Dagster
Website besuchen
Dagster Übersicht
Dagster ist ein Open-Source-Orchestrierer der nächsten Generation für den gesamten Datenentwicklungslebenszyklus. Er dient als einheitliche Steuerungsebene für Daten- und KI-Pipelines und befähigt Teams, ihre Workflows mit beispiellosem Vertrauen zu erstellen, zu skalieren und zu überwachen. Dagster geht über traditionelle aufgabenbasierte Scheduler hinaus und führt einen datenbewussten, asset-basierten Ansatz ein. Das bedeutet, dass die Ergebnisse Ihrer Berechnungen – wie Tabellen, Dateien, Berichte und Machine-Learning-Modelle – als erstklassige Bürger behandelt werden. Dieser grundlegende Wandel ermöglicht eine intuitivere Entwicklung, leistungsstarkes Debugging und umfassende Beobachtbarkeit über Ihre gesamte Datenplattform hinweg.
Dagster wurde für modernes Data Engineering entwickelt und integriert Best Practices der Softwareentwicklung direkt in den Datenworkflow. Es ermöglicht Entwicklern, Pipelines lokal zu testen, branch-basierte Deployments für Staging-Umgebungen zu nutzen und mit wiederverwendbaren Komponenten zu bauen, was die Entwicklungsgeschwindigkeit und Zuverlässigkeit drastisch erhöht. Es wurde entwickelt, um unterschiedliche Tools und Teams zu vereinen und eine plattformweite Sichtbarkeit zu bieten, ohne Governance oder Qualität zu opfern, was es zu einer idealen Lösung für leistungsstarke Organisationen macht, die Datensilos aufbrechen wollen.
Wie man Dagster verwendet
Die Verwendung von Dagster umfasst einen entwicklerzentrierten Workflow, der Best Practices von der Entwicklung bis zur Produktion fördert:
- Assets in Python definieren: Beginnen Sie damit, Ihre Daten-Assets deklarativ mit den Python-APIs von Dagster zu definieren. Ein Asset kann eine Datenbanktabelle, eine S3-Datei oder ein ML-Modell sein. Sie definieren die Funktion, die das Asset berechnet, und seine vorgelagerten Asset-Abhängigkeiten.
- Lokal entwickeln und testen: Die Architektur von Dagster ist für die lokale Entwicklung ausgelegt. Sie können Ihre gesamte Pipeline oder einzelne Assets auf Ihrem lokalen Rechner ausführen und testen und schnell iterieren, ohne in eine produktionsähnliche Umgebung deployen zu müssen.
- Ihren Stack integrieren: Verbinden Sie Dagster mit Ihrem bestehenden Daten-Stack über seine umfangreiche Bibliothek von Integrationen. Egal, ob Sie Snowflake, dbt, Spark, Databricks oder Cloud-Dienste wie AWS und Azure verwenden, Dagster fungiert als zentrale Orchestrierungsschicht.
- Mit Vertrauen bereitstellen: Nutzen Sie moderne Bereitstellungsmuster wie Branch-Deployments, um isolierte Staging-Umgebungen für Ihre Änderungen zu erstellen. Der CI/CD-native Workflow von Dagster ermöglicht es Ihnen, Code vertrauensvoll in die Produktion zu bringen.
- Beobachten und warten: Nutzen Sie die Dagster-Benutzeroberfläche, um ein vollständiges Bild Ihrer Datenplattform zu erhalten. Visualisieren Sie die End-to-End-Datenherkunft, überwachen Sie die Aktualität und den Zustand Ihrer Assets, überprüfen Sie den Ausführungsverlauf und debuggen Sie Fehler. Die Plattform bietet auch Kosteneinblicke, um die Ausgaben für Ihre Dateninfrastruktur zu verwalten und zu optimieren.
Kernfunktionen von Dagster
- Datenbewusste Orchestrierung: Anstatt nur Aufgaben nach einem Zeitplan auszuführen, versteht Dagster die von ihnen erzeugten Daten-Assets. Es kann Ausführungen intelligent auf der Grundlage von Datenaktualisierungen auslösen, partitionierte Daten verwalten und inkrementelle Updates effizient durchführen.
