BlickState
BlickState est un outil avancé de débogage temporel pour agents IA, permettant aux développeurs de restaurer et d'inspecter …
BlickState est un outil avancé de débogage temporel pour agents IA, permettant aux développeurs de restaurer et d'inspecter l'état complet de la mémoire des exécutions d'outils d'agent au milliseconde exact de la défaillance. Il transforme le comportement d'agent de type boîte noire en processus transparents et inspectables, accélérant considérablement le débogage pour les ingénieurs IA.
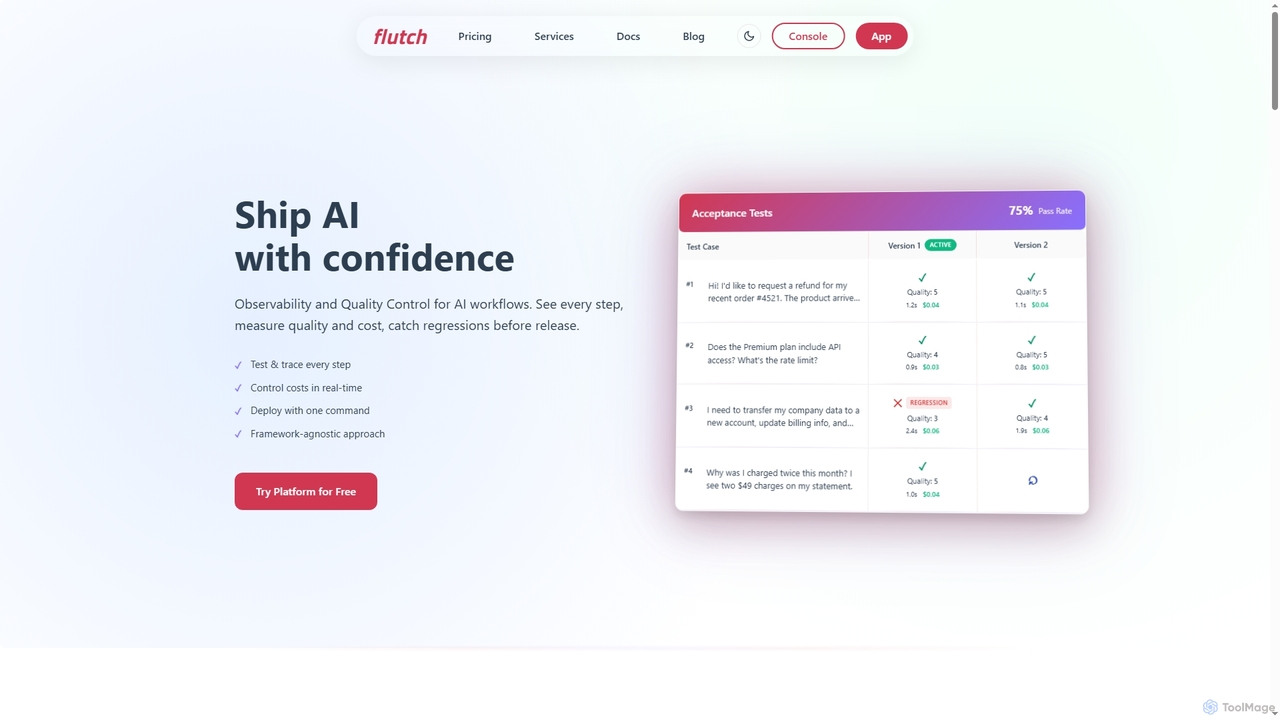
Flutch
Flutch est une plateforme complète pour le développement, le déploiement et la gestion d'agents IA personnalisés, avec un …
Flutch est une plateforme complète pour le développement, le déploiement et la gestion d'agents IA personnalisés, avec un accent fort sur l'observabilité, le contrôle qualité et la gestion des coûts. Elle permet aux développeurs de construire des flux de travail IA fiables, de tester rigoureusement les agents, de surveiller les performances en temps réel et de s'intégrer de manière transparente aux systèmes existants, garantissant que les solutions IA sont livrées en toute confiance et fonctionnent efficacement.
