
Browserless
Browserless 是一個強大的瀏覽器即服務 (BaaS) 平台,專為可擴展的網頁抓取和瀏覽器自動化而設計。它幫助開發人員使用 Puppeteer、Playwright 或其專有的 BrowserQL 語言輕鬆繞過驗證碼和機器人偵測器。該服務負責管理瀏覽器基礎設施,讓用戶可以專注於建構自動化腳本,而無需擔心更新、記憶體洩漏或擴展問題。
Browserless 是一個強大的瀏覽器即服務 (BaaS) 平台,專為可擴展的網頁抓取和瀏覽器自動化而設計。它幫助開發人員使用 Puppeteer、Playwright 或其專有的 BrowserQL 語言輕鬆繞過驗證碼和機器人偵測器。該服務負責管理瀏覽器基礎設施,讓用戶可以專注於建構自動化腳本,而無需擔心更新、記憶體洩漏或擴展問題。



Apify
Apify 是一個全端式網路爬蟲和自動化平台,使開發人員能夠建構、部署和發布被稱為「Actor」的資料提取工具。它提供了一個龐大的預建構爬蟲市場,適用於 Google 地圖、Instagram 和 TikTok 等熱門網站,並配有強大的雲端基礎設施用於創建自訂解決方案。憑藉對 Python 和 JavaScript、開源函式庫以及無縫整合的支援,Apify 簡化了任何規模的網路資料收集過程。
Apify 是一個全端式網路爬蟲和自動化平台,使開發人員能夠建構、部署和發布被稱為「Actor」的資料提取工具。它提供了一個龐大的預建構爬蟲市場,適用於 Google 地圖、Instagram 和 TikTok 等熱門網站,並配有強大的雲端基礎設施用於創建自訂解決方案。憑藉對 Python 和 JavaScript、開源函式庫以及無縫整合的支援,Apify 簡化了任何規模的網路資料收集過程。

Genlogin
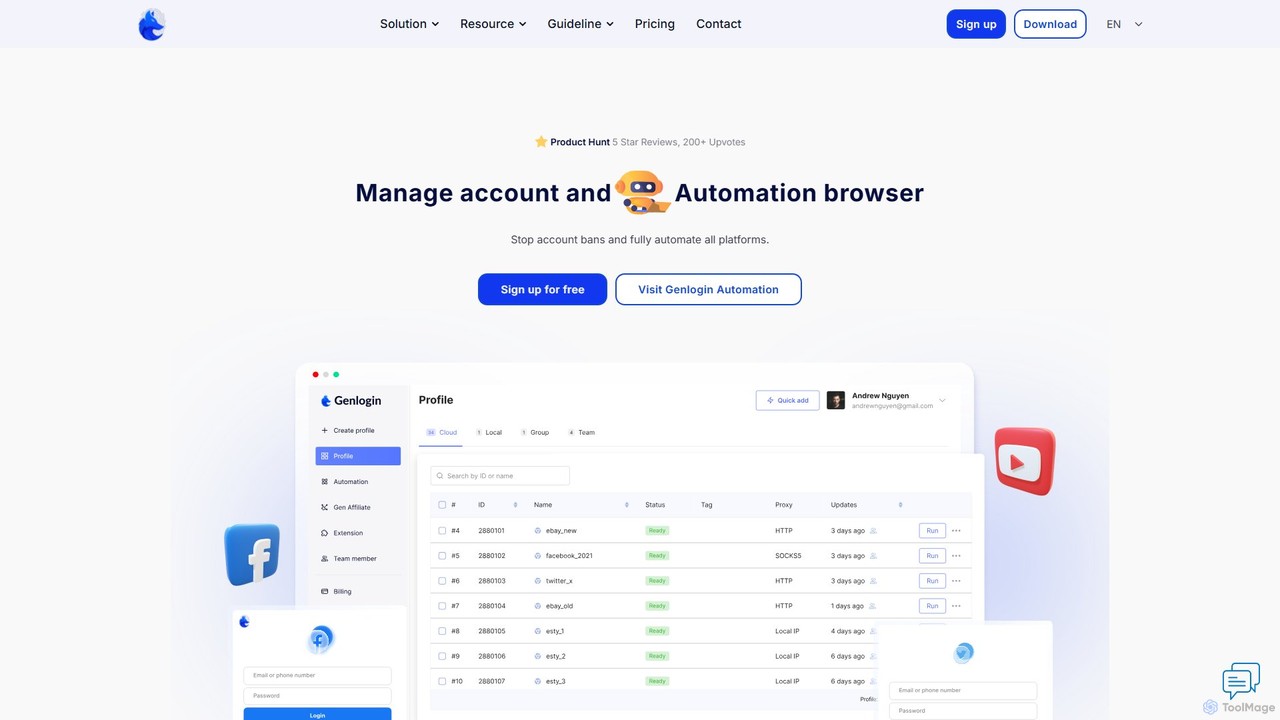
Genlogin是一款先進的防關聯瀏覽器,專為安全高效地管理多個線上帳戶而設計。它透過為每個設定檔建立獨特的、基於真實數據的瀏覽器指紋來防止帳戶被封。憑藉無程式碼自動化、即時操作同步和內建代理服務等功能,Genlogin是電子商務、社群媒體行銷、資料抓取和聯盟行銷的理想選擇,助力使用者擴展其線上業務。
Genlogin是一款先進的防關聯瀏覽器,專為安全高效地管理多個線上帳戶而設計。它透過為每個設定檔建立獨特的、基於真實數據的瀏覽器指紋來防止帳戶被封。憑藉無程式碼自動化、即時操作同步和內建代理服務等功能,Genlogin是電子商務、社群媒體行銷、資料抓取和聯盟行銷的理想選擇,助力使用者擴展其線上業務。