- Integrierter Datenkatalog und Herkunft: Dagster generiert automatisch einen reichhaltigen Echtzeit-Datenkatalog aus Ihrem Code. Er bietet eine einheitliche Ansicht aller Assets, ihrer Metadaten und ihrer Upstream-/Downstream-Beziehungen, was die Datenentdeckung und die Auswirkungsanalyse vereinfacht.
- Integrierte Datenqualität und Beobachtbarkeit: Betten Sie Datenqualitätsprüfungen direkt in Ihre Asset-Definitionen ein. Überwachen Sie die Aktualität der Assets, um sicherzustellen, dass Ihre Daten auf dem neuesten Stand sind, und verwenden Sie die integrierten Tools, um die Integrität, Konformität und Transparenz jedes Datensatzes zu verfolgen.
- Entwickler-First-Erlebnis: Ein Kernprinzip von Dagster ist es, ein Erlebnis zu bieten, das Entwickler lieben. Dazu gehören lokale Tests, Typüberprüfung, eine saubere Python-API und Tools, die das Debugging unkompliziert machen.
- Kosteneinblicke: Gewinnen Sie Einblick in die Kosten Ihrer Daten- und KI-Pipelines. Dagster kann die mit jedem Asset verbundenen Rechen- und Speicherkosten verfolgen und Ihnen helfen, Ineffizienzen zu identifizieren und Ihr Budget zu optimieren.
- Umfangreiche Integrationen: Ein reichhaltiges Ökosystem von Integrationen ermöglicht es Dagster, Jobs über Ihren gesamten Stack hinweg zu orchestrieren, einschließlich dbt, Snowflake, Databricks, Spark, Kubernetes und mehr.
- Skalierbare und wiederverwendbare Komponenten: Bauen Sie Ihre Pipelines aus modularen, wiederverwendbaren Komponenten (bekannt als 'ops' und 'graphs'), um Boilerplate-Code zu vermeiden und Teams zu ermöglichen, neue Datenprodukte schneller zu erstellen.
Anwendungsfälle für Dagster
Dagster ist vielseitig und kann in einer Vielzahl von Szenarien angewendet werden:
- Moderne Datenplattformen: Erstellen und verwalten Sie robuste End-to-End-Datenplattformen für Analytik, Business Intelligence und operatives Reporting.
- KI- & Machine-Learning-Pipelines: Orchestrieren Sie den gesamten ML-Lebenszyklus, von der Datenaufnahme und dem Feature-Engineering bis hin zum Modelltraining, der Validierung und dem Deployment.
- Modernisierung von Legacy-Stacks: Migrieren Sie von fragilen, schwer zu wartenden Systemen wie Cron-Jobs oder älteren Orchestrierern (z. B. Airflow) zu einer modernen, zuverlässigen und skalierbaren Plattform.
- Ermöglichung von Daten-Self-Service: Erstellen Sie eine zentralisierte Plattform mit wiederverwendbaren Komponenten, die es verschiedenen Teams (z. B. Analytik, Data Science) ermöglicht, ihre eigenen Datenpipelines zu erstellen und zu verwalten, ohne tiefgreifendes Infrastrukturwissen zu benötigen.
- Daten-Governance und Compliance: Nutzen Sie die automatisierte Herkunfts- und Metadatenverfolgung, um die Datenintegrität zu gewährleisten, die Datennutzung zu prüfen und Vorschriften wie die DSGVO einzuhalten.
Vorteile von Dagster
Dagster bietet erhebliche Vorteile gegenüber traditionellen Datenorchestrierern:
- Erhöhte Entwicklungsgeschwindigkeit: Der Fokus auf lokale Entwicklung, Tests und Wiederverwendbarkeit ermöglicht es Teams, schneller zu iterieren und zu liefern.
- Verbesserte Zuverlässigkeit: Der asset-basierte Ansatz und die integrierten Datenqualitätsprüfungen führen zu robusteren und vertrauenswürdigeren Pipelines.
- Einheitliche Sichtbarkeit: Eine einzige Ansicht für Herkunft, Zustand und Metadaten bricht Silos auf und bietet eine ganzheitliche Sicht auf die Datenplattform.
- Reduzierte kognitive Last: Die Modellierung von Daten-Assets ist intuitiver als die Modellierung von Aufgaben, was komplexe Pipelines leichter verständlich, debuggbar und wartbar macht.
