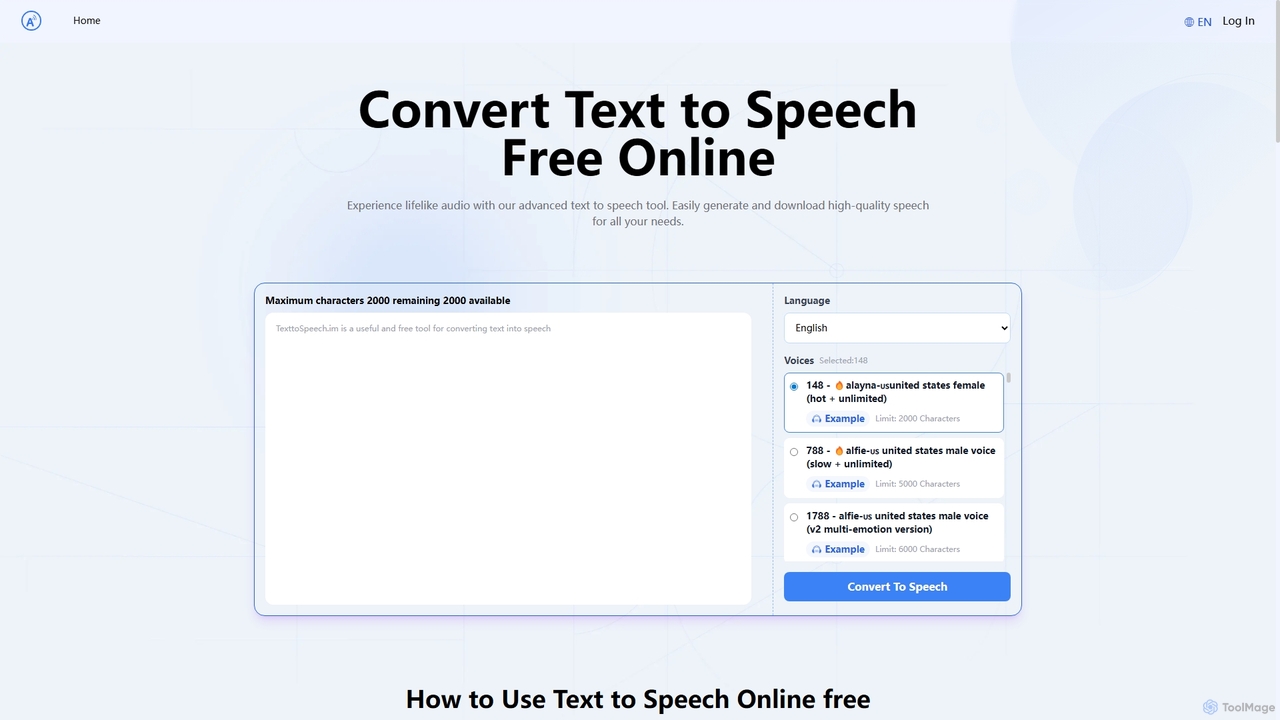
Text to Speech.im
Text to Speech.im 是一款免費的線上 AI 工具,可將文字轉換為自然流暢的語音。它支援多種語言和聲音,讓使用者可以為影片、數位學習、無障礙閱讀等場景生成高品質的音訊。您可以自訂語速和音量,並輕鬆下載生成的 MP3 音訊檔案。
Text to Speech.im 是一款免費的線上 AI 工具,可將文字轉換為自然流暢的語音。它支援多種語言和聲音,讓使用者可以為影片、數位學習、無障礙閱讀等場景生成高品質的音訊。您可以自訂語速和音量,並輕鬆下載生成的 MP3 音訊檔案。

Voice Isolator
Voice Isolator 是一款功能全面的 AI 音訊處理套件,旨在提供純淨的音質。它擅長消除背景噪音、從任何音軌中分離人聲和樂器、清理錄音以提高清晰度,以及從文本生成自然流暢的語音。是播客、音樂家和內容創作者尋求專業級音訊處理的理想選擇,其網頁介面簡單、快速且直觀。
Voice Isolator 是一款功能全面的 AI 音訊處理套件,旨在提供純淨的音質。它擅長消除背景噪音、從任何音軌中分離人聲和樂器、清理錄音以提高清晰度,以及從文本生成自然流暢的語音。是播客、音樂家和內容創作者尋求專業級音訊處理的理想選擇,其網頁介面簡單、快速且直觀。
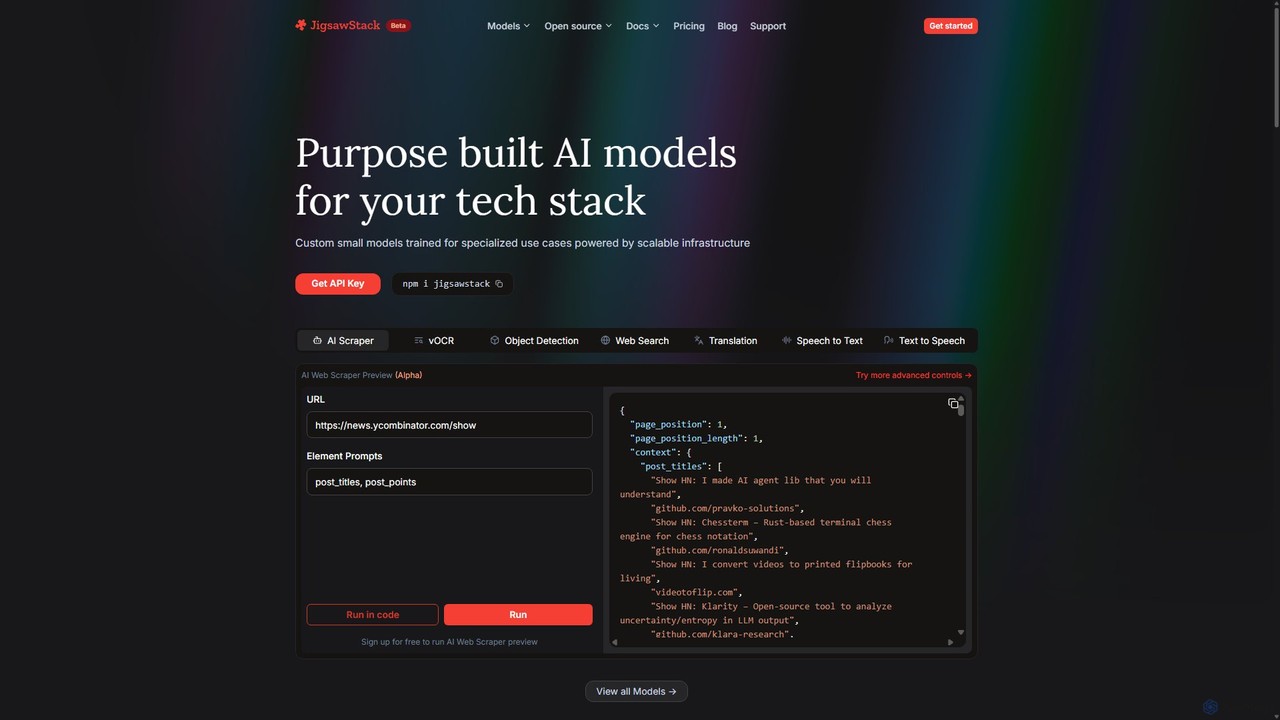
JigsawStack
JigsawStack為開發者提供一套透過單一API存取的專用小型AI模型。它透過快速、可靠和可擴展的基礎設施,簡化了網頁抓取、OCR、翻譯和語音轉文字等複雜的後端任務。該工具專為無縫整合而設計,提供開發者優先的體驗、結構化的資料輸出和全球支援,使團隊能夠更快地建構和發布功能。
JigsawStack為開發者提供一套透過單一API存取的專用小型AI模型。它透過快速、可靠和可擴展的基礎設施,簡化了網頁抓取、OCR、翻譯和語音轉文字等複雜的後端任務。該工具專為無縫整合而設計,提供開發者優先的體驗、結構化的資料輸出和全球支援,使團隊能夠更快地建構和發布功能。
Speechllect
Speechllect 是一款先進的由人工智能驅動的語音轉文字(STT)和文字轉語音(TTS)平台。它利用獨特的「感知理論」,不僅能轉錄和合成語音,還能理解並生成情感聲調和語調。這使其成為為企業、開發者和內容創作者創建類人語音互動的理想選擇。
