




Crawlbase 概覽
Crawlbase 是一個全面的人工智慧驅動平台,旨在普及網路資料的存取。它使開發人員、資料科學家和企業能夠大規模地爬取和擷取網際網路,將非結構化的網路內容轉化為乾淨、結構化的資料。透過處理代理、瀏覽器自動化和反機器人系統等複雜的基礎設施,Crawlbase 允許使用者專注於資料利用。該平台建立在全球數百萬個輪換的住宅和資料中心代理之上,確保對亞馬遜、領英、谷歌等網站的匿名和無限制存取,並保證99.9%的正常運行時間。
如何使用Crawlbase
將 Crawlbase 整合到您的工作流程中非常簡單,只需幾分鐘即可完成:
- 建立帳戶: 註冊一個免費的 Crawlbase 帳戶。您將收到一個用於身份驗證的API權杖。初始計劃包含1000次免費請求,無需信用卡即可測試服務。
- 選擇合適的工具: 根據您的需求選擇相應的產品。使用爬蟲API (Crawling API) 進行即時的同步資料請求。對於大規模、持續性的專案,非同步的爬蟲 (Crawler) 更具成本效益。如果您的應用程式需要一個簡單的代理閘道,智慧代理 (Smart Proxy) 是理想選擇。
- 發出API請求: 向 Crawlbase 端點發出一個簡單的API呼叫,傳遞您的API權杖和您希望擷取的目標URL。您可以包含各種參數以啟用JavaScript渲染、設定地理位置或使用特定的資料擷取器。
- 接收資料: Crawlbase 處理請求,繞過封鎖、代理和驗證碼。然後,它會返回頁面的完整HTML內容,或者在使用特定擷取器(如亞馬遜擷取器)時,以結構化的JSON格式提供資料。
Crawlbase的核心功能
- 爬蟲API (Crawling API): 一個功能強大、易於使用的API,可即時獲取網頁內容。它支援動態網站的JavaScript渲染,並包含針對亞馬遜等熱門網站的內建擷取器,可直接提供結構化資料。
- 爬蟲 (The Crawler): 一種專為海量資料提取專案設計的非同步爬蟲解決方案。它使用回呼將資料傳送到您的伺服器,為大量URL節省成本、頻寬和重試次數。
- 智慧代理 (Smart Proxy): 一種輪換代理解決方案,提供對數百萬個資料中心和住宅IP的存取。它可以輕鬆整合到任何需要可靠代理以避免被封鎖的應用程式或腳本中。
- AI驅動的反封鎖技術: 先進的演算法和機器學習模型,可自動處理IP封鎖、瀏覽器指紋、驗證碼和其他反擷取措施,確保高成功率。
- 雲端儲存: 一項便捷功能,允許您將爬取和擷取的資料直接移動到 Crawlbase 的安全雲端儲存中,簡化您的資料管道。
