FinetuneFast
Visitar sitio web
FinetuneFast Visión general
FinetuneFast es un kit de herramientas esencial diseñado para ingenieros de ML, desarrolladores y creadores independientes que desean acelerar su ciclo de vida de desarrollo de IA. Ofrece una colección completa de boilerplates de ML que agilizan todo el proceso, desde el entrenamiento del modelo y la preparación de datos hasta el despliegue y la escalabilidad. La misión principal de FinetuneFast, creado por el experimentado ingeniero de ML y SRE Patrick, es eliminar las tareas repetitivas y que consumen mucho tiempo asociadas con la configuración de la infraestructura de IA, permitiendo a los creadores centrarse en lo que realmente importa: construir y refinar potentes modelos de IA.
La plataforma aborda los puntos débiles comunes en el flujo de trabajo de ML, como la configuración de entornos, la limpieza de datos, la integración de API y el despliegue de modelos. Al proporcionar soluciones preconfiguradas y listas para producción, FinetuneFast afirma ahorrar a los desarrolladores más de 20 horas de trabajo en un proyecto típico, transformando un esfuerzo de varias semanas en cuestión de días.
Cómo usar FinetuneFast
Usar FinetuneFast es un proceso sencillo para cualquiera con experiencia en programación. Después de comprar un plan, recibirás acceso manual a un repositorio privado de GitHub en 24 horas. Dentro, encontrarás una colección bien organizada de boilerplates y plantillas. El flujo de trabajo típico es el siguiente:
- Selecciona un Boilerplate: Elige la plantilla adecuada para tu proyecto, ya sea para afinar un LLM como Llama-3, un modelo de texto a imagen como Flux-Schnell, o implementar un sistema RAG (Generación Aumentada por Recuperación).
- Configuración e Instalación: Sigue la documentación detallada para configurar tu entorno y los scripts con tus parámetros específicos y rutas de datos.
- Preparación de Datos: Utiliza los eficientes pipelines de carga de datos para preparar y formatear tus datos de entrenamiento.
- Entrenamiento del Modelo: Ejecuta los scripts de entrenamiento preconfigurados. Los boilerplates incluyen soporte para entrenamiento en múltiples GPU y herramientas de optimización de hiperparámetros para lograr los mejores resultados.
- Despliegue: Una vez que tu modelo está afinado, usa los boilerplates de despliegue para un despliegue con un solo clic. Esto genera un endpoint de API escalable para tu modelo, completo con monitoreo y registro.
- Soporte: Para preguntas técnicas, el plan 'All In' proporciona acceso a una comunidad dedicada de Discord para obtener soporte del creador y otros usuarios.
Características principales de FinetuneFast
- Boilerplates de Afinamiento: Scripts listos para producción para afinar varios modelos, incluyendo LLMs (OpenAI, Mistral, Llama-3.2), modelos de texto a imagen (Flux-Schnell) y de texto a voz (Fish-Speech).
- Boilerplates de Inferencia y Despliegue: Soluciones simplificadas de despliegue con un solo clic para crear endpoints de API autoescalables y listos para producción para tus modelos.
- Ejemplos y Plantillas de RAG: Plantillas listas para usar para construir sistemas avanzados de Generación Aumentada por Recuperación, permitiendo que los modelos accedan a conocimiento externo.
- Pipelines de Datos Eficientes: Scripts optimizados para cargar y procesar datos, una parte crítica pero a menudo larga del proceso de ML.
- Soporte Multi-GPU: Soporte de fábrica para entrenamiento en múltiples GPUs, acelerando significativamente el proceso de entrenamiento.
- Mejores Prácticas Incluidas: El código incorpora las mejores prácticas en ML y SRE, asegurando que tus modelos no solo sean potentes, sino también fiables y escalables.
Casos de uso para FinetuneFast
FinetuneFast es versátil y se puede utilizar para una amplia gama de proyectos:
- Productos AI SaaS: Los desarrolladores independientes pueden construir y lanzar rápidamente aplicaciones AI-SaaS de nicho, como un generador de contenido especializado o una herramienta de creación de imágenes personalizada.
- Chatbots Personalizados: Las empresas pueden afinar un LLM de código abierto con sus documentos internos para crear una base de conocimientos privada o un bot de soporte al cliente.
- Generación de Arte con IA: Artistas y diseñadores pueden afinar modelos de imagen en su estilo único para producir obras de arte consistentes y originales.
- Prototipado Rápido: Los ingenieros de ML pueden probar y validar rápidamente nuevas ideas sin atascarse en la configuración de la infraestructura subyacente.
- Servicios de IA Especializados: Construir herramientas específicas como la eliminación de fondos (RMBG-1.4) o aplicaciones multimodales (Molmo-7B) utilizando los boilerplates proporcionados.
Ventajas de FinetuneFast
La principal ventaja de FinetuneFast es la velocidad. Reduce drásticamente el tiempo de desarrollo. Otros beneficios clave incluyen:
- Rentable: Un pago único proporciona acceso a todos los materiales para proyectos ilimitados, lo que lo hace mucho más asequible que las plataformas basadas en suscripción o la contratación para la configuración.
- Listo para Producción: Los boilerplates no son solo para ejercicios académicos; están construidos para manejar tráfico del mundo real y escalar automáticamente.
- Construido por Expertos: Diseñado por un ingeniero con profunda experiencia tanto en Machine Learning como en Ingeniería de Fiabilidad de Sitios (SRE), garantizando altos estándares de calidad y fiabilidad.
- Solución Integral: Cubre el ciclo de vida completo de ML, desde el entrenamiento hasta el despliegue y el monitoreo.
Precios y planes
FinetuneFast ofrece un modelo simple de pago único.
- Plan Starter: Con un precio de $99.99 (en oferta desde $159.99). Este plan incluye Boilerplates de Afinamiento, Boilerplates de Inferencia listos para producción, Ejemplos y Plantillas de RAG, y guías de Mejores Prácticas.
- Plan All In: Con un precio de $119.99 (en oferta desde $199.99). Incluye todo en el plan Starter, más acceso a la Comunidad privada de Discord para soporte y Actualizaciones de por Vida al repositorio.
Ambos planes ofrecen una licencia de 'paga una vez, construye proyectos ilimitados'.
FinetuneFast Comentarios (0)
Inicie sesión para publicar comentarios
Iniciar sesión yaFinetuneFast Alternativas
Ver todo
thundercompute
Thunder Compute ofrece una plataforma en la nube de GPU de costo ultrabajo diseñada para desarrolladores de IA …
Thunder Compute ofrece una plataforma en la nube de GPU de costo ultrabajo diseñada para desarrolladores de IA y aprendizaje automático. Proporciona instancias de GPU bajo demanda como la NVIDIA A100 y T4 a precios hasta un 80% más bajos que los principales proveedores de la nube. Con características como configuración con un solo clic, integración con VS Code y escalabilidad perfecta, simplifica drásticamente el flujo de trabajo de desarrollo, desde la creación de prototipos hasta la producción, permitiendo a los desarrolladores centrarse en construir modelos en lugar de gestionar la infraestructura.

