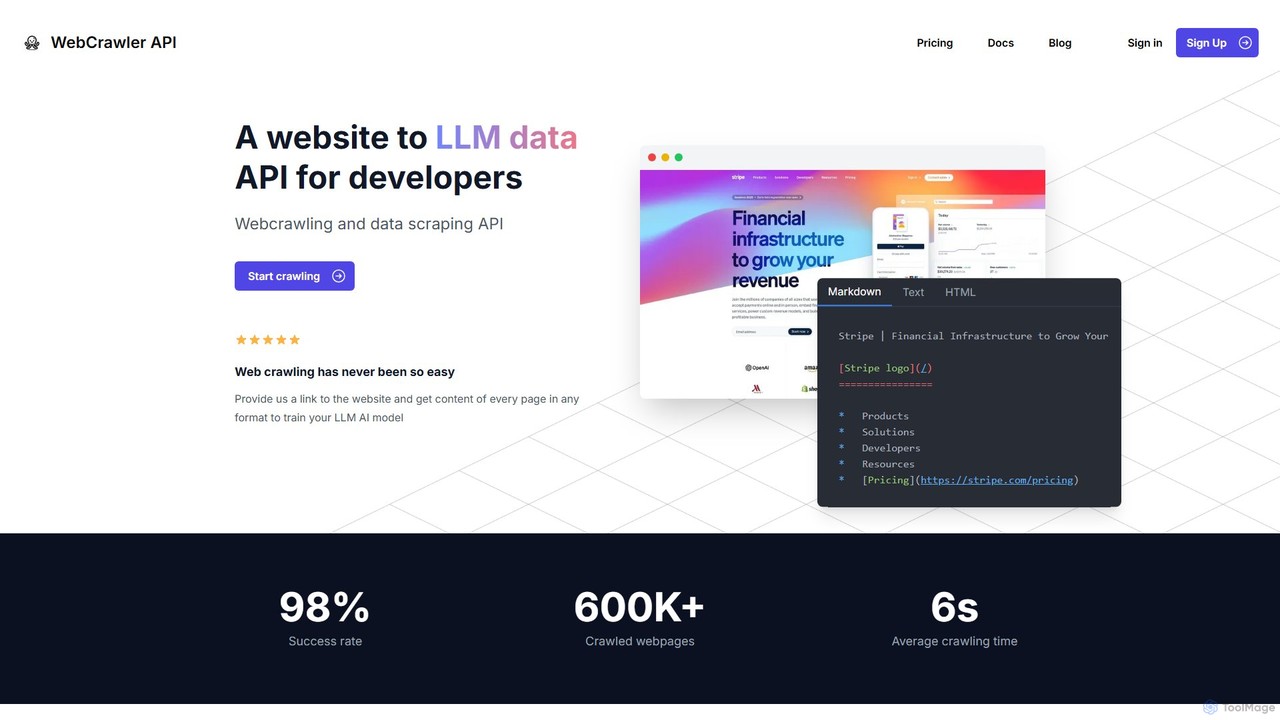
Webcrawlerapi
Webcrawlerapi 是一款功能强大的API,专为开发人员设计,可轻松抓取网站并提取干净的数据。它通过处理JavaScript渲染、反机器人措施和数据解析,简化了复杂的网络抓取过程。该工具非常适合收集Markdown或文本等结构化内容,用于训练LLM AI模型或检索增强生成(RAG)系统,并提供高成功率和简单的按量付费定价模式。
Webcrawlerapi 是一款功能强大的API,专为开发人员设计,可轻松抓取网站并提取干净的数据。它通过处理JavaScript渲染、反机器人措施和数据解析,简化了复杂的网络抓取过程。该工具非常适合收集Markdown或文本等结构化内容,用于训练LLM AI模型或检索增强生成(RAG)系统,并提供高成功率和简单的按量付费定价模式。
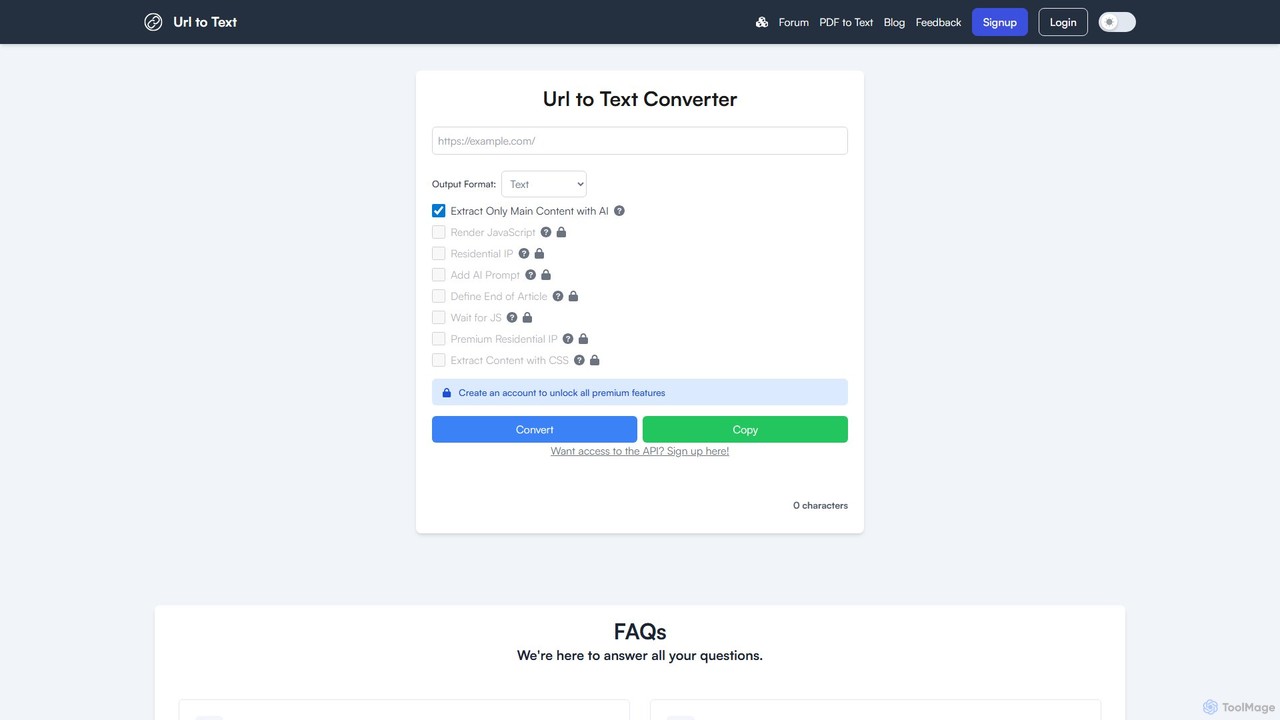
URLtoText
URLtoText 是一款由AI驱动的工具,可从任何网站或PDF中提取干净、结构化的文本。它能智能地移除广告、侧边栏和其他杂乱内容,仅提供核心正文。该工具具备JavaScript渲染、住宅IP代理和开发者API等功能,专为需要从静态和动态网页中可靠提取数据的研究人员、开发者和企业设计。
URLtoText 是一款由AI驱动的工具,可从任何网站或PDF中提取干净、结构化的文本。它能智能地移除广告、侧边栏和其他杂乱内容,仅提供核心正文。该工具具备JavaScript渲染、住宅IP代理和开发者API等功能,专为需要从静态和动态网页中可靠提取数据的研究人员、开发者和企业设计。