- 全球地理定位: 從超過30個不同國家存取網路內容,使您能夠執行本地化搜尋並收集特定區域的資料。
Crawlbase的使用案例
Crawlbase 用途廣泛,支援各種資料驅動的商業活動:
- 電子商務與零售: 監控競爭對手定價、追蹤產品可用性、匯總客戶評論,並分析來自亞馬遜、eBay和沃爾瑪等平台的產品資料,以優化銷售策略。
- 市場研究: 收集海量資料用於市場趨勢分析、社群媒體和論壇的情感分析,以及識別新興商業機會。
- 潛在客戶開發: 自動化從領英等專業網路、線上目錄和公司網站收集聯絡資訊和業務詳情的過程。
- 人工智慧與機器學習: 為訓練生成式AI和大型語言模型(LLM)提供高品質、結構化的資料集。該API可以高效地收集所需的大量文本和圖像資料。
- SEO監控: 跨不同搜尋引擎和地理位置追蹤關鍵詞排名,分析競爭對手的SEO策略,並執行全面的網站審計而不會被封鎖。
Crawlbase的優勢特點
Crawlbase 透過抽象化網路擷取的複雜性,提供了顯著的競爭優勢。使用者無需建立和維護昂貴且脆弱的內部基礎設施,而是受益於一個可靠、可擴展且具有成本效益的解決方案。該平台的主要優勢包括其龐大的代理網路、超過99%的高成功率、99.9%的正常運行時間保證以及全天候的專家支援。其開發者優先的方法確保了輕鬆整合和強大的文件,而其對合規性(GDPR和CCPA)的承諾則為企業提供了保障。
定價和計劃
Crawlbase 採用靈活透明的免費增值模式。新使用者可以從一個包含1000次免費請求的免費計劃開始,無需提供信用卡即可全面測試平台功能。免費試用後,定價基於按需付費系統,費用根據發出的請求數量和使用的功能(例如,標準請求與啟用JavaScript的請求)確定。對於有高資料需求的企業,Crawlbase 提供量身定制的企業計劃,提供自訂定價、專屬客戶經理和高級支援,以滿足特定的專案需求。
Crawlbase 評論 (0)
登入後即可發表評論
立即登入Crawlbase網站流量分析
最新流量情況
狀態
月度流量趨勢
地理位置
Top 5 國家/地區
-
🇩🇪 Germany25.71%
-
🇺🇸 United States21.96%
-
🇻🇳 Vietnam19.44%
-
🇮🇳 India18.42%
-
🇷🇺 Russia14.47%
流量來源
| 來源類型 | 百分比 |
|---|---|
|
直接訪問
|
76.37% |
|
郵件
|
14.64% |
|
外鏈引薦
|
8.99% |
熱門關鍵詞
| 關鍵詞 | 每次點擊費用 |
|---|---|
|
$0.83
|
|
|
$5.74
|
|
|