Paperspace
Paperspace es una plataforma de computación en la nube de alto rendimiento diseñada para IA y Machine Learning. …
Paperspace es una plataforma de computación en la nube de alto rendimiento diseñada para IA y Machine Learning. Proporciona acceso sin esfuerzo a potentes GPU en la nube, cuadernos Jupyter gestionados y una plataforma MLOps completa (Gradient) para construir, entrenar y desplegar modelos. Ideal para desarrolladores, científicos de datos y empresas que buscan acelerar sus flujos de trabajo de IA sin la complejidad de gestionar la infraestructura.
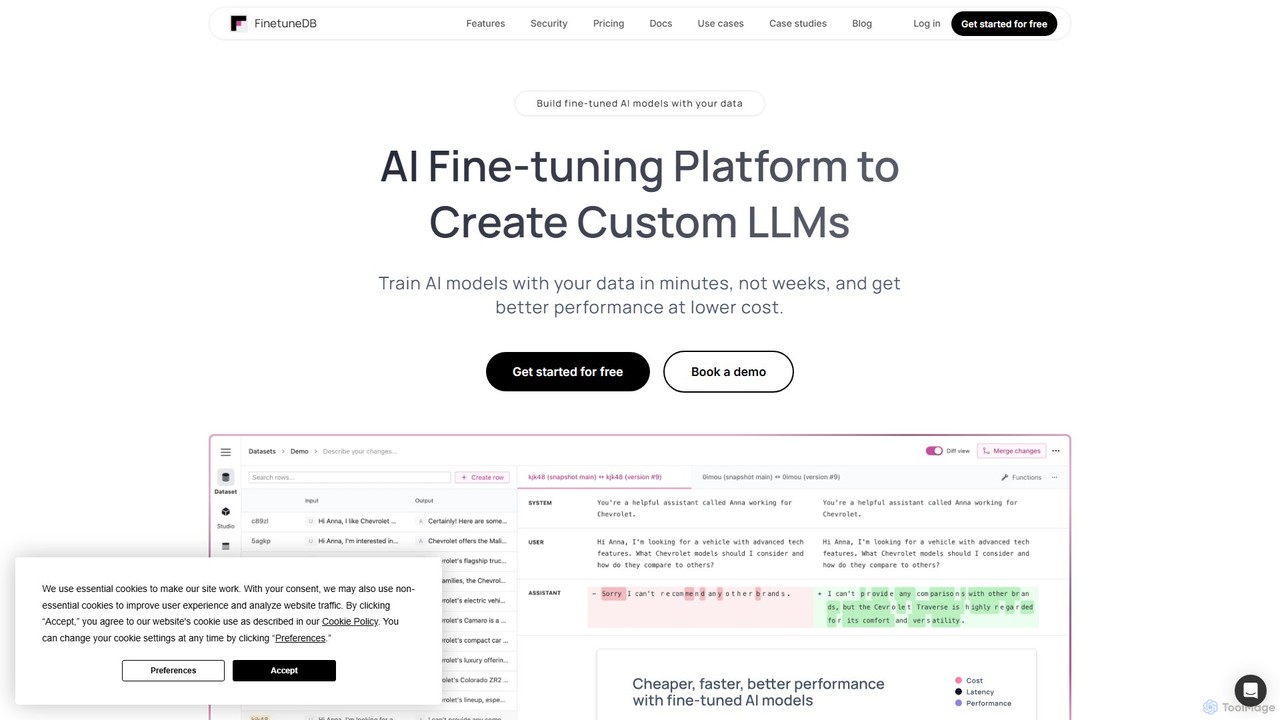
FinetuneDB
FinetuneDB es una plataforma todo en uno de ajuste fino (fine-tuning) de IA para desarrolladores. Simplifica todo el …
FinetuneDB es una plataforma todo en uno de ajuste fino (fine-tuning) de IA para desarrolladores. Simplifica todo el flujo de trabajo para crear Modelos de Lenguaje Grandes (LLMs) personalizados, desde la construcción de conjuntos de datos de alta calidad y el ajuste de modelos como Llama 3 y GPT-4o mini, hasta el despliegue y la evaluación continua en una única plataforma segura.

