
Crawlora 概览
Crawlora 是一个先进的、由人工智能驱动的网络爬虫平台,旨在让网络数据提取大众化。它使企业和个人能够从任何网站获取有价值的信息,而无需技术专长或编写复杂的代码。通过利用人工智能,Crawlora 能够智能地识别、选择和结构化来自动态复杂网页的数据,将广阔的互联网转变为一个有组织的、可操作的数据库。该平台专为规模化、高效率和易用性而构建,满足从简单数据收集到复杂的企业级数据工作流的广泛需求。
如何使用 Crawlora
使用 Crawlora 是一个为实现最高效率而设计的简单三步流程:
- 输入URL:只需将您想抓取数据的网站URL粘贴到 Crawlora 仪表板中。平台将在一个交互式浏览器中加载该页面。
- 点击选择数据:使用鼠标点击您希望提取的数据元素(例如,产品名称、价格、联系方式、文章)。Crawlora 的人工智能将自动检测模式并选择页面上所有相似的项目,为您构建数据提取规则。
- 运行并导出:配置您的抓取设置,例如安排每日或每周运行,然后启动爬虫。Crawlora 将在其云服务器上运行,收集数据,并允许您以CSV、JSON或Excel等结构化格式下载。您还可以通过API或webhook将数据直接发送到其他应用程序。
Crawlora 的核心功能
- AI驱动的元素选择:智能识别数据字段并处理复杂的网站结构,减少构建爬虫所需的人工工作。
- 无代码可视化界面:一个用户友好的点击式工作流,使市场营销人员、分析师和企业家等非开发人员也能进行网络爬虫。
- 计划与自动化抓取:设置爬虫按重复计划(每小时、每天、每周)运行,以自动监控数据随时间的变化。
- 基于云的基础设施:所有抓取任务都在 Crawlora 的可扩展云服务器上运行,因此您无需使用自己计算机的资源。
- 高级抓取能力:处理大量使用JavaScript的网站、分页、无限滚动,并能导航表单和登录页面。
- 内置代理轮换:自动轮换IP地址以避免被封锁,确保您的数据提取任务具有高成功率。
- 数据清洗与转换:提供工具,在导出前直接在平台内清洗和格式化提取的数据。
- API和Webhook集成:将 Crawlora 与您自己的应用程序、数据库或商业智能工具无缝集成,实现自动化工作流。
Crawlora 的使用案例
Crawlora 是一款适用于各行各业的多功能工具:
- 电子商务与零售:监控竞争对手价格、跟踪产品可用性、汇总客户评论并丰富产品目录。
- 市场营销与销售:通过抓取商业目录、社交媒体资料和专业网络来生成高质量的潜在客户。
- 市场研究:分析市场趋势、跟踪品牌情绪,并从新闻网站、论坛和博客中收集竞争情报。
- 房地产:从多个房地产网站汇总房产列表,创建一个全面的可用房产数据库。
- 金融:收集股市数据、财务报表和另类数据用于投资分析。
Crawlora 的优势特点
与传统的抓取方法相比,Crawlora 具有显著优势。其无代码方法极大地减少了与数据收集相关的时间和成本。由人工智能驱动的引擎确保了更高的准确性和弹性,因为它能适应网站布局的微小变化。这使得数据提取更加可靠,维护工作也更少。此外,其可扩展性允许用户从抓取单个页面扩展到数百万个页面,而无需担心基础设施管理。
定价和计划
Crawlora 采用免费增值模式,让每个人都能使用。
- 免费计划:适用于小型项目和评估,每月提供有限数量的抓取积分和基本功能。
- 入门计划:专为个人和小型企业设计,提供更多积分、计划抓取和标准支持。
- 专业计划:最适合成长中的企业和高级用户,此计划包括大量积分、API访问、高级代理选项和优先支持。
- 企业计划:为有特定需求的大型组织提供定制解决方案,提供无限的可扩展性、专属客户经理和服务水平协议(SLA)。
Crawlora 评论 (0)
登录后即可发表评论
立即登录Crawlora 替代方案
查看全部
Octoparse
Octoparse是一款强大的无代码网页抓取工具,任何人无需编程即可从网站提取数据。它提供可视化工作流设计器、用于轻松设置的AI助手以及数百个适用于热门网站的预构建模板。借助基于云的自动化、IP轮换和验证码解决功能,Octoparse能高效处理复杂的抓取任务,将网页转化为结构化数据,用于潜在客户开发、市场研究等。
Octoparse是一款强大的无代码网页抓取工具,任何人无需编程即可从网站提取数据。它提供可视化工作流设计器、用于轻松设置的AI助手以及数百个适用于热门网站的预构建模板。借助基于云的自动化、IP轮换和验证码解决功能,Octoparse能高效处理复杂的抓取任务,将网页转化为结构化数据,用于潜在客户开发、市场研究等。

