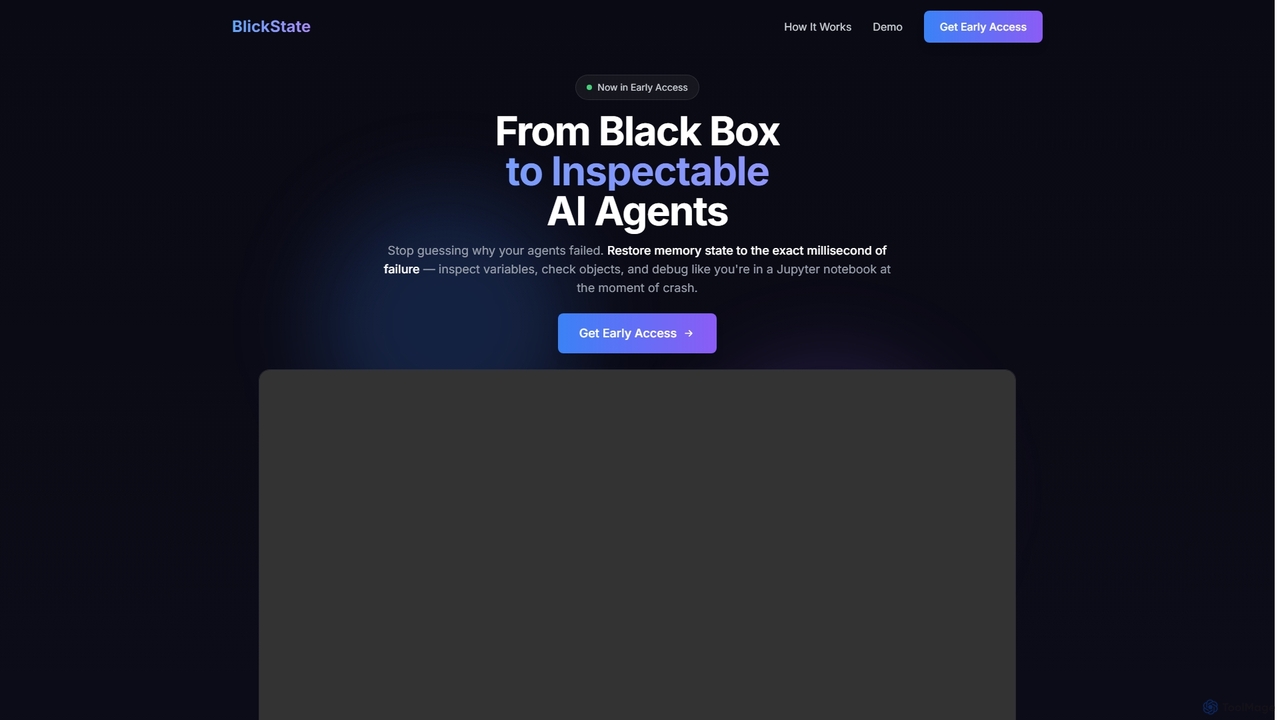
BlickState
BlickState ist ein fortschrittliches Zeitreise-Debugging-Tool für KI-Agenten, das Entwicklern ermöglicht, den vollständigen Speicherzustand von Agenten-Tool-Ausführungen im exakten Millisekundenbereich …
BlickState ist ein fortschrittliches Zeitreise-Debugging-Tool für KI-Agenten, das Entwicklern ermöglicht, den vollständigen Speicherzustand von Agenten-Tool-Ausführungen im exakten Millisekundenbereich eines Fehlers wiederherzustellen und zu inspizieren. Es verwandelt Black-Box-Agentenverhalten in transparente, überprüfbare Prozesse und beschleunigt das Debugging für KI-Ingenieure erheblich.