WebScraping.AI
WebScraping.AI 是一款面向開發人員的高階API,利用AI簡化網路爬蟲。它具備輪換代理、JavaScript渲染和地理定位功能,可繞過封鎖並存取動態內容。其核心優勢在於由LLM驅動的工具,能直接從網頁中提取非結構化資料、產生摘要並回答問題,極大地簡化了任何專案的資料收集流程。
WebScraping.AI 是一款面向開發人員的高階API,利用AI簡化網路爬蟲。它具備輪換代理、JavaScript渲染和地理定位功能,可繞過封鎖並存取動態內容。其核心優勢在於由LLM驅動的工具,能直接從網頁中提取非結構化資料、產生摘要並回答問題,極大地簡化了任何專案的資料收集流程。

FetchFox
FetchFox 是一款由人工智能驅動的網頁抓取工具,使用者只需使用簡單的文字提示即可從任何網站擷取資料。它無需複雜的編碼或CSS選擇器,並能自動處理反機器人措施。該工具提供API、JavaScript庫和Chrome擴充功能,專為開發人員和非技術使用者設計,可輕鬆實現資料收集自動化。
FetchFox 是一款由人工智能驅動的網頁抓取工具,使用者只需使用簡單的文字提示即可從任何網站擷取資料。它無需複雜的編碼或CSS選擇器,並能自動處理反機器人措施。該工具提供API、JavaScript庫和Chrome擴充功能,專為開發人員和非技術使用者設計,可輕鬆實現資料收集自動化。