Ollama
Ollama es un potente marco de código abierto para ejecutar grandes modelos de lenguaje (LLMs) como Llama 3, …
Ollama es un potente marco de código abierto para ejecutar grandes modelos de lenguaje (LLMs) como Llama 3, Mistral y Gemma localmente en tu propio hardware. Disponible para macOS, Windows y Linux, simplifica la configuración y gestión de modelos de código abierto, permitiendo un desarrollo y uso de IA privado, sin conexión y rentable.

LAION
LAION (Large-scale Artificial Intelligence Open Network) es una organización sin ánimo de lucro dedicada a democratizar la investigación …
LAION (Large-scale Artificial Intelligence Open Network) es una organización sin ánimo de lucro dedicada a democratizar la investigación en IA. Proporciona al público conjuntos de datos masivos de código abierto, modelos preentrenados y herramientas, fomentando la investigación abierta, la educación y el desarrollo eficiente de recursos en el aprendizaje automático.
deepsense.ai
deepsense.ai es una empresa líder en consultoría de IA y desarrollo de software a medida. Se especializan en …
deepsense.ai es una empresa líder en consultoría de IA y desarrollo de software a medida. Se especializan en crear soluciones de IA personalizadas para empresas, aprovechando su experiencia en LLMs, RAG, visión por computadora, MLOps y análisis predictivo. Se asocian con empresas y startups para integrar IA en productos, optimizar operaciones y obtener una ventaja competitiva a través de sistemas de IA avanzados y listos para producción.

xTuring
xTuring es una biblioteca de Python de código abierto diseñada para simplificar el proceso de construcción, ajuste fino …
xTuring es una biblioteca de Python de código abierto diseñada para simplificar el proceso de construcción, ajuste fino y control de Grandes Modelos de Lenguaje (LLM). Proporciona una interfaz fácil de usar para que desarrolladores e investigadores personalicen modelos de IA para datos y aplicaciones específicas con alta eficiencia y personalización.