- Zukunftsfähige Architektur: Das flexible, integrationsfreundliche Design von Dagster ermöglicht es Ihnen, Ihren Daten-Stack weiterzuentwickeln, ohne an einen bestimmten Anbieter oder eine bestimmte Technologie gebunden zu sein.
Preise und Pläne
Dagster arbeitet nach einem Freemium-Modell. Dagster Open Source ist ein leistungsstarkes, kostenloses Framework, das Sie selbst hosten und anpassen können. Für Benutzer, die eine verwaltete, unternehmensreife Lösung suchen, ist Dagster+ ein kommerzielles Cloud-Angebot. Dagster+ bietet eine vollständig verwaltete Steuerungsebene, serverlose Bereitstellungsoptionen, erweiterte Funktionen wie Kosteneinblicke und Asset-Zustandsüberwachung, unternehmensgerechte Sicherheit und dedizierten Support. Dagster+ bietet in der Regel eine kostenlose Testversion oder eine kostenlose Stufe für Einzelpersonen und kleine Teams, mit skalierbaren Preisen für größere Organisationen. Für die genauesten und detailliertesten Preisinformationen wird empfohlen, die offizielle Dagster-Website zu besuchen.
Dagster Kommentare (0)
Melden Sie sich an, um einen Kommentar zu hinterlassen
Jetzt anmeldenDagsterWebsite-Traffic-Analyse
Aktueller Traffic-Status
Status
Monatlicher Traffic-Trend
Standort
Top 5 Länder/Regionen
-
🇺🇸 United States40,88%
-
🇨🇳 China19,26%
-
🇳🇱 Netherlands15,99%
-
🇮🇳 India13,29%
-
🇩🇪 Germany10,58%
Traffic-Quelle
| Quellentyp | Prozentsatz |
|---|---|
|
Direkte Zugriffe
|
75,98% |
|
Verweise
|
20,29% |
|
E-Mail
|
3,73% |
Beliebte Keywords
| Keyword | Kosten pro Klick |
|---|---|
|
$3,43
|
|
|
$0,00
|
|
|
$0,00
|
|
|
$0,00
|
|
|
$2,97
|
Dagster Alternativen
Alle anzeigen
Orchestra
Orchestra ist eine einheitliche Steuerungsebene für Datenorchestrierung und -pipelining, die für schlanke Datenteams entwickelt wurde. Es bietet eine …
Orchestra ist eine einheitliche Steuerungsebene für Datenorchestrierung und -pipelining, die für schlanke Datenteams entwickelt wurde. Es bietet eine KI-native Lösung zum Erstellen, Überwachen und Verwalten von gesteuerten Datenpipelines mit End-to-End-Beobachtbarkeit, proaktiven Warnungen und umfangreichen Integrationen. Es vereinfacht komplexe Daten-Workflows, reduziert den Wartungsaufwand und stellt sicher, dass Daten zuverlässig und KI-fähig sind.
Metaflow
Ein auf den Menschen ausgerichtetes Python-Framework, ursprünglich von Netflix, zum Erstellen und Verwalten von realen Data-Science-, ML- und …
Ein auf den Menschen ausgerichtetes Python-Framework, ursprünglich von Netflix, zum Erstellen und Verwalten von realen Data-Science-, ML- und KI-Projekten. Es vereinfacht die Workflow-Orchestrierung, das Datenmanagement und die Modellbereitstellung und ermöglicht schnelles Prototyping und skalierbare Produktionspipelines.
Paradime
Paradime ist eine KI-gestützte ELT-Plattform für Analytik und KI, die als überlegene Alternative zu dbt Cloud konzipiert wurde. …
Paradime ist eine KI-gestützte ELT-Plattform für Analytik und KI, die als überlegene Alternative zu dbt Cloud konzipiert wurde. Sie integriert eine KI-erweiterte Code-IDE, automatisierte Datenpipelines (Bolt) und ein FinOps-Kosteneinsparungstool (Radar) in einer einzigen, einheitlichen Plattform. Dies ermöglicht es Datenteams, die Entwicklung zu beschleunigen, die Zuverlässigkeit zu erhöhen und die Kosten für das Data Warehouse erheblich zu senken, wodurch der gesamte Analyse-Engineering-Workflow optimiert wird.