Splunk
Splunk est la clé de la résilience d'entreprise, offrant une plateforme unifiée et alimentée par l'IA pour la …
Splunk est la clé de la résilience d'entreprise, offrant une plateforme unifiée et alimentée par l'IA pour la sécurité et l'observabilité. Elle permet aux organisations d'enquêter, de surveiller, d'analyser et d'agir sur les données de n'importe quelle source, à n'importe quelle échelle. Désormais une société Cisco, Splunk aide les équipes SecOps, ITOps et d'ingénierie à maintenir leurs systèmes numériques sécurisés et fiables à l'ère de l'IA.
Metoro
Metoro est une plateforme d'observabilité alimentée par l'IA conçue pour Kubernetes. Elle utilise la technologie eBPF pour une …
Metoro est une plateforme d'observabilité alimentée par l'IA conçue pour Kubernetes. Elle utilise la technologie eBPF pour une surveillance sans instrumentation, permettant la détection autonome des problèmes, l'analyse des causes profondes et les corrections de code automatisées via des pull requests. Opérationnelle en moins d'une minute, elle offre une alternative complète et rentable aux outils de surveillance traditionnels.
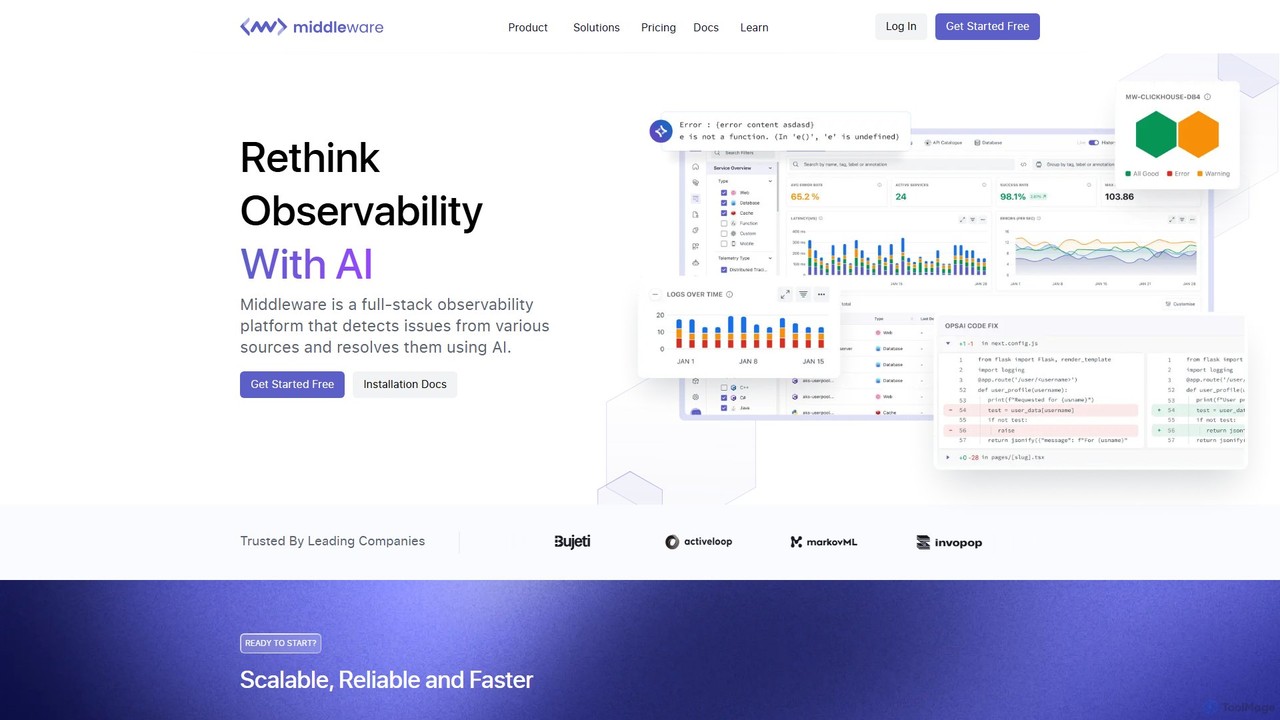
Middleware
Middleware est une plateforme d'observabilité cloud full-stack alimentée par l'IA, conçue pour moderniser l'infrastructure informatique. Elle unifie les …
Middleware est une plateforme d'observabilité cloud full-stack alimentée par l'IA, conçue pour moderniser l'infrastructure informatique. Elle unifie les journaux, les métriques, les traces et les données RUM en une seule vue, permettant aux équipes de surveiller l'ensemble de leur pile technologique en temps réel. Grâce à sa fonctionnalité principale, OpsAI, Middleware détecte, diagnostique et résout même automatiquement jusqu'à 70 % des problèmes, réduisant considérablement le temps de résolution et améliorant la productivité des développeurs. Elle offre une solution rentable et évolutive pour les entreprises de toutes tailles.