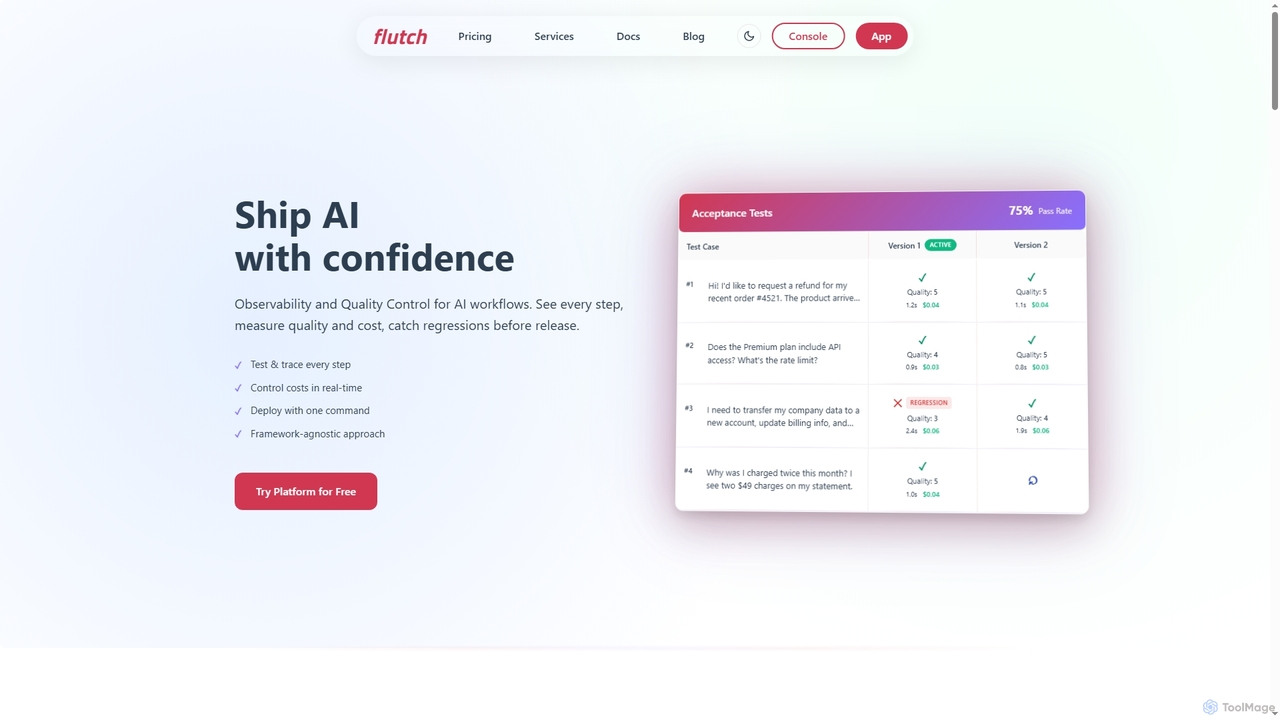
Flutch
Flutch ist eine umfassende Plattform für die Entwicklung, Bereitstellung und Verwaltung benutzerdefinierter KI-Agenten mit starkem Fokus auf Beobachtbarkeit, …
Flutch ist eine umfassende Plattform für die Entwicklung, Bereitstellung und Verwaltung benutzerdefinierter KI-Agenten mit starkem Fokus auf Beobachtbarkeit, Qualitätskontrolle und Kostenmanagement. Sie ermöglicht Entwicklern den Aufbau zuverlässiger KI-Workflows, die rigorose Prüfung von Agenten, die Echtzeitüberwachung der Leistung und die nahtlose Integration in bestehende Systeme, um sicherzustellen, dass KI-Lösungen mit Vertrauen ausgeliefert und effizient betrieben werden.
Splunk
Splunk ist der Schlüssel zur unternehmerischen Resilienz und bietet eine einheitliche, KI-gestützte Plattform für Sicherheit und Observability. Es …
Splunk ist der Schlüssel zur unternehmerischen Resilienz und bietet eine einheitliche, KI-gestützte Plattform für Sicherheit und Observability. Es ermöglicht Organisationen, Daten aus jeder Quelle und in jedem Maßstab zu untersuchen, zu überwachen, zu analysieren und darauf zu reagieren. Als Teil von Cisco hilft Splunk SecOps-, ITOps- und Engineering-Teams, ihre digitalen Systeme im KI-Zeitalter sicher und zuverlässig zu halten.
Metoro
Metoro ist eine KI-gestützte Observability-Plattform für Kubernetes. Sie nutzt eBPF-Technologie für eine instrumentierungsfreie Überwachung, die eine autonome Problemerkennung, …
Metoro ist eine KI-gestützte Observability-Plattform für Kubernetes. Sie nutzt eBPF-Technologie für eine instrumentierungsfreie Überwachung, die eine autonome Problemerkennung, Ursachenanalyse und automatisierte Code-Korrekturen über Pull-Requests ermöglicht. In weniger als einer Minute einsatzbereit, bietet sie eine umfassende und kostengünstige Alternative zu herkömmlichen Monitoring-Tools.