CrewAI
CrewAI ist eine leistungsstarke Multi-Agenten-Plattform zum Erstellen und Orchestrieren kollaborativer KI-Agenten-Workflows. Sie ermöglicht Entwicklern, „Crews“ aus spezialisierten KI-Agenten …
CrewAI ist eine leistungsstarke Multi-Agenten-Plattform zum Erstellen und Orchestrieren kollaborativer KI-Agenten-Workflows. Sie ermöglicht Entwicklern, „Crews“ aus spezialisierten KI-Agenten zu erstellen, die zusammenarbeiten, um komplexe Aufgaben zu automatisieren. Mit seinem Open-Source-Framework, dem No-Code-UI-Studio und der „Flows“-Funktion für strukturierte Automatisierung optimiert es die Entwicklung von der Planung bis zur Bereitstellung und Überwachung und lässt sich in jedes LLM und jeden Cloud-Anbieter integrieren.
Flyte
Flyte ist eine Open-Source, Cloud-native Workflow-Orchestrierungsplattform, die für die Erstellung, Bereitstellung und Verwaltung von produktionsreifen Daten-, Machine-Learning- und …
Flyte ist eine Open-Source, Cloud-native Workflow-Orchestrierungsplattform, die für die Erstellung, Bereitstellung und Verwaltung von produktionsreifen Daten-, Machine-Learning- und Analyse-Pipelines entwickelt wurde. Sie legt Wert auf Skalierbarkeit, Reproduzierbarkeit und Benutzerfreundlichkeit und ermöglicht es Teams, nahtlos von der lokalen Entwicklung zur groß angelegten Produktion überzugehen. Mit einem Python-first SDK und Unterstützung für mehrere Sprachen befähigt Flyte Datenwissenschaftler und Ingenieure, komplexe, versionierte und wartbare Workflows zu erstellen.