$0.00
|
|
|
$0.00
|
|
|
$0.00
|
Crawlbase 替代方案
查看全部
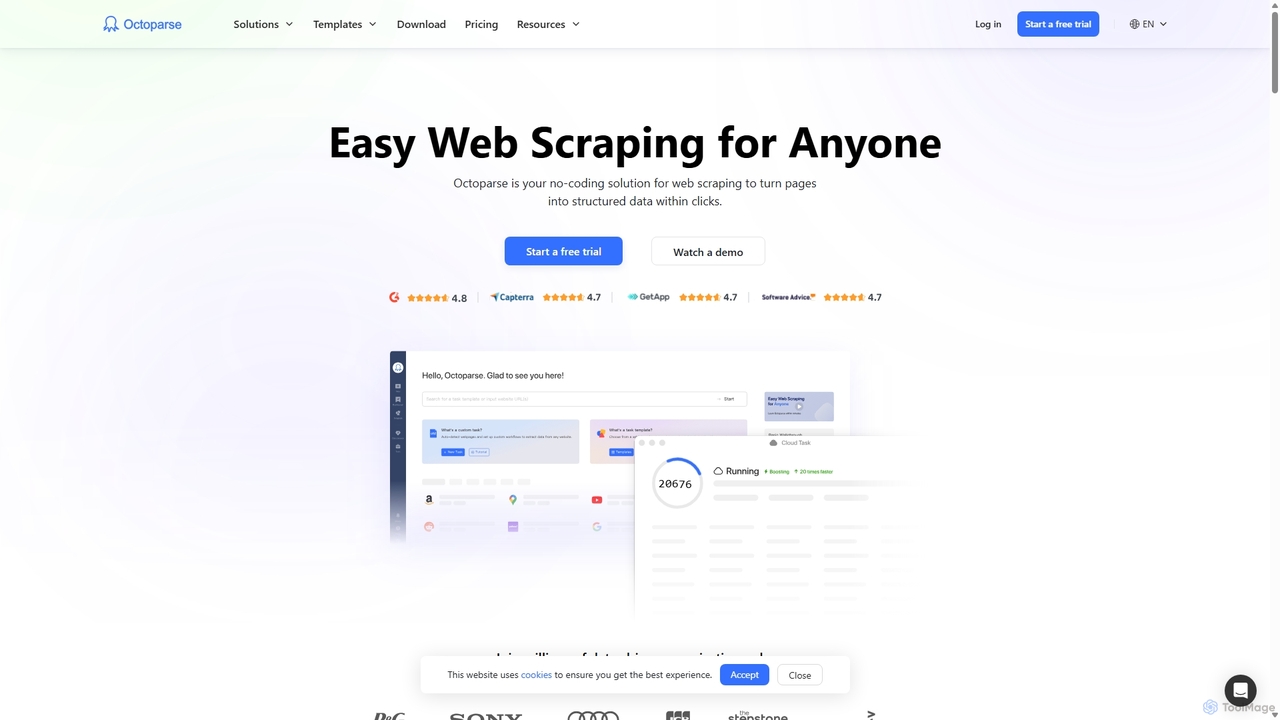
Octoparse
Octoparse是一款強大的無程式碼網頁抓取工具,任何人無需編程即可從網站擷取資料。它提供視覺化工作流程設計器、用於輕鬆設定的AI助理以及數百個適用於熱門網站的預建範本。藉助雲端自動化、IP輪換和驗證碼解決功能,Octoparse能高效處理複雜的抓取任務,將網頁轉化為結構化資料,用於潛在客戶開發、市場研究等。
Octoparse是一款強大的無程式碼網頁抓取工具,任何人無需編程即可從網站擷取資料。它提供視覺化工作流程設計器、用於輕鬆設定的AI助理以及數百個適用於熱門網站的預建範本。藉助雲端自動化、IP輪換和驗證碼解決功能,Octoparse能高效處理複雜的抓取任務,將網頁轉化為結構化資料,用於潛在客戶開發、市場研究等。

Browserless
Browserless 是一個強大的瀏覽器即服務 (BaaS) 平台,專為可擴展的網頁抓取和瀏覽器自動化而設計。它幫助開發人員使用 Puppeteer、Playwright 或其專有的 BrowserQL 語言輕鬆繞過驗證碼和機器人偵測器。該服務負責管理瀏覽器基礎設施,讓用戶可以專注於建構自動化腳本,而無需擔心更新、記憶體洩漏或擴展問題。
Browserless 是一個強大的瀏覽器即服務 (BaaS) 平台,專為可擴展的網頁抓取和瀏覽器自動化而設計。它幫助開發人員使用 Puppeteer、Playwright 或其專有的 BrowserQL 語言輕鬆繞過驗證碼和機器人偵測器。該服務負責管理瀏覽器基礎設施,讓用戶可以專注於建構自動化腳本,而無需擔心更新、記憶體洩漏或擴展問題。

FetchFox
FetchFox 是一款由人工智能驅動的網頁抓取工具,使用者只需使用簡單的文字提示即可從任何網站擷取資料。它無需複雜的編碼或CSS選擇器,並能自動處理反機器人措施。該工具提供API、JavaScript庫和Chrome擴充功能,專為開發人員和非技術使用者設計,可輕鬆實現資料收集自動化。
FetchFox 是一款由人工智能驅動的網頁抓取工具,使用者只需使用簡單的文字提示即可從任何網站擷取資料。它無需複雜的編碼或CSS選擇器,並能自動處理反機器人措施。該工具提供API、JavaScript庫和Chrome擴充功能,專為開發人員和非技術使用者設計,可輕鬆實現資料收集自動化。

Apify