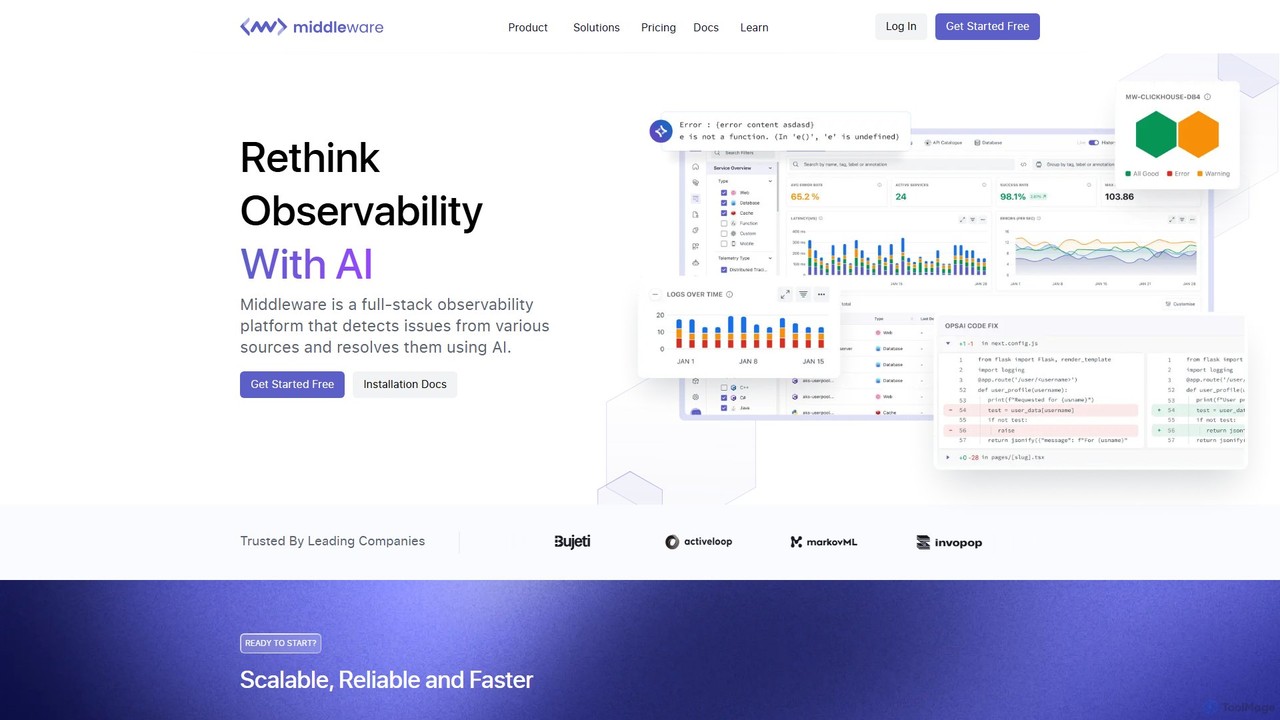
Middleware
Middleware ist eine KI-gestützte Full-Stack-Cloud-Observability-Plattform, die zur Modernisierung der IT-Infrastruktur entwickelt wurde. Sie vereint Logs, Metriken, Traces und …
Middleware ist eine KI-gestützte Full-Stack-Cloud-Observability-Plattform, die zur Modernisierung der IT-Infrastruktur entwickelt wurde. Sie vereint Logs, Metriken, Traces und RUM-Daten in einer einzigen Ansicht und ermöglicht es Teams, ihren gesamten Technologie-Stack in Echtzeit zu überwachen. Mit seiner Kernfunktion OpsAI erkennt, diagnostiziert und löst Middleware automatisch bis zu 70 % der Probleme, was die Lösungszeit erheblich verkürzt und die Entwicklerproduktivität verbessert. Es bietet eine kostengünstige, skalierbare Lösung für Unternehmen jeder Größe.
Signal0ne
Signal0ne ist eine KI-gestützte AIOps-Plattform, die als Bereitschaftsassistent für DevOps- und SRE-Teams fungiert. Sie automatisiert die Ursachenanalyse, indem …
Signal0ne ist eine KI-gestützte AIOps-Plattform, die als Bereitschaftsassistent für DevOps- und SRE-Teams fungiert. Sie automatisiert die Ursachenanalyse, indem sie Signale aus Ihrem bestehenden Observability-Stack korreliert, Alarme mit entscheidendem Kontext anreichert und Abhilfemaßnahmen vorschlägt. Dies hilft Teams, die Alarmmüdigkeit zu reduzieren und die mittlere Lösungszeit (MTTR) erheblich zu verkürzen.