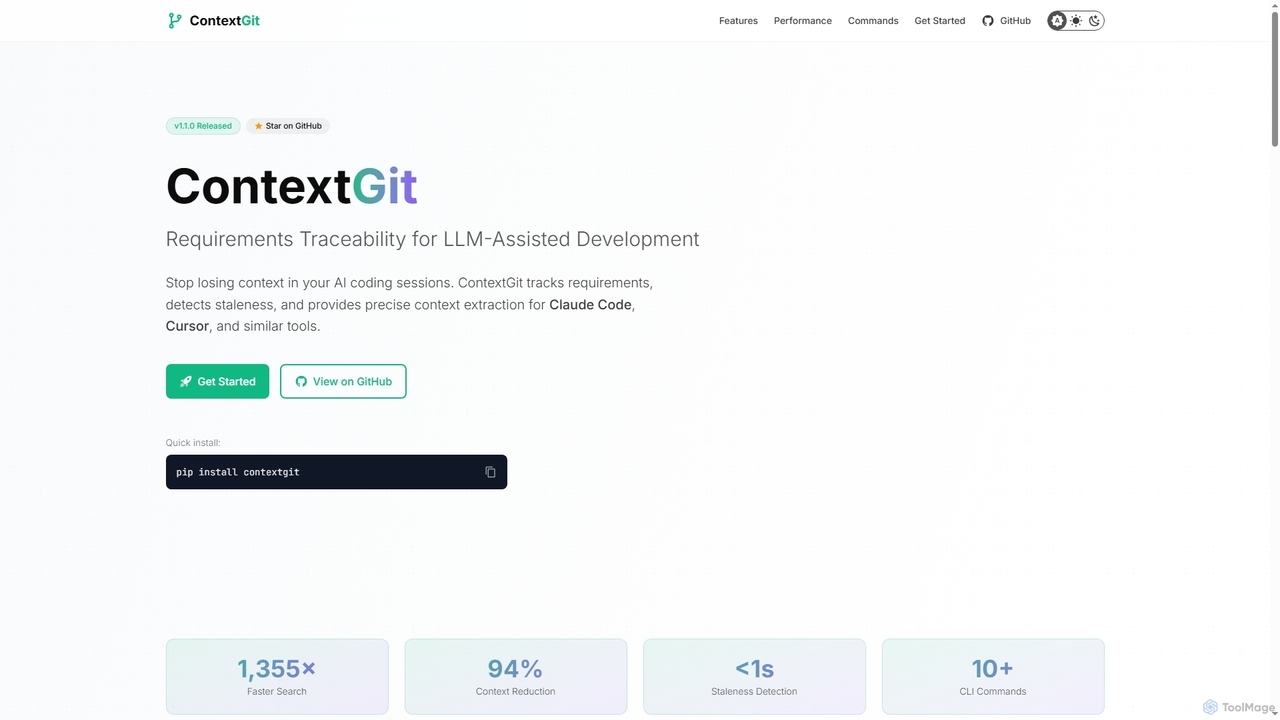
Contextgit
Ein Kommandozeilen-Tool für Entwickler, die LLMs verwenden. Es bietet Anforderungs-Nachverfolgbarkeit, Erkennung veralteter Informationen und präzise Kontext-Extraktion, um KI-gestützte …
Ein Kommandozeilen-Tool für Entwickler, die LLMs verwenden. Es bietet Anforderungs-Nachverfolgbarkeit, Erkennung veralteter Informationen und präzise Kontext-Extraktion, um KI-gestützte Codierungs-Workflows zu verbessern. Es reduziert den Token-Verbrauch erheblich und synchronisiert KI-Tools mit Projektanforderungen.
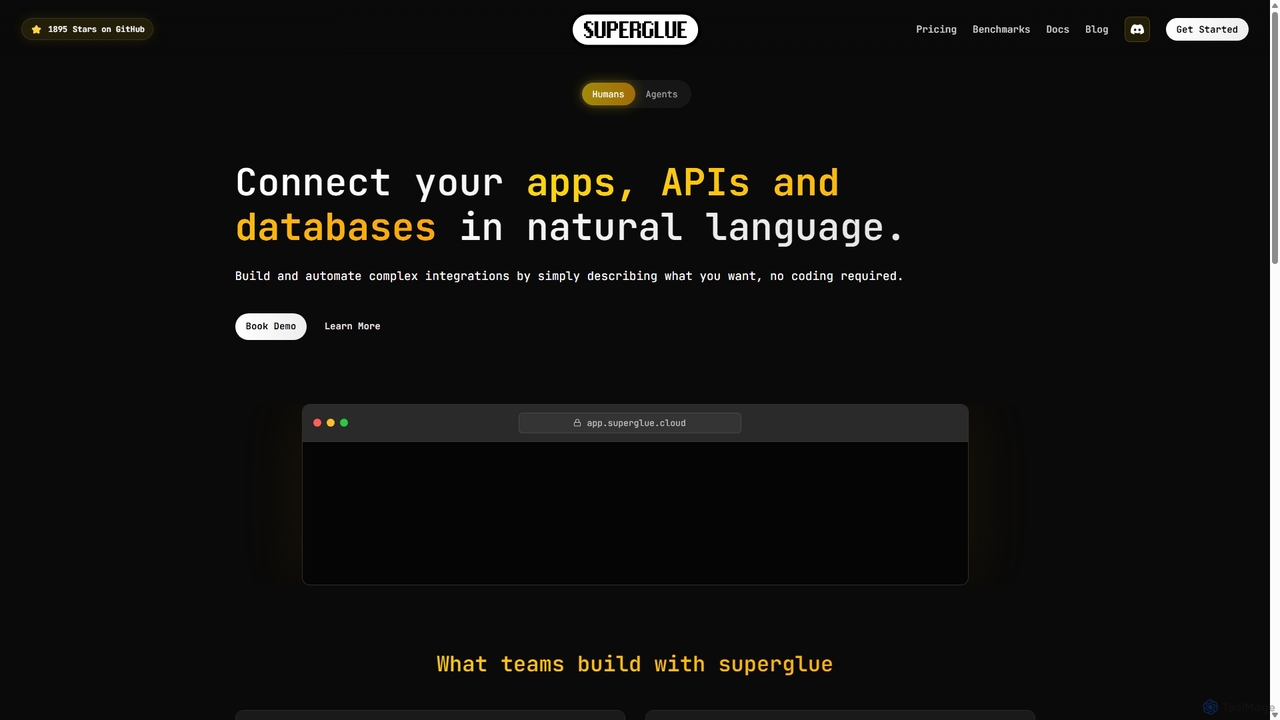
Superglue
Superglue ist eine KI-gestützte Plattform, die natürliche Sprachabsichten in zuverlässige API-Ausführungen umwandelt. Sie ermöglicht Entwicklern und Teams, ETL-Pipelines …
Superglue ist eine KI-gestützte Plattform, die natürliche Sprachabsichten in zuverlässige API-Ausführungen umwandelt. Sie ermöglicht Entwicklern und Teams, ETL-Pipelines zu automatisieren, API-Konnektoren sofort zu erstellen, Daten zu migrieren und komplexe Workflows über eine Chat-Schnittstelle oder Code zu erstellen. Sie wurde entwickelt, um KI-Agenten mit dynamischen, produktionsreifen Werkzeugen für jede API auszustatten.
