Dcompute
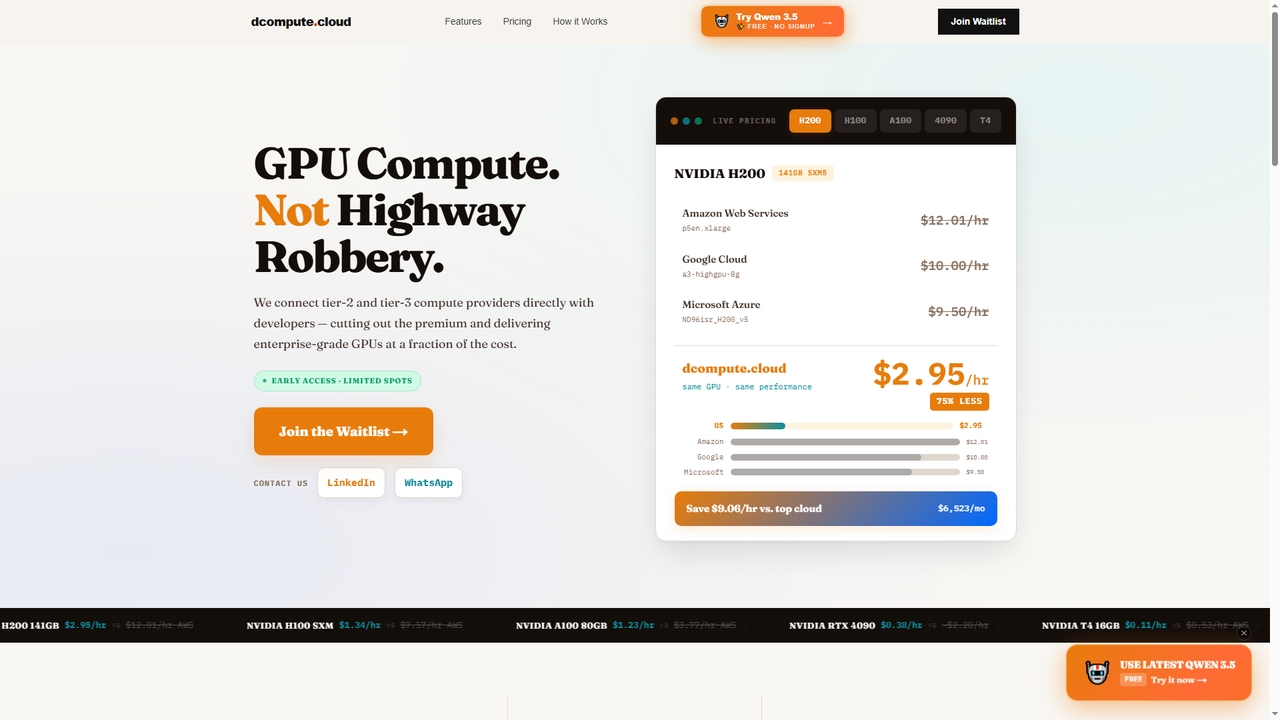
Dcompute 是一個去中心化的 GPU 計算市場,直接將開發者與二級和三級資料中心供應商連接起來。它以主流雲服務商幾分之一的价格提供企業級 NVIDIA GPU(H200、H100、A100、RTX 4090、T4),承諾最高可節省 90% 的成本。該平台支援即時部署、統一的 API/儀表板、全流程編排,並按秒計費,無最低消費。
Dcompute 是一個去中心化的 GPU 計算市場,直接將開發者與二級和三級資料中心供應商連接起來。它以主流雲服務商幾分之一的价格提供企業級 NVIDIA GPU(H200、H100、A100、RTX 4090、T4),承諾最高可節省 90% 的成本。該平台支援即時部署、統一的 API/儀表板、全流程編排,並按秒計費,無最低消費。
Avian
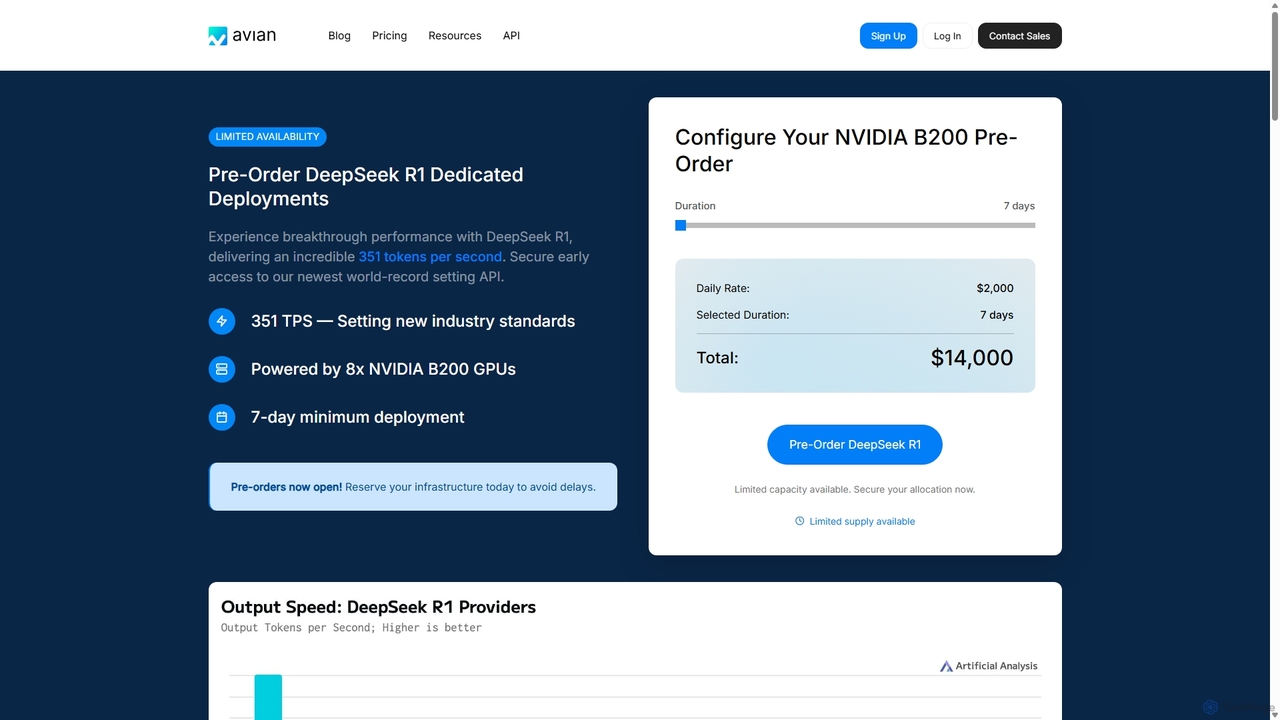
Avian 是一個高效能 AI 推理平台,為大型語言模型(LLM)提供世界紀錄級的速度。它既為流行模型提供無伺服器 API,也為來自 HuggingFace 的自訂模型提供專用 GPU 部署。Avian 專為可擴展性和生產工作負載而設計,推理速度比行業平均水平快 3-10 倍,並提供企業級安全和具競爭力的價格。
Avian 是一個高效能 AI 推理平台,為大型語言模型(LLM)提供世界紀錄級的速度。它既為流行模型提供無伺服器 API,也為來自 HuggingFace 的自訂模型提供專用 GPU 部署。Avian 專為可擴展性和生產工作負載而設計,推理速度比行業平均水平快 3-10 倍,並提供企業級安全和具競爭力的價格。
關於 GPU
GPU(圖形處理器)是一種專門的處理器,對於加速計算密集型任務至關重要,尤其是在人工智慧和機器學習領域。與通用CPU不同,GPU採用大規模並行架構,能夠同時處理多個數據點。這使得它們在訓練複雜的AI模型、渲染高保真圖形以及在雲端運算環境中執行大規模數據分析方面不可或缺。GPU處理並行工作負載的能力顯著縮短了處理時間,並提升了高級AI應用的性能。
核心功能
- 大規模並行架構:實現數千個執行緒同時處理,適用於數據密集型任務。
- 高記憶體頻寬:提供快速數據存取,對大型數據集和複雜模型至關重要。