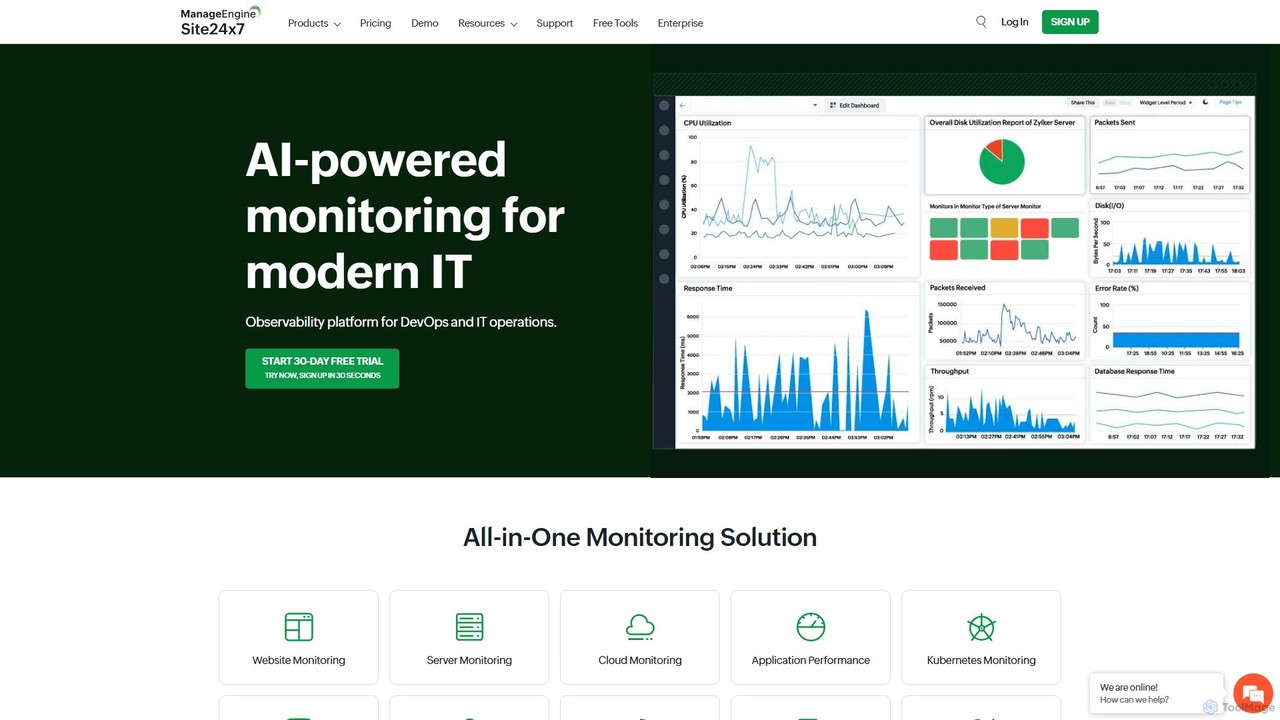
Site24x7
Site24x7 ist eine KI-gestützte All-in-One-Observability-Plattform für DevOps und IT-Betrieb. Sie bietet umfassendes Monitoring für Websites, Server, Cloud-Infrastrukturen (AWS, …
Site24x7 ist eine KI-gestützte All-in-One-Observability-Plattform für DevOps und IT-Betrieb. Sie bietet umfassendes Monitoring für Websites, Server, Cloud-Infrastrukturen (AWS, Azure, GCP), Netzwerke und Anwendungen über eine einzige Konsole. Sie hilft, die Betriebszeit sicherzustellen, Leistungsprobleme zu beheben und die Benutzererfahrung zu optimieren.
Pezzo
Pezzo ist eine Open-Source, entwicklerorientierte KI-Plattform, die den gesamten Lebenszyklus der Entwicklung von KI-Funktionen optimieren soll. Sie ermöglicht …
Pezzo ist eine Open-Source, entwicklerorientierte KI-Plattform, die den gesamten Lebenszyklus der Entwicklung von KI-Funktionen optimieren soll. Sie ermöglicht es Teams, KI-gestützte Funktionen durch zentralisiertes Prompt-Management, Echtzeit-Beobachtbarkeit und kollaborative Werkzeuge bis zu 10x schneller zu erstellen, zu testen, zu überwachen und bereitzustellen.