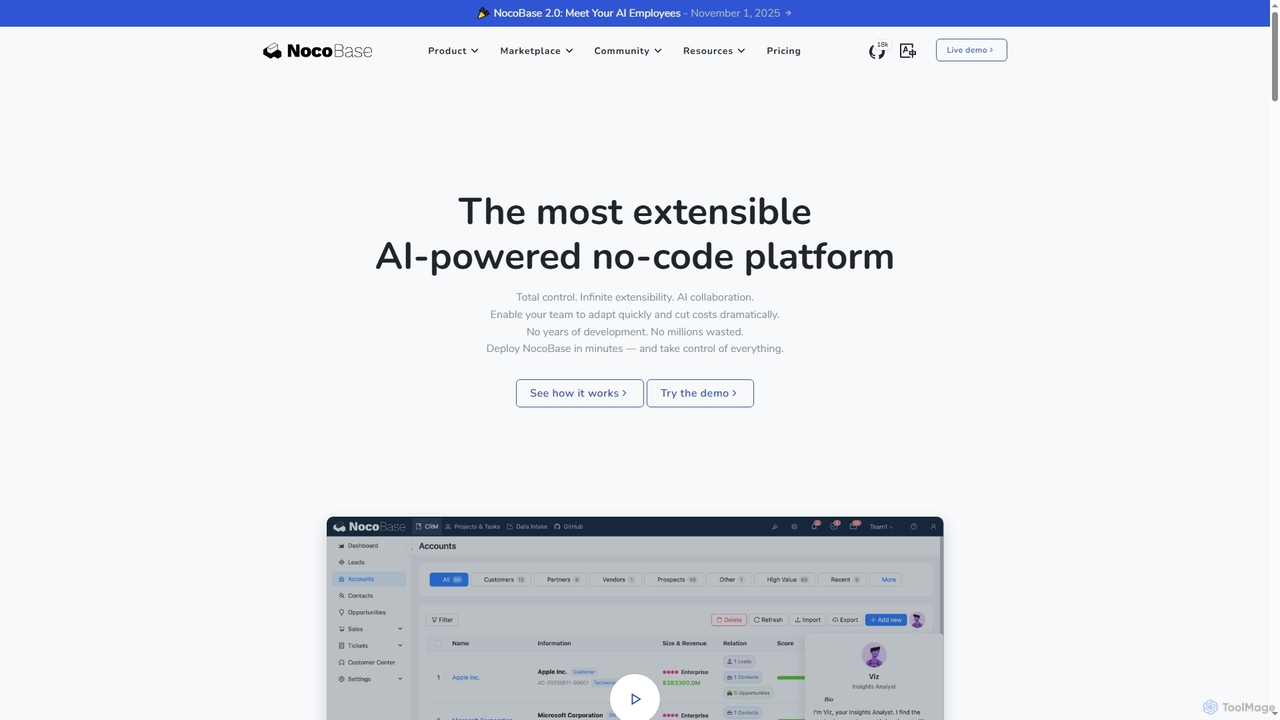
NocoBase
NocoBase ist eine Open-Source, selbst gehostete No-Code- und Low-Code-Entwicklungsplattform. Sie ermöglicht es Benutzern, benutzerdefinierte Geschäftsanwendungen wie CRMs und …
NocoBase ist eine Open-Source, selbst gehostete No-Code- und Low-Code-Entwicklungsplattform. Sie ermöglicht es Benutzern, benutzerdefinierte Geschäftsanwendungen wie CRMs und interne Tools mit hoher Flexibilität, granularen Berechtigungen und automatisierten Workflows zu erstellen und gewährleistet durch die On-Premise-Bereitstellung Datensicherheit.