Speechllect 是一款先進的由人工智能驅動的語音轉文字(STT)和文字轉語音(TTS)平台。它利用獨特的「感知理論」,不僅能轉錄和合成語音,還能理解並生成情感聲調和語調。這使其成為為企業、開發者和內容創作者創建類人語音互動的理想選擇。
TextSynth
TextSynth 透過靈活的 REST API 和互動式 Playground,為開發者提供強大且具成本效益的 AI 模型套件存取權限,包括大型語言模型 (LLM)、文字轉圖像、文字轉語音和語音轉文字。它提供 Llama、Mistral、Stable Diffusion 和 Whisper 等模型,並針對速度和可負擔性進行了優化。
TextSynth 透過靈活的 REST API 和互動式 Playground,為開發者提供強大且具成本效益的 AI 模型套件存取權限,包括大型語言模型 (LLM)、文字轉圖像、文字轉語音和語音轉文字。它提供 Llama、Mistral、Stable Diffusion 和 Whisper 等模型,並針對速度和可負擔性進行了優化。
WaveSpeedAI
WaveSpeedAI 是一個高效能、統一的 API 平台,旨在加速 AI 圖像、影片和音訊的生成。它為開發者和創作者提供了一個單一入口,以存取來自谷歌、字節跳動和快手等供應商的龐大尖端模型庫,從而實現更快地構建、創建和擴展多模態 AI 應用。
WaveSpeedAI 是一個高效能、統一的 API 平台,旨在加速 AI 圖像、影片和音訊的生成。它為開發者和創作者提供了一個單一入口,以存取來自谷歌、字節跳動和快手等供應商的龐大尖端模型庫,從而實現更快地構建、創建和擴展多模態 AI 應用。
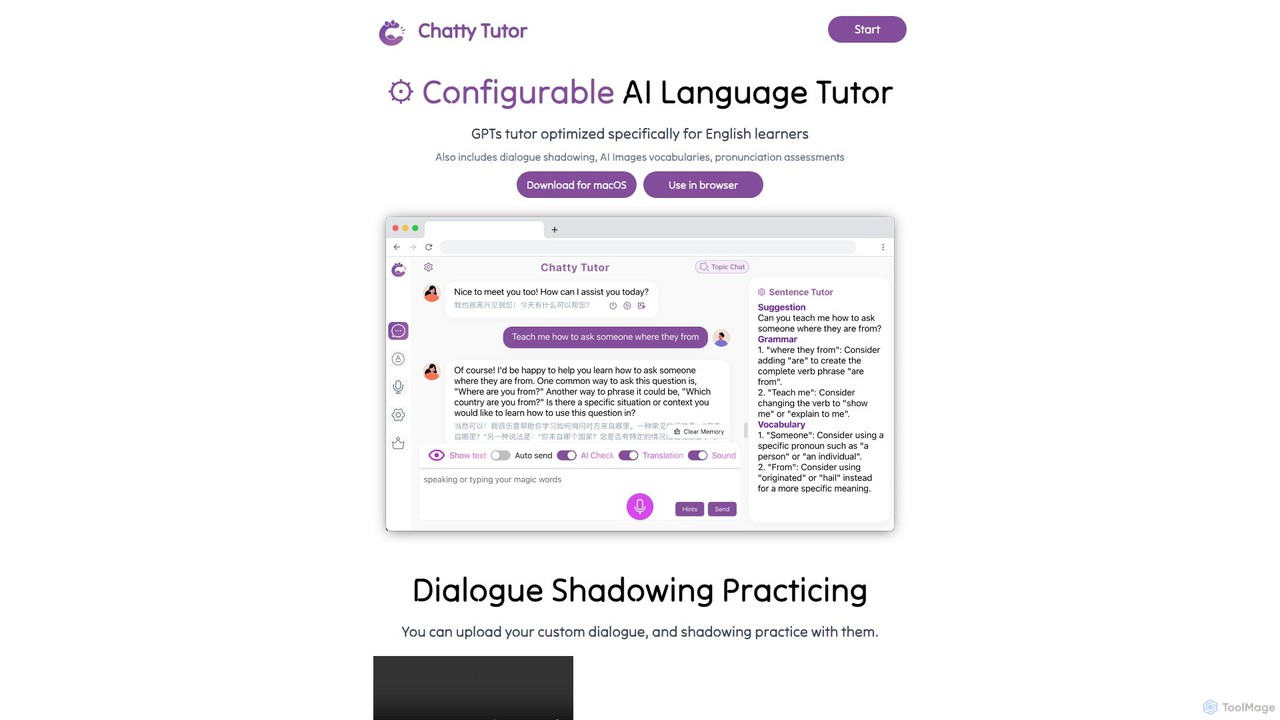
ChattyTutor
ChattyTutor 是一款由 GPT 驅動、高度可配置的 AI 語言導師,專為英語學習者優化。它提供對話跟讀、發音評估和 AI 圖像詞彙記憶等互動功能,支援 macOS 和網頁瀏覽器。
ChattyTutor 是一款由 GPT 驅動、高度可配置的 AI 語言導師,專為英語學習者優化。它提供對話跟讀、發音評估和 AI 圖像詞彙記憶等互動功能,支援 macOS 和網頁瀏覽器。