Signal0ne
Signal0ne est une plateforme AIOps alimentée par l'IA qui agit comme un assistant d'astreinte pour les équipes DevOps …
Signal0ne est une plateforme AIOps alimentée par l'IA qui agit comme un assistant d'astreinte pour les équipes DevOps et SRE. Elle automatise l'analyse des causes profondes en corrélant les signaux de votre pile d'observabilité existante, en enrichissant les alertes avec un contexte crucial et en suggérant des étapes de mitigation. Cela aide les équipes à réduire la fatigue des alertes et à diminuer considérablement le temps moyen de résolution (MTTR).
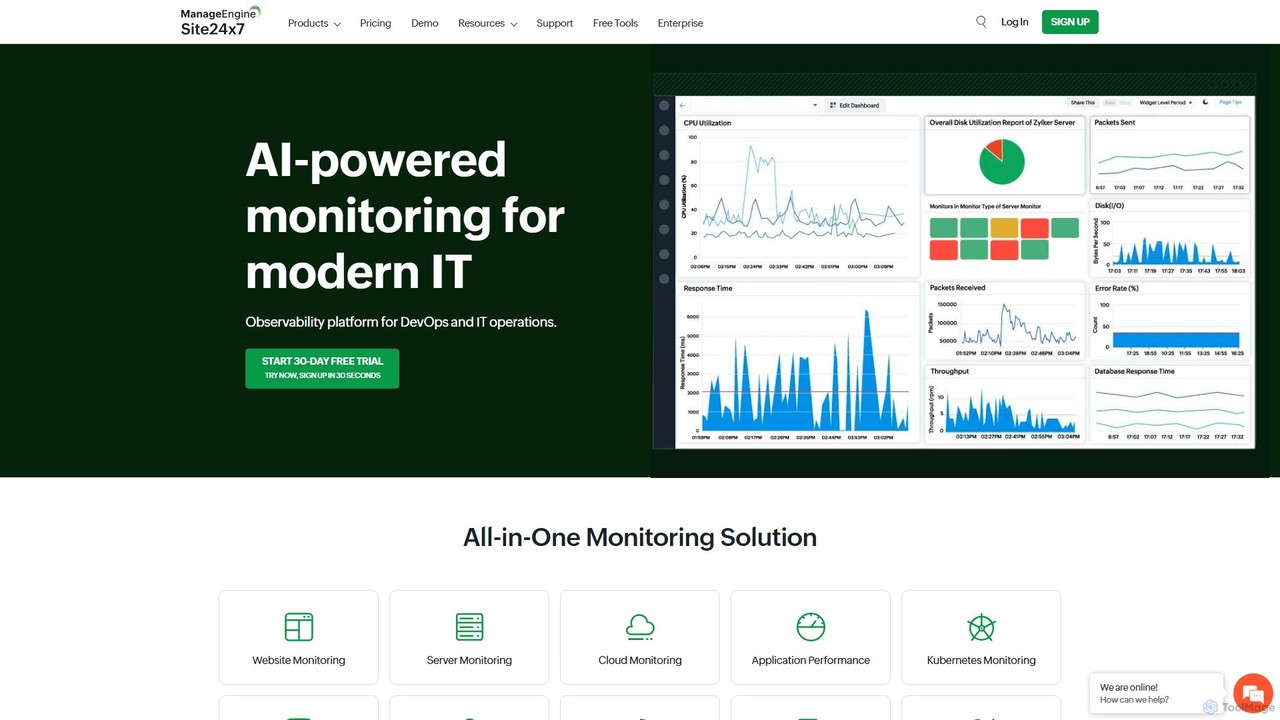
Site24x7
Site24x7 est une plateforme d'observabilité tout-en-un alimentée par l'IA pour le DevOps et les opérations informatiques. Elle fournit …
Site24x7 est une plateforme d'observabilité tout-en-un alimentée par l'IA pour le DevOps et les opérations informatiques. Elle fournit une surveillance complète des sites web, des serveurs, de l'infrastructure cloud (AWS, Azure, GCP), des réseaux et des applications à partir d'une seule console. Elle aide à garantir la disponibilité, à dépanner les problèmes de performance et à optimiser l'expérience utilisateur.