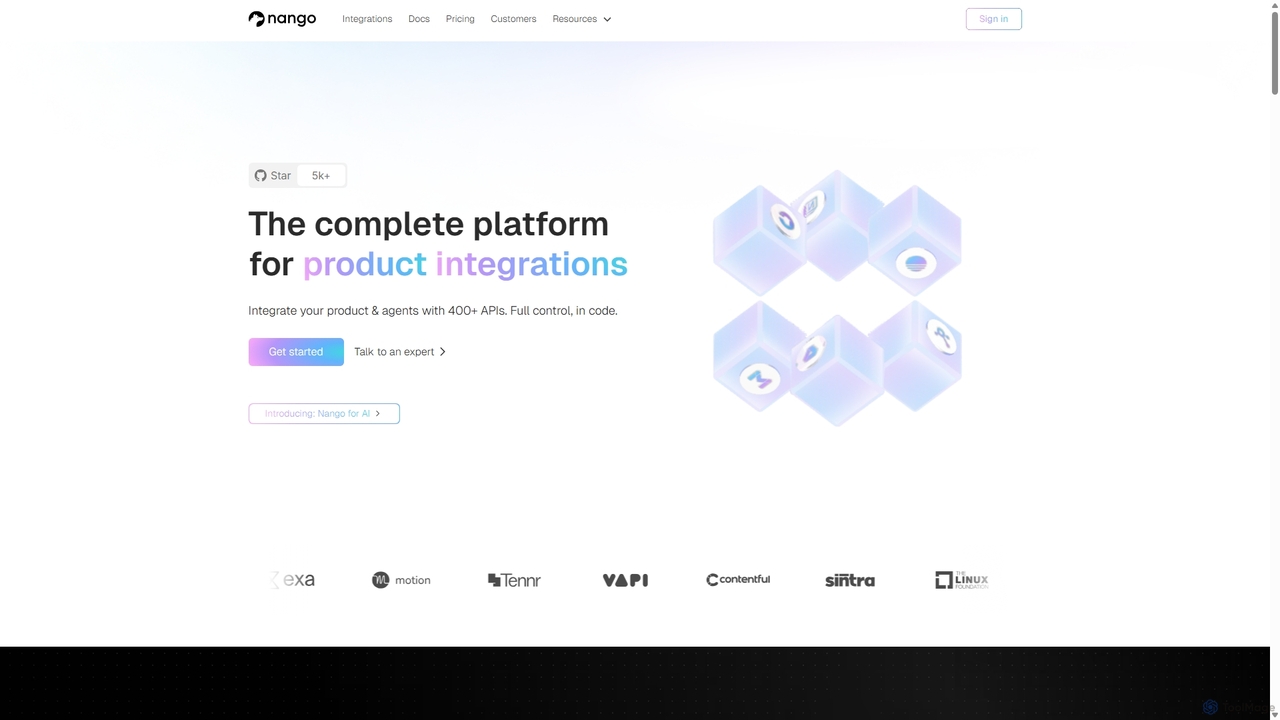
Nango
Nango ist eine umfassende Integrationsplattform für Entwickler, die es B2B-SaaS-Unternehmen ermöglicht, Produktintegrationen schnell zu erstellen, bereitzustellen und zu …
Nango ist eine umfassende Integrationsplattform für Entwickler, die es B2B-SaaS-Unternehmen ermöglicht, Produktintegrationen schnell zu erstellen, bereitzustellen und zu skalieren. Sie bietet vorgefertigte Konnektoren für über 400 APIs, handhabt komplexe Autorisierungsabläufe und stellt eine einheitliche API, Entwickler-Tools und eine skalierbare Infrastruktur bereit. Diese auf Entwickler ausgerichtete Open-Source-Plattform gewährleistet Flexibilität und Kontrolle und ermöglicht benutzerdefinierte, wartungsarme Integrationen.