- 專用核心(Tensor/CUDA):針對矩陣乘法和深度學習等特定AI操作進行優化。
- 浮點性能:為科學計算和AI模型訓練提供卓越的速度。
適用場景
GPU廣泛應用於深度學習模型訓練、科學模擬和即時數據處理。它們為自然語言處理、電腦視覺和推薦系統等AI驅動應用提供動力。在雲端運算中,GPU作為服務提供,為各種高性能工作負載提供可擴展的按需計算能力。
選擇要點
選擇GPU需要考慮其用於AI任務的CUDA/Tensor核心數量、用於大型模型的記憶體容量(VRAM)以及用於數據吞吐量的記憶體頻寬。與現有軟體框架(如TensorFlow、PyTorch)的兼容性以及雲端部署的能效也是關鍵因素。根據您的具體工作負載需求評估性價比。
GPU應用場景
加速深度學習模型訓練
數據科學家利用基於雲端的GPU顯著加速複雜神經網路的訓練,用於圖像識別或自然語言處理等任務。通過將工作負載分配到多個GPU實例,他們可以更快地迭代模型,將訓練時間從數天縮短到數小時,從而實現AI解決方案的更快速開發。
驅動科學模擬和高性能計算
研究人員和工程師利用雲中的GPU集群進行高性能計算任務,例如分子動力學模擬、天氣預報和計算流體動力學。GPU的並行處理能力使他們能夠以更高的精度和速度運行複雜的模擬,從而在各個科學領域取得突破。
實現即時AI推理和分析
企業部署GPU加速實例,用於欺詐檢測、個性化推薦或自動駕駛等應用中的即時AI推理。GPU提供低延遲處理能力,能夠即時執行訓練好的AI模型,提供對時間敏感操作至關重要的即時洞察和響應。
增強影片渲染和3D內容創作
內容創作者和動畫工作室利用雲GPU進行3D渲染、影片編輯和視覺效果等高要求任務。GPU強大的處理能力顯著縮短了渲染時間,使藝術家能夠更高效地製作高品質的視覺內容,並按時完成緊張的製作期限。
加速大規模數據分析
數據分析師和企業利用GPU加速大規模數據集的處理和分析,特別是在金融建模、基因組學和市場趨勢預測等領域。GPU處理並行數據轉換和複雜查詢的速度遠超CPU,從而能更快地從大數據中獲取洞察。
在邊緣部署AI模型
開發人員利用專門的、更小的GPU將AI模型部署到邊緣設備上,例如智能攝像頭、物聯網傳感器或工業機器人。這些GPU支持本地、實時的推理,無需持續的雲連接,從而提高了隱私性,降低了延遲,並優化了邊緣AI應用的頻寬使用。