Text Generator
Text Generator 是一個功能多樣且極具性價比的AI平台,提供無限制的文本、程式碼和語音生成。它提供強大的API,包括一個與OpenAI相容的端點以便輕鬆遷移,是為開發者、行銷人員和內容創作者打造的經濟高效的解決方案。
Text Generator 是一個功能多樣且極具性價比的AI平台,提供無限制的文本、程式碼和語音生成。它提供強大的API,包括一個與OpenAI相容的端點以便輕鬆遷移,是為開發者、行銷人員和內容創作者打造的經濟高效的解決方案。

MiniMax
MiniMax是一家AI研究公司,提供由AGI驅動的基礎模型的全棧平台。它為文字(MiniMax-M1,支援100萬上下文)、影片(海螺02)和語音(Speech 02)提供頂尖的API,同時還提供一套免費的AI原生應用,如MiniMax聊天、智慧體和創意工具。它專注於為開發者和終端使用者提供高效能、高計算效率和高性價比的解決方案。
MiniMax是一家AI研究公司,提供由AGI驅動的基礎模型的全棧平台。它為文字(MiniMax-M1,支援100萬上下文)、影片(海螺02)和語音(Speech 02)提供頂尖的API,同時還提供一套免費的AI原生應用,如MiniMax聊天、智慧體和創意工具。它專注於為開發者和終端使用者提供高效能、高計算效率和高性價比的解決方案。
關於 語音合成
語音合成工具是一類利用人工智能技術將書面文本轉化為自然人聲語音的系統。這些工具基於先進的深度學習模型和神經網絡,能夠生成具有可定制音色、情感和語言的音頻輸出。它們廣泛應用於自動化配音、增強無障礙功能以及在各種數字平台創建交互式用戶體驗。
核心功能
- 文本轉語音(TTS):將輸入的文本轉換為口語音頻,通常提供多種音色和說話風格選項。
- 聲音定制:允許用戶從一系列預設聲音中選擇,甚至創建自定義聲音配置文件以匹配特定的品牌形象。
- 多語言支持:生成多種語言和方言的語音,滿足全球受眾和多樣化的內容需求。
- 情感表達:在合成語音中融入喜悅、悲傷或憤怒等情感細微差別,使交互更加逼真。
- SSML(語音合成標記語言)支持:提供對發音、強調、停頓和語速的精細控制,實現高度定制化的音頻輸出。
適用場景