Roborabbit
Roborabbit 是一个无代码、由AI驱动的网页抓取和浏览器自动化平台。它允许用户通过简单的拖放界面从任何网站提取数据,无需编写任何代码。您可以安排任务、通过Zapier和Make.com与5000多个应用集成,或使用REST API进行高级工作流。它专为市场营销人员、数据分析师和开发人员设计,可轻松实现重复性任务自动化、监控竞争对手并收集有价值的商业情报。
Roborabbit 是一个无代码、由AI驱动的网页抓取和浏览器自动化平台。它允许用户通过简单的拖放界面从任何网站提取数据,无需编写任何代码。您可以安排任务、通过Zapier和Make.com与5000多个应用集成,或使用REST API进行高级工作流。它专为市场营销人员、数据分析师和开发人员设计,可轻松实现重复性任务自动化、监控竞争对手并收集有价值的商业情报。
Chat4Data
Chat4Data 是一款由 AI 驱动的 Chrome 扩展程序,它彻底改变了网络爬虫的方式。只需使用自然语言与 AI 对话,即可从任何网站提取结构化数据,包括文本、图片、链接和电子邮件。无需任何编码,让数据收集速度提高10倍,人人皆可使用。它具有自动翻页和智能数据检测功能,可提供全面的结果。
Chat4Data 是一款由 AI 驱动的 Chrome 扩展程序,它彻底改变了网络爬虫的方式。只需使用自然语言与 AI 对话,即可从任何网站提取结构化数据,包括文本、图片、链接和电子邮件。无需任何编码,让数据收集速度提高10倍,人人皆可使用。它具有自动翻页和智能数据检测功能,可提供全面的结果。

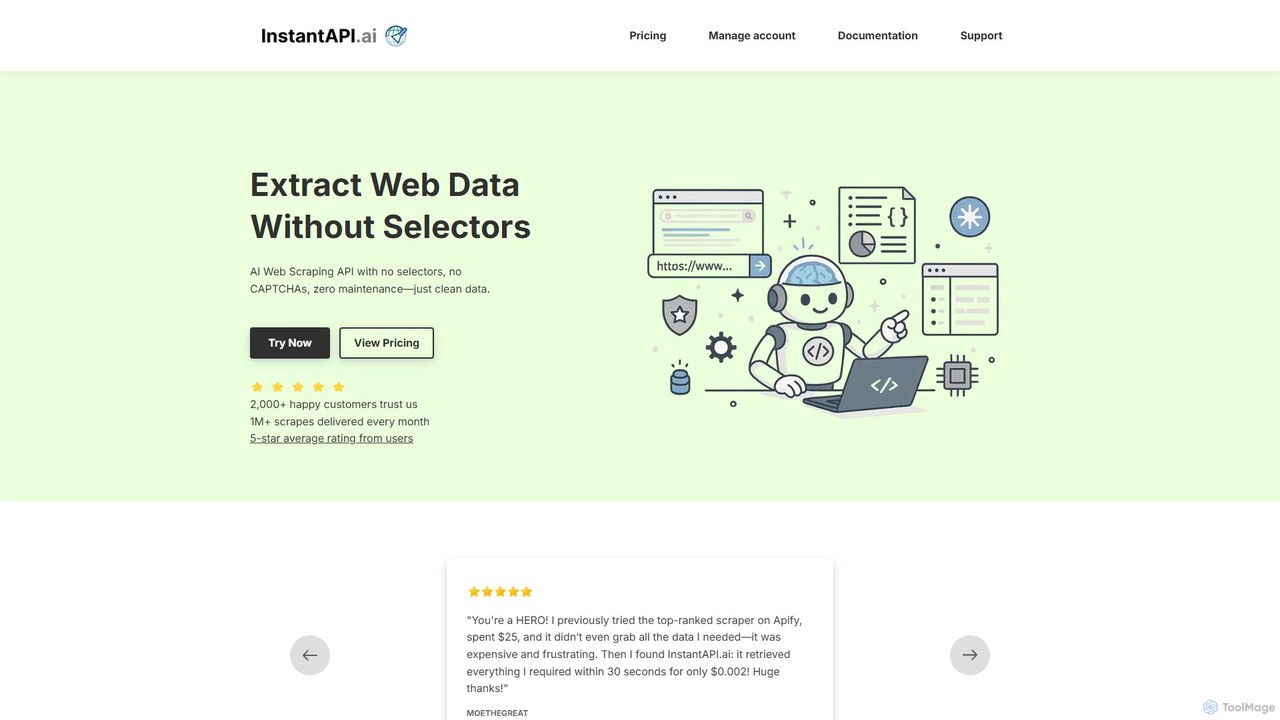
instantapi
instantapi 是一个由人工智能驱动的网页抓取API,专为简化和提速而设计。它允许用户通过单个API调用从任何网站提取结构化数据,无需复杂的编码或手动设置。对于需要快速、经济、可靠的数据提取而又不想处理传统网络爬虫麻烦的开发人员、数据分析师和企业来说,这是一个理想的选择。
instantapi 是一个由人工智能驱动的网页抓取API,专为简化和提速而设计。它允许用户通过单个API调用从任何网站提取结构化数据,无需复杂的编码或手动设置。对于需要快速、经济、可靠的数据提取而又不想处理传统网络爬虫麻烦的开发人员、数据分析师和企业来说,这是一个理想的选择。

FetchFox
FetchFox 是一款由人工智能驱动的网页抓取工具,用户只需使用简单的文本提示即可从任何网站提取数据。它无需复杂的编码或CSS选择器,并能自动处理反机器人措施。该工具提供API、JavaScript库和Chrome扩展程序,专为开发人员和非技术用户设计,可轻松实现数据收集自动化。
FetchFox 是一款由人工智能驱动的网页抓取工具,用户只需使用简单的文本提示即可从任何网站提取数据。它无需复杂的编码或CSS选择器,并能自动处理反机器人措施。该工具提供API、JavaScript库和Chrome扩展程序,专为开发人员和非技术用户设计,可轻松实现数据收集自动化。
Crawlora AI工具对比
Crawlora 嵌入功能
只需复制下方嵌入代码,将精美徽章贴到您的博客、文章或应用官网,即可把流量直接引导到本工具详情页,快速提升曝光与用户量!

还没有评论,成为第一个评论者吧!