CapSolver
CapSolver 是一款由人工智慧驅動的自動驗證碼識別服務,專為開發人員和RPA專業人士設計。它提供高準確率、快速且可擴展的解決方案,用於繞過包括 reCAPTCHA、hCaptcha 和 FunCaptcha 在內的各種驗證碼,從而實現無縫的網頁抓取、資料提取和流程自動化。
CapSolver 是一款由人工智慧驅動的自動驗證碼識別服務,專為開發人員和RPA專業人士設計。它提供高準確率、快速且可擴展的解決方案,用於繞過包括 reCAPTCHA、hCaptcha 和 FunCaptcha 在內的各種驗證碼,從而實現無縫的網頁抓取、資料提取和流程自動化。
Multilogin
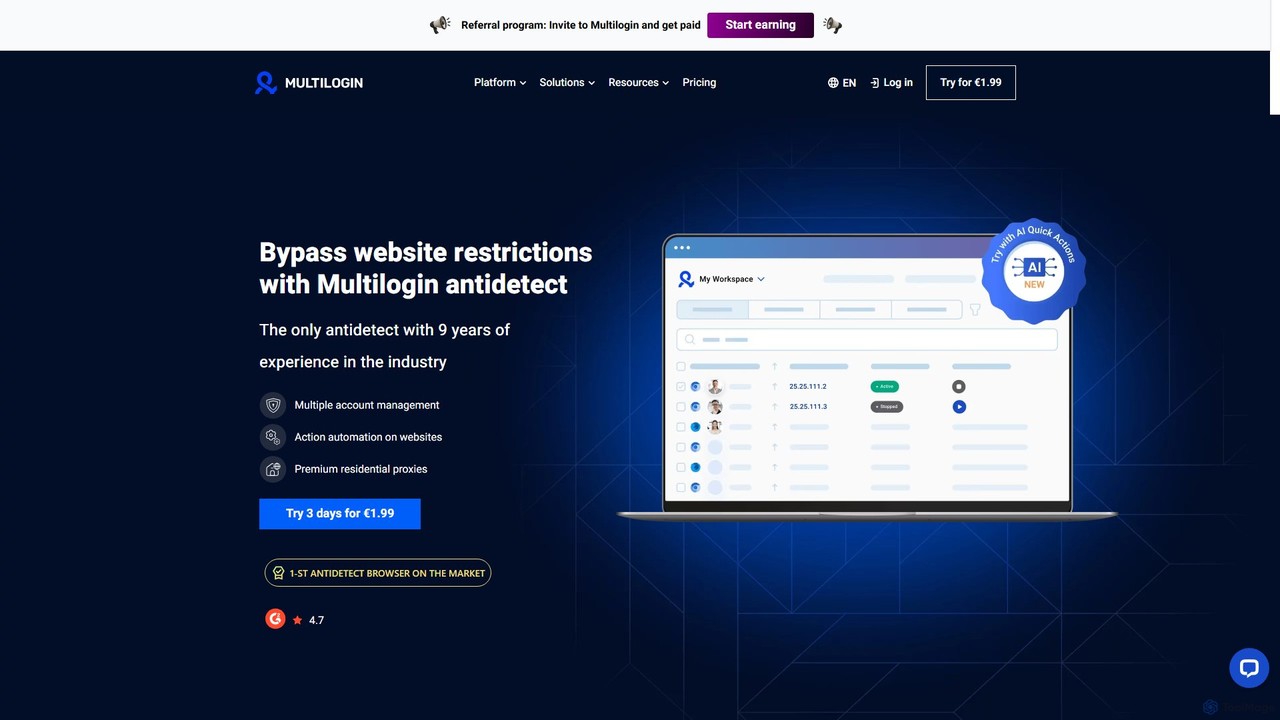
Multilogin是一款領先的防關聯瀏覽器,允許使用者建立和管理多個獨特的瀏覽器設定檔。它透過偽裝數位指紋來防止網站限制和帳戶封鎖,是社群媒體行銷、電子商務、網頁抓取和其他多帳戶操作的理想選擇。它包含團隊協作、自動化支援和內建住宅代理等功能。
Multilogin是一款領先的防關聯瀏覽器,允許使用者建立和管理多個獨特的瀏覽器設定檔。它透過偽裝數位指紋來防止網站限制和帳戶封鎖,是社群媒體行銷、電子商務、網頁抓取和其他多帳戶操作的理想選擇。它包含團隊協作、自動化支援和內建住宅代理等功能。

ScrapingBee
ScrapingBee 是一款功能強大的網路爬蟲 API,可處理無頭瀏覽器和代理輪換,以防止被封鎖。它具有創新的 AI 驅動提取器,讓您可以用簡單的英語描述所需數據,無需使用複雜的 CSS 選擇器。非常適合開發人員、行銷人員和數據分析師用於價格監控、潛在客戶開發和搜尋引擎結果頁面(SERP)分析等任務。
ScrapingBee 是一款功能強大的網路爬蟲 API,可處理無頭瀏覽器和代理輪換,以防止被封鎖。它具有創新的 AI 驅動提取器,讓您可以用簡單的英語描述所需數據,無需使用複雜的 CSS 選擇器。非常適合開發人員、行銷人員和數據分析師用於價格監控、潛在客戶開發和搜尋引擎結果頁面(SERP)分析等任務。