Apify 是一個全端式網路爬蟲和自動化平台,使開發人員能夠建構、部署和發布被稱為「Actor」的資料提取工具。它提供了一個龐大的預建構爬蟲市場,適用於 Google 地圖、Instagram 和 TikTok 等熱門網站,並配有強大的雲端基礎設施用於創建自訂解決方案。憑藉對 Python 和 JavaScript、開源函式庫以及無縫整合的支援,Apify 簡化了任何規模的網路資料收集過程。
Apify 是一個全端式網路爬蟲和自動化平台,使開發人員能夠建構、部署和發布被稱為「Actor」的資料提取工具。它提供了一個龐大的預建構爬蟲市場,適用於 Google 地圖、Instagram 和 TikTok 等熱門網站,並配有強大的雲端基礎設施用於創建自訂解決方案。憑藉對 Python 和 JavaScript、開源函式庫以及無縫整合的支援,Apify 簡化了任何規模的網路資料收集過程。
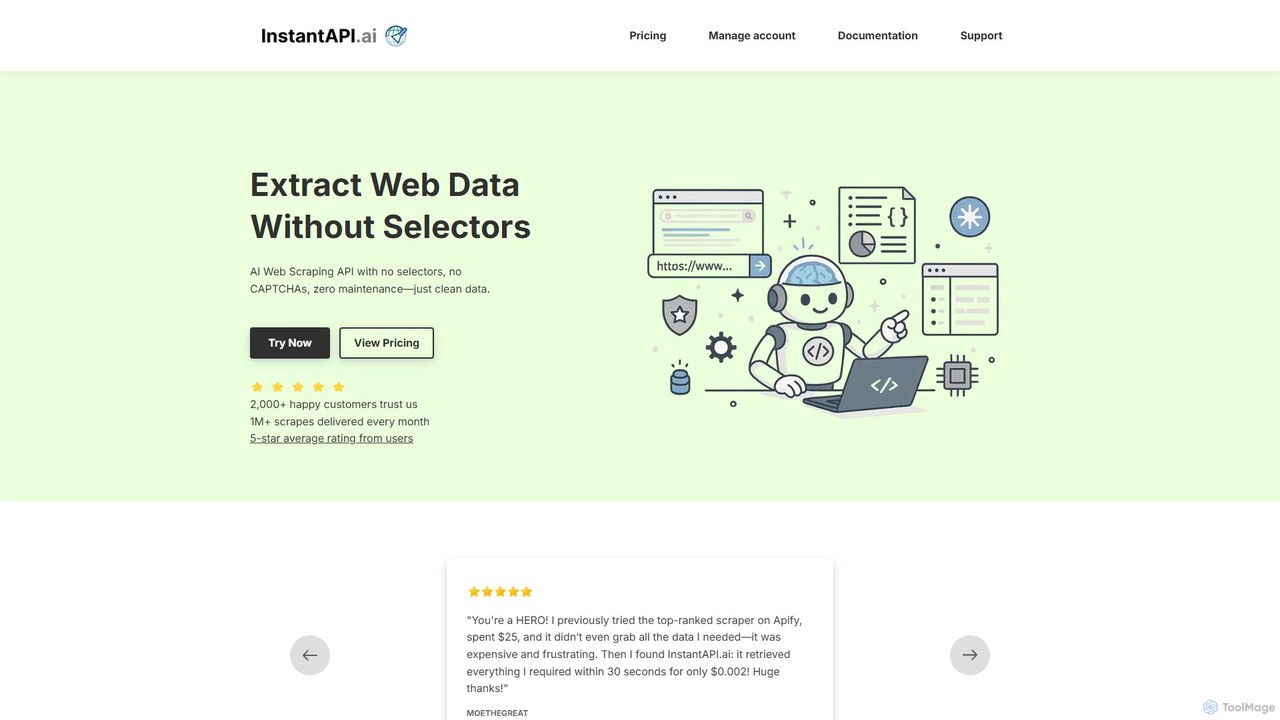
instantapi
instantapi 是一個由人工智能驅動的網頁抓取API,專為簡化和提速而設計。它允許用戶透過單個API調用從任何網站提取結構化數據,無需複雜的編碼或手動設定。對於需要快速、經濟、可靠的數據提取而又不想處理傳統網路爬蟲麻煩的開發人員、數據分析師和企業來說,這是一個理想的選擇。
instantapi 是一個由人工智能驅動的網頁抓取API,專為簡化和提速而設計。它允許用戶透過單個API調用從任何網站提取結構化數據,無需複雜的編碼或手動設定。對於需要快速、經濟、可靠的數據提取而又不想處理傳統網路爬蟲麻煩的開發人員、數據分析師和企業來說,這是一個理想的選擇。


ScrapingBee
ScrapingBee 是一款功能強大的網路爬蟲 API,可處理無頭瀏覽器和代理輪換,以防止被封鎖。它具有創新的 AI 驅動提取器,讓您可以用簡單的英語描述所需數據,無需使用複雜的 CSS 選擇器。非常適合開發人員、行銷人員和數據分析師用於價格監控、潛在客戶開發和搜尋引擎結果頁面(SERP)分析等任務。
ScrapingBee 是一款功能強大的網路爬蟲 API,可處理無頭瀏覽器和代理輪換,以防止被封鎖。它具有創新的 AI 驅動提取器,讓您可以用簡單的英語描述所需數據,無需使用複雜的 CSS 選擇器。非常適合開發人員、行銷人員和數據分析師用於價格監控、潛在客戶開發和搜尋引擎結果頁面(SERP)分析等任務。
Crawlbase AI工具
Crawlbase 嵌入功能
只需複製下方嵌入代碼,將精美徽章貼到您的博客、文章或應用官網,即可把流量直接引導到本工具詳情頁,快速提升曝光與用戶量!

還沒有評論,成為第一個評論者吧!