OpenLIT
OpenLIT ist eine Open-Source, OpenTelemetry-native Observability-Plattform für Generative KI- und LLM-Anwendungen. Sie vereinfacht die Entwicklung mit Werkzeugen für …
OpenLIT ist eine Open-Source, OpenTelemetry-native Observability-Plattform für Generative KI- und LLM-Anwendungen. Sie vereinfacht die Entwicklung mit Werkzeugen für Request-Tracing, Kostenverfolgung, Ausnahmeüberwachung und Leistungsanalyse. Mit einem zentralen Prompt-Repository, einem sicheren Tresor für Geheimnisse und einem Playground zum Vergleich von LLMs bietet OpenLIT eine umfassende Lösung zur effizienten Überwachung und Skalierung von KI-Anwendungen.

Valyr
Valyr (ehemals Helicone) ist eine Open-Source-Plattform für LLM-Observability und ein KI-Gateway. Es hilft Entwicklern, ihre KI-Anwendungen zu überwachen, …
Valyr (ehemals Helicone) ist eine Open-Source-Plattform für LLM-Observability und ein KI-Gateway. Es hilft Entwicklern, ihre KI-Anwendungen zu überwachen, zu debuggen und zu analysieren, bietet eine einzige Integration für den Zugriff auf über 100 Modelle, Kostenmanagement und verbesserte Zuverlässigkeit durch Funktionen wie Caching und Ratenbegrenzung.
Mezmo
Mezmo ist eine umfassende Telemetrie-Datenpipeline-Plattform, die für Entwickler, DevOps- und SRE-Teams entwickelt wurde. Sie ermöglicht es Benutzern, Protokolle, …
Mezmo ist eine umfassende Telemetrie-Datenpipeline-Plattform, die für Entwickler, DevOps- und SRE-Teams entwickelt wurde. Sie ermöglicht es Benutzern, Protokolle, Metriken und Traces aus beliebigen Quellen zu erfassen, zu verarbeiten und zu analysieren. Mit einem Fokus auf Kontrolle und Kosteneffizienz ermöglicht Mezmo das Filtern, Transformieren und Weiterleiten Ihrer Observability-Daten an jedes Ziel, um die Leistung zu optimieren und Kosten zu senken.
Über Beobachtbarkeit
Observability-Tools sind KI-gestützte Lösungen, die tiefe Einblicke in den internen Zustand und das Verhalten komplexer Softwaresysteme ermöglichen. Durch das Sammeln und Analysieren von Metriken, Logs und Traces versetzen diese Tools Entwickler- und Betriebsteams in die Lage, zu verstehen, warum Probleme auftreten, potenzielle Probleme vorherzusagen und die Leistung zu optimieren. Sie sind unerlässlich für die Aufrechterhaltung der Zuverlässigkeit, Effizienz und Ausfallsicherheit moderner Anwendungen, insbesondere in verteilten und Cloud-nativen Umgebungen.
Kernfunktionen
- Automatisierte Datenerfassung: Sammelt automatisch Metriken, Logs und Traces aus verschiedenen Quellen (Anwendungen, Infrastruktur, Dienste).
- Echtzeit-Monitoring & Alarmierung: Bietet Dashboards zur Echtzeit-Visualisierung des Systemzustands und löst Alarme bei Anomalien oder vordefinierten Schwellenwerten aus.
- Verteiltes Tracing: Verfolgt Anfragen über mehrere Dienste hinweg, um Latenzengpässe und Fehlerpunkte in Microservices-Architekturen zu lokalisieren.
- Log-Management & -Analyse: Zentralisiert, indiziert und analysiert große Mengen von Log-Daten zur Fehlerbehebung und Sicherheitsprüfung.
- KI-gesteuerte Anomalieerkennung: Nutzt maschinelles Lernen, um ungewöhnliche Muster im Systemverhalten zu identifizieren, die auf aufkommende Probleme hindeuten könnten.