URLtoText
URLtoText 是一款由AI驅動的工具,可從任何網站或PDF中提取乾淨、結構化的文本。它能智能地移除廣告、側邊欄和其他雜亂內容,僅提供核心正文。該工具具備JavaScript渲染、住宅IP代理和開發者API等功能,專為需要從靜態和動態網頁中可靠提取數據的研究人員、開發者和企業設計。
URLtoText 是一款由AI驅動的工具,可從任何網站或PDF中提取乾淨、結構化的文本。它能智能地移除廣告、側邊欄和其他雜亂內容,僅提供核心正文。該工具具備JavaScript渲染、住宅IP代理和開發者API等功能,專為需要從靜態和動態網頁中可靠提取數據的研究人員、開發者和企業設計。
關於 網頁抓取
網頁抓取工具是一類利用AI技術自動從網站提取數據的解決方案。這些工具通常結合自然語言處理和機器學習等高級演算法,能夠智能地瀏覽網頁,識別並收集結構化或非結構化的資訊。它們對於自動化繁瑣的手動數據收集至關重要,為各種分析需求提供可擴展且高效的數據獲取能力。這種能力使得它們對於希望從海量公共網路數據中獲取洞察的企業和研究人員來說價值非凡。
核心功能
- 自動化數據提取:系統地從網頁中收集文本、圖片和連結等特定數據點。
- 動態內容處理:能夠與JavaScript渲染的內容、表單和分頁進行交互,以訪問所有相關數據。
- 反抓取規避:採用技術規避常見的反爬措施,例如驗證碼和IP封鎖。
- 數據結構化與導出:將提取的數據整理成CSV、JSON或XML等可用格式,便於分析和集成。
- 任務調度與監控:允許用戶安排抓取任務,並監控網站以獲取最新或更新的資訊。
適用場景
網頁抓取工具廣泛應用於企業市場情報收集,使其能夠實時監控競爭對手的定價和產品資訊。它們對於學術研究人員從公共資源收集大量數據集進行統計分析也至關重要。電子商務平台利用這些工具進行實時價格監控和跨多個線上零售商的庫存追蹤。
選擇要點
選擇網頁抓取工具時,需考慮其處理目標網站複雜性(包括動態內容和反抓取措施)的能力。根據所需數據量和頻率,評估其可擴展性和調度功能。考察其易用性,無論是透過無程式碼界面還是為開發者提供的強大API。最後,確保該工具支持道德抓取實踐並符合數據隱私法規。
網頁抓取應用場景
電商競爭對手價格監控
電商企業利用網頁抓取工具持續監控各個線上平台上的競爭對手定價。這使他們能夠追蹤價格變化,識別促銷優惠,並實時調整自己的定價策略以保持競爭力。透過自動化此過程,企業可以節省大量手動工作,並確保其產品始終以最優價格提供,從而提高銷售額和市場份額。
潛在客戶生成與銷售情報
銷售和行銷團隊利用網頁抓取從公共目錄、專業社交網站或行業特定入口網站中提取有價值的潛在客戶資訊。這包括聯繫方式、公司簡介和職位,然後用於建立有針對性的潛在客戶列表。自動化潛在客戶生成顯著減少了手動數據輸入的時間,使銷售專業人員能夠專注於互動和轉化,從而提高銷售渠道效率。
市場研究與趨勢分析
研究人員和分析師利用網頁抓取從新聞文章、論壇、社交媒體和評論網站收集大量公共數據。這些數據隨後用於情感分析、趨勢識別和競爭情報。透過自動化數據收集,他們可以快速獲取消費者意見、新興市場趨勢以及品牌或產品公眾認知的最新資訊,從而做出更明智的戰略決策。
新聞入口網站內容聚合
媒體公司和新聞聚合器利用網頁抓取工具自動從各種新聞來源和部落格收集文章、頭條、圖片和影片。這使他們能夠用新鮮、多樣化的內容填充自己的新聞源或內容平台,而無需手動策劃。自動化確保了資訊的持續流動,使受眾保持參與和知情,同時顯著減少了編輯工作量。
房地產掛牌資訊分析
房地產專業人士和投資者利用網頁抓取從多個線上平台(包括房地產入口網站和分類廣告)收集房產掛牌資訊。這些聚合數據有助於進行全面的市場分析,識別不同地區房產價值、租金和可用性的趨勢。透過自動化數據收集,他們可以更快、更明智地做出房產收購、銷售和投資策略決策,從而獲得競爭優勢。
學術研究數據收集
學者和研究人員經常使用網頁抓取來為其研究構建大型數據集。這涉及從科學出版物、政府數據庫、公共檔案和專業論壇中提取資訊。從各種線上來源快速收集和結構化大量數據的能力對於實證研究、統計分析和驗證假設至關重要,顯著加速了研究過程並實現了更深入的洞察。