Pezzo
Pezzo est une plateforme d'IA open-source et axée sur les développeurs, conçue pour rationaliser l'ensemble du cycle de …
Pezzo est une plateforme d'IA open-source et axée sur les développeurs, conçue pour rationaliser l'ensemble du cycle de vie du développement de fonctionnalités d'IA. Elle permet aux équipes de construire, tester, surveiller et déployer des fonctionnalités alimentées par l'IA jusqu'à 10 fois plus rapidement grâce à une gestion centralisée des prompts, une observabilité en temps réel et des outils collaboratifs.
OpenLIT
OpenLIT est une plateforme d'observabilité open-source et native OpenTelemetry pour les applications d'IA Générative et de LLM. Elle …
OpenLIT est une plateforme d'observabilité open-source et native OpenTelemetry pour les applications d'IA Générative et de LLM. Elle simplifie le développement avec des outils de traçage de requêtes, de suivi des coûts, de surveillance des exceptions et d'analyse des performances. Dotée d'un référentiel de prompts centralisé, d'un coffre-fort sécurisé pour les secrets et d'un terrain de jeu pour comparer les LLM, OpenLIT offre une solution complète pour surveiller et faire évoluer efficacement les applications d'IA.

Valyr
Valyr (anciennement Helicone) est une plateforme open-source d'observabilité LLM et une passerelle IA. Elle aide les développeurs à …
Valyr (anciennement Helicone) est une plateforme open-source d'observabilité LLM et une passerelle IA. Elle aide les développeurs à surveiller, déboguer et analyser leurs applications IA, en fournissant une intégration unique pour accéder à plus de 100 modèles, gérer les coûts et améliorer la fiabilité avec des fonctionnalités comme la mise en cache et la limitation de débit.
Mezmo
Mezmo est une plateforme complète de pipeline de données de télémétrie conçue pour les développeurs, les équipes DevOps …
Mezmo est une plateforme complète de pipeline de données de télémétrie conçue pour les développeurs, les équipes DevOps et SRE. Elle permet aux utilisateurs d'ingérer, de traiter et d'analyser les logs, les métriques et les traces de n'importe quelle source. En mettant l'accent sur le contrôle et la rentabilité, Mezmo vous permet de filtrer, transformer et acheminer vos données d'observabilité vers n'importe quelle destination, optimisant ainsi les performances et réduisant les dépenses.
À propos de Observabilité
Les outils d'Observabilité sont des solutions basées sur l'IA conçues pour fournir des informations approfondies sur l'état interne et le comportement des systèmes logiciels complexes. En collectant et en analysant les métriques, les journaux et les traces, ces outils permettent aux équipes de développement et d'opérations de comprendre pourquoi les problèmes surviennent, de prédire les problèmes potentiels et d'optimiser les performances. Ils sont essentiels pour maintenir la fiabilité, l'efficacité et la résilience des applications modernes, en particulier dans les environnements distribués et natifs du cloud.
Fonctionnalités Clés
- Ingestion Automatisée des Données: Collecte automatiquement les métriques, les journaux et les traces de diverses sources (applications, infrastructure, services).
- Surveillance et Alertes en Temps Réel: Fournit des tableaux de bord pour la visualisation en temps réel de la santé du système et déclenche des alertes en cas d'anomalies ou de seuils prédéfinis.
- Traçage Distribué: Suit les requêtes à travers plusieurs services pour identifier les goulots d'étranglement de latence et les points de défaillance dans les architectures de microservices.
- Gestion et Analyse des Journaux: Centralise, indexe et analyse de vastes volumes de données de journaux pour le dépannage et l'audit de sécurité.