Anwendungsszenarien
Observability-Tools sind für SREs, DevOps-Ingenieure und Entwickler, die Produktionssysteme verwalten, unverzichtbar. Sie werden verwendet, um die Grundursache von Anwendungsfehlern schnell zu diagnostizieren, die Leistung von Microservices zu überwachen und sicherzustellen, dass Service Level Objectives (SLOs) eingehalten werden. Ein DevOps-Team könnte diese Tools beispielsweise verwenden, um nach einer neuen Bereitstellung einen Speicherleck in einem bestimmten Dienst zu identifizieren oder um zu verstehen, warum eine Benutzeranfrage über mehrere Backend-Komponenten hinweg eine hohe Latenz aufweist.
Auswahlkriterien
Bei der Auswahl eines Observability-Tools sollten Sie dessen Datenerfassungsfähigkeiten (Metriken, Logs, Traces), die Integration in Ihren bestehenden Tech-Stack und die Skalierbarkeit zur Bewältigung wachsender Datenmengen berücksichtigen. Bewerten Sie die Echtzeit-Analyse- und Visualisierungsfunktionen, einschließlich anpassbarer Dashboards und Alarmierungsmechanismen. Beurteilen Sie auch die KI-gesteuerten Einblicke zur Anomalieerkennung und Ursachenanalyse sowie das Preismodell, das auf Datenerfassung und -speicherung basiert.
BeobachtbarkeitAnwendungsfälle
Produktionsvorfälle schneller diagnostizieren
Site Reliability Engineers (SREs) nutzen Observability-Plattformen, um die Grundursache kritischer Produktionsprobleme schnell zu identifizieren. Durch die Korrelation von Metriken, Logs und Traces über verteilte Dienste hinweg können sie schnell feststellen, welche spezifische Komponente ausfällt oder eine Leistungsverschlechterung erfährt, wodurch die mittlere Wiederherstellungszeit (MTTR) reduziert und Ausfallzeiten für Endbenutzer minimiert werden.
Optimierung der Microservices-Leistung
Entwickler- und DevOps-Teams nutzen verteiltes Tracing, um den gesamten Anforderungsfluss durch eine komplexe Microservices-Architektur zu visualisieren. Dies ermöglicht es ihnen, Latenzengpässe, ineffiziente Datenbankabfragen oder langsame API-Aufrufe zwischen Diensten zu identifizieren, was gezielte Optimierungen zur Verbesserung der gesamten Anwendungsreaktionsfähigkeit und Benutzererfahrung ermöglicht.
Proaktive Anomalieerkennung
Betriebsteams setzen KI-gestützte Observability-Tools ein, um ungewöhnliche Muster im Systemverhalten automatisch zu erkennen, die auf ein bevorstehendes Problem hindeuten könnten. Zum Beispiel kann ein plötzlicher Anstieg der Fehlerraten für eine bestimmte API oder ein unerwarteter Rückgang des Durchsatzes markiert werden, bevor er Benutzer beeinträchtigt, was eine proaktive Intervention und die Vermeidung von Ausfällen ermöglicht.
Sicherstellung von Compliance und Sicherheitsaudits
Sicherheits- und Compliance-Beauftragte nutzen zentrale Log-Management-Funktionen, um Audit-Logs von allen Systemkomponenten zu sammeln, zu speichern und zu analysieren. Dies bietet eine umfassende Spur von Aktivitäten, die hilft, unautorisierte Zugriffsversuche zu erkennen, Sicherheitsvorfälle zu untersuchen und die Einhaltung regulatorischer Anforderungen wie DSGVO oder HIPAA nachzuweisen.
Kapazitätsplanung und Ressourcenmanagement
Infrastruktur-Ingenieure nutzen historische Leistungsmetriken, die von Observability-Tools gesammelt wurden, um Trends bei der Ressourcennutzung (CPU, Speicher, Netzwerk) zu verstehen. Diese Daten fließen in strategische Entscheidungen für die Kapazitätsplanung ein, um sicherzustellen, dass genügend Ressourcen zur Bewältigung von Spitzenlasten vorhanden sind, während Überprovisionierung und unnötige Infrastrukturkosten vermieden werden.
Validierung neuer Bereitstellungen und Funktionen
Entwicklungsteams integrieren Observability in ihre CI/CD-Pipelines, um die Auswirkungen neuer Code-Bereitstellungen oder Feature-Releases in Echtzeit zu überwachen. Durch die Beobachtung wichtiger Leistungsindikatoren (KPIs) und Fehlerraten unmittelbar nach einem Rollout können sie Regressionen oder unerwartetes Verhalten schnell identifizieren und bei Bedarf Rollbacks einleiten, um stabile Releases zu gewährleisten.