Pydantic
Pydantic es una plataforma integral para desarrolladores que ofrece una potente validación de datos, herramientas de desarrollo de …
Pydantic es una plataforma integral para desarrolladores que ofrece una potente validación de datos, herramientas de desarrollo de IA y una solución de observabilidad de pila completa. Permite un desarrollo de aplicaciones más rápido y robusto en Python y otros lenguajes al aprovechar las sugerencias de tipo para la validación de datos en tiempo de ejecución y proporcionar información profunda desde el desarrollo local hasta la producción.
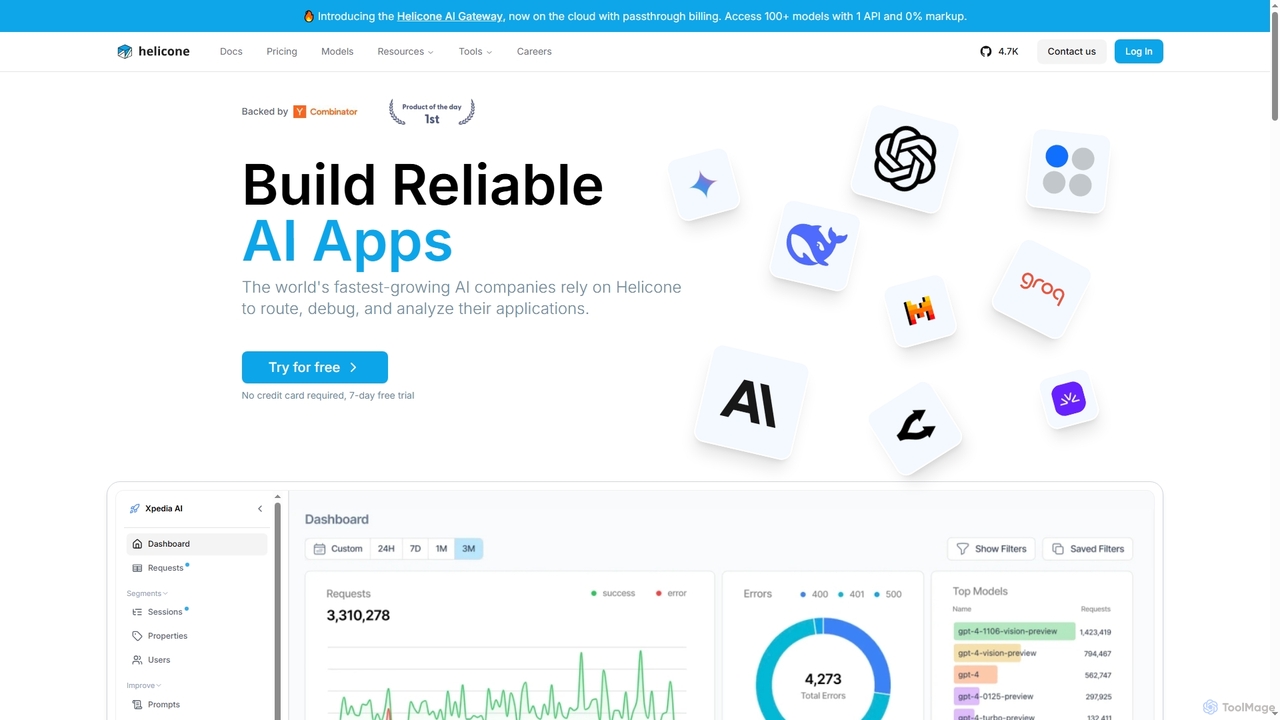
Helicone
Helicone es una plataforma de código abierto que ofrece una Puerta de Enlace de IA y Observabilidad de …
Helicone es una plataforma de código abierto que ofrece una Puerta de Enlace de IA y Observabilidad de LLM para desarrolladores. Ayuda a construir aplicaciones de IA fiables proporcionando herramientas para enrutar, monitorear, depurar y analizar el uso de LLM. Las características clave incluyen una API unificada para más de 100 modelos, almacenamiento en caché inteligente, limitación de velocidad, gestión de prompts y análisis de rendimiento detallados.

hyperficient
hyperficient es una herramienta de IA de código abierto para desarrolladores e ingenieros de ML que automatiza la …
hyperficient es una herramienta de IA de código abierto para desarrolladores e ingenieros de ML que automatiza la búsqueda de las estrategias de ajuste fino (fine-tuning) más eficientes para redes neuronales. Reduce significativamente los costos computacionales, el tiempo de GPU y el esfuerzo manual, permitiendo un rendimiento óptimo del modelo con recursos limitados.
FinetuneFast Categoría
FinetuneFast Etiquetas
FinetuneFast Herramienta de IA
FinetuneFast Función de incrustar
Simplemente copie el código de inserción de abajo y pegue la insignia en su blog, artículo o sitio web oficial para dirigir el tráfico directamente a la página de detalles de esta herramienta, ¡aumentando rápidamente la exposición y el número de usuarios!

Aún no hay comentarios, ¡sé el primero en comentar!