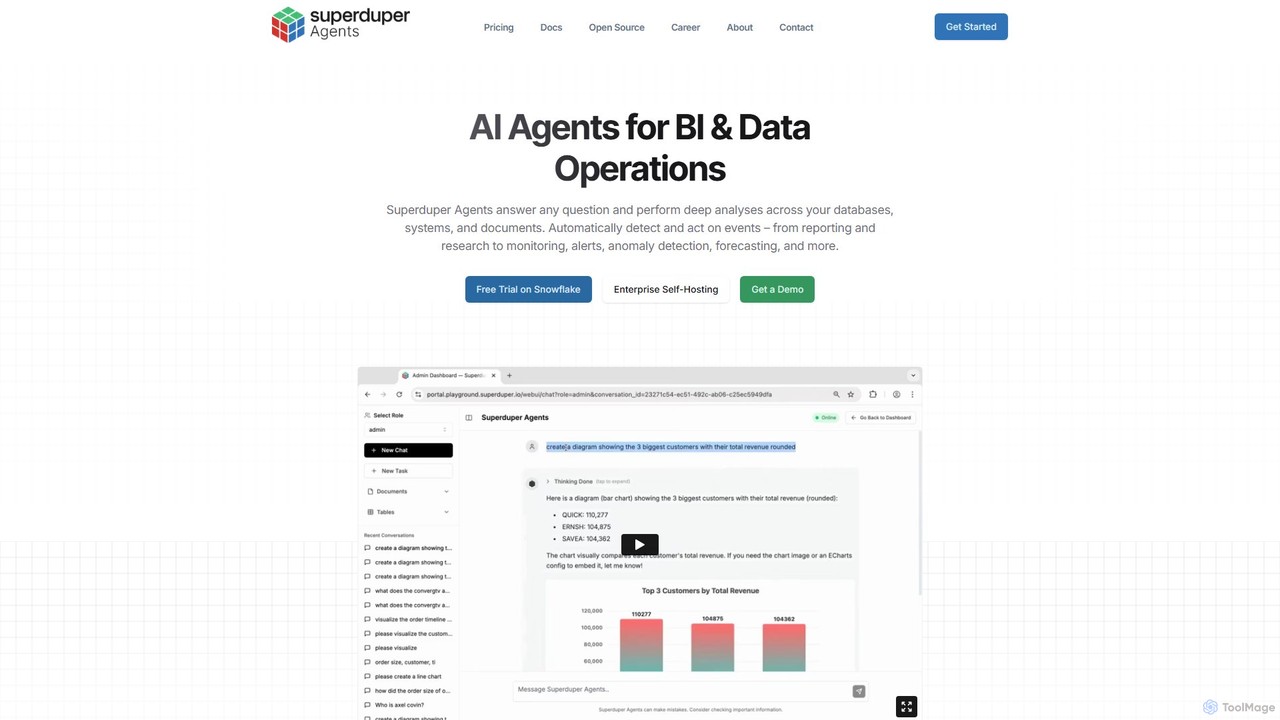
superduperdb
superduperdb ist eine Enterprise-KI-Agenten-Orchestrierungsplattform, die sich nahtlos in Ihre bestehenden Datenbanken und Systeme integriert. Sie ermöglicht es Ihnen, …
superduperdb ist eine Enterprise-KI-Agenten-Orchestrierungsplattform, die sich nahtlos in Ihre bestehenden Datenbanken und Systeme integriert. Sie ermöglicht es Ihnen, KI-Agenten zu erstellen und bereitzustellen, um komplexe Aufgaben zu automatisieren, datengesteuerte Fragen zu beantworten und tiefgreifende Analysen über all Ihre strukturierten und unstrukturierten Daten ohne Datenmigration durchzuführen. Sie befähigt jede Abteilung, KI für gesteigerte Produktivität und datengestützte Entscheidungsfindung zu nutzen.
Dagster Kategorie
Dagster Tags
Dagster KI-Tool
Dagster Einbettungsfunktion
Kopieren Sie einfach den Einbettungscode unten und fügen Sie das ansprechende Abzeichen in Ihren Blog, Artikel oder auf die offizielle Website Ihrer App ein, um den Traffic direkt auf die Detailseite dieses Tools zu leiten und so schnell die Sichtbarkeit und Nutzerzahlen zu steigern!

Noch keine Kommentare, seien Sie der Erste!