- Détection d'Anomalies par IA: Utilise l'apprentissage automatique pour identifier des modèles inhabituels dans le comportement du système qui pourraient indiquer des problèmes émergents.
Scénarios d'Application
Les outils d'Observabilité sont indispensables pour les SRE, les ingénieurs DevOps et les développeurs gérant des systèmes en production. Ils sont utilisés pour diagnostiquer rapidement la cause première des erreurs d'application, surveiller les performances des microservices et s'assurer que les objectifs de niveau de service (SLO) sont atteints. Par exemple, une équipe DevOps pourrait utiliser ces outils pour identifier une fuite de mémoire dans un service spécifique après un nouveau déploiement ou pour comprendre pourquoi une requête utilisateur subit une latence élevée à travers plusieurs composants backend.
Comment Choisir
Lors de la sélection d'un outil d'Observabilité, tenez compte de ses capacités de collecte de données (métriques, journaux, traces), de son intégration avec votre pile technologique existante et de son évolutivité pour gérer des volumes de données croissants. Évaluez ses fonctionnalités d'analyse et de visualisation en temps réel, y compris les tableaux de bord personnalisables et les mécanismes d'alerte. Évaluez également ses informations basées sur l'IA pour la détection d'anomalies et l'analyse des causes profondes, ainsi que son modèle de tarification basé sur l'ingestion et la rétention des données.
ObservabilitéCas d'utilisation
Diagnostiquer plus rapidement les incidents de production
Les ingénieurs en fiabilité des sites (SRE) utilisent les plateformes d'observabilité pour identifier rapidement la cause première des problèmes critiques en production. En corrélant les métriques, les journaux et les traces à travers les services distribués, ils peuvent rapidement identifier quel composant spécifique est en panne ou subit une dégradation des performances, réduisant ainsi le temps moyen de résolution (MTTR) et minimisant les temps d'arrêt pour les utilisateurs finaux.
Optimisation des performances des microservices
Les équipes de développement et DevOps exploitent le traçage distribué pour visualiser l'intégralité du flux de requêtes à travers une architecture de microservices complexe. Cela leur permet d'identifier les goulots d'étranglement de latence, les requêtes de base de données inefficaces ou les appels d'API lents entre les services, permettant des optimisations ciblées pour améliorer la réactivité globale de l'application et l'expérience utilisateur.
Détection proactive des anomalies
Les équipes d'opérations déploient des outils d'observabilité basés sur l'IA pour détecter automatiquement les modèles inhabituels dans le comportement du système qui pourraient indiquer un problème imminent. Par exemple, un pic soudain des taux d'erreur pour une API spécifique ou une baisse inattendue du débit peuvent être signalés avant qu'ils n'affectent les utilisateurs, permettant une intervention proactive et la prévention des pannes.
Assurer la conformité et les audits de sécurité
Les responsables de la sécurité et de la conformité utilisent les fonctionnalités de gestion centralisée des journaux pour collecter, stocker et analyser les journaux d'audit de tous les composants du système. Cela fournit une trace complète des activités, aidant à détecter les tentatives d'accès non autorisées, à enquêter sur les incidents de sécurité et à démontrer la conformité aux exigences réglementaires telles que le RGPD ou la HIPAA.
Planification de la capacité et gestion des ressources
Les ingénieurs d'infrastructure utilisent les métriques de performance historiques recueillies par les outils d'observabilité pour comprendre les tendances d'utilisation des ressources (CPU, mémoire, réseau). Ces données éclairent les décisions stratégiques pour la planification de la capacité, garantissant que des ressources suffisantes sont disponibles pour gérer les charges de pointe tout en évitant le surprovisionnement et les coûts d'infrastructure inutiles.
Validation des nouveaux déploiements et fonctionnalités
Les équipes de développement intègrent l'observabilité dans leurs pipelines CI/CD pour surveiller l'impact des nouveaux déploiements de code ou des nouvelles versions de fonctionnalités en temps réel. En observant les indicateurs clés de performance (KPI) et les taux d'erreur immédiatement après un déploiement, ils peuvent rapidement identifier les régressions ou les comportements inattendus et initier des retours en arrière si nécessaire, garantissant des versions stables.