語音合成工具對內容創作者、開發者和企業都具有不可估量的價值。它們能夠快速製作電子學習模塊、播客和視頻旁白的音頻內容。開發者將這些工具集成到應用程序中,為視障用戶構建無障礙功能,或為智能設備和聊天機器人創建更具吸引力的語音界面。
選擇要點
選擇語音合成工具時,應考慮生成語音的自然度和質量、語言和口音支持的廣度以及情感表達的可用性。評估通過API集成的便捷性、聲音定制選項的靈活性,並根據您的使用量和特定功能需求來考量定價模式。
語音合成應用場景
自動化有聲讀物和播客旁白
內容創作者和出版商可以使用語音合成工具,將書面手稿快速轉換為高品質的有聲讀物或播客節目。通過選擇合適的音色並調整語速、語調等參數,他們無需真人配音演員即可製作引人入勝的音頻內容,顯著縮短製作時間和成本,同時擴大受眾範圍。
增強視障用戶的無障礙體驗
開發者將語音合成API集成到應用程式、網站和操作系統中,以提供屏幕閱讀功能。這使得視障用戶能夠將數字文本內容,如文章、電子郵件或導航指令,朗讀出來。此應用顯著提升了數字無障礙性和包容性,使更廣泛的受眾能夠獨立獲取信息。
為視頻內容和在線學習創建畫外音
視頻製作人和在線學習課程創建者利用語音合成技術,為其多媒體項目生成專業聽感的畫外音。他們無需聘請配音人才或親自錄製,只需輸入腳本即可獲得多種語言和音色的音頻文件。這簡化了全球內容的本地化流程,並確保所有學習模塊或視頻片段的語音質量保持一致。
開發交互式語音應答(IVR)系統
企業利用語音合成技術為其交互式語音應答(IVR)系統提供支持,實現自動化客戶服務和支持。公司無需預先錄製所有可能的短語,而是可以根據客戶查詢動態生成響應。這確保了品牌聲音的一致性,減少了對大量配音庫的需求,並允許快速更新IVR腳本,從而提升客戶體驗和運營效率。
創建動態語音警報和通知
應用程式和智能設備可以利用語音合成技術為用戶生成實時語音警報和通知。例如,智能家居系統可以播報門已打開,或者導航應用可以提供逐向指引。這為用戶提供了一種無需動手、無需看屏幕的方式來接收關鍵信息,在駕駛或日常家務等各種場景中提升了便利性和安全性。
個性化數字助理和聊天機器人
開發者和產品經理利用語音合成技術,為數字助理(如Siri或Alexa)和聊天機器人賦予獨特、可識別的聲音和個性。通過定制音色、語調甚至情感變化,他們可以創造更具吸引力和人性化的交互體驗。這種個性化有助於建立用戶信任,使技術感覺更直觀、更少機器人化,從而提高整體用戶滿意度。