
Models 概要
HathoraのModelsは、開発者やエンジニアが音声中心のアプリケーション向けに高性能AIモデルを効率的に発見、テスト、デプロイできるように設計された専門プラットフォームです。低遅延要件に焦点を当て、自動音声認識(ASR)、テキスト読み上げ(TTS)、大規模言語モデル(LLM)の厳選されたモデルを提供します。これらのモデルは、洗練された音声エージェントやリアルタイムのインタラクティブ体験を構築するために厳選され、最適化されており、本番環境への対応と簡単な統合を保証します。
Modelsの使い方
Modelsを使用するには、開発者はまず、音声AIのユースケース向けに特別に選ばれたオープンソースのASR、TTS、LLMモデルの包括的なカタログを探索することから始めます。モデルが選択されると、プラットフォームで提供されるインタラクティブなサンドボックス内で即座にテストできます。より複雑なシナリオでは、革新的なChainツールを使用すると、インタラクティブな音声AIパイプラインでASR、LLM、TTSモデルを一緒にテストできます。Pipecat、LiveKit、および直接APIアクセス用のドキュメントによりデプロイが合理化され、リアルタイムアプリケーションの迅速な開発が可能になります。
Modelsの主な機能
- 厳選されたモデルカタログ: 音声AI向けに最適化された厳選されたオープンソースASR、TTS、LLMモデルにアクセスできます。
- インタラクティブなテストサンドボックス: 専用のサンドボックスでモデルを即座に試用し、パフォーマンスと機能を評価します。
- Chainツール: ASR、LLM、TTSモデルを連携してテストし、エンドツーエンドの音声AIソリューションを実現するためのインタラクティブなパイプラインです。
- 高速デプロイオプション: Pipecat、LiveKit、および直接APIアクセス用のドキュメントにより、迅速な統合が可能です。
- 低遅延パフォーマンス: モデルはリアルタイムアプリケーションと音声エージェント向けに最適化されています。
- 多言語サポート: 多言語ASR用の`nvidia/parakeet-tdt-0.6b-v3`モデルや、100以上の言語をサポートする`Qwen/Qwen3-30B-A3B`モデルなどが含まれます。
- 単語レベルのタイムスタンプ: `nvidia/parakeet-tdt-0.6b-v3`などのASRモデルで利用でき、正確な文字起こしが可能です。
- 表現力豊かな音声合成: `ResembleAI/chatterbox`や`rime/arcana`などのTTSモデルは、自然で表現力豊か、感情豊かな音声を生成します。
- ゼロショット音声クローン: `nvidia/magpie-tts-zeroshot`のような近日公開予定のTTSモデルは、短いオーディオサンプルから音声クローンを提供します。
Modelsの使用例
Modelsは、幅広い音声AIアプリケーションの開発に最適です。自然に理解し応答する、応答性の高い音声アシスタントやチャットボットを構築するために使用できます。開発者は、リアルタイムの文字起こしサービスを作成し、ライブキャプションや会議の要約を可能にするために活用できます。そのTTS機能は、コンテンツ、インタラクティブ音声応答(IVR)システム、またはパーソナライズされたオーディオ体験のための自然で表現力豊かなナレーションを生成するのに最適です。さらに、LLM統合により、会話型AIにおける高度な推論と指示の実行が可能になり、顧客サービス、教育、エンターテイメントにおける複雑なエージェント機能に適しています。
Modelsの利点
Modelsの主な利点は、低遅延で本番環境対応の音声AIに焦点を当てていることです。開発者は、高品質なオープンソースモデルの厳選された選択肢から恩恵を受け、モデルの発見と評価にかかる時間を節約できます。独自のChainツールを含むインタラクティブなテスト環境は、異なるAIコンポーネントのシームレスな実験と統合を可能にすることで、開発サイクルを加速します。APIと人気のあるプラットフォームを介した高速デプロイオプションは、アプリケーションが迅速に稼働することを保証します。パフォーマンス、多言語サポート、単語レベルのタイムスタンプや表現力豊かな音声合成などの高度な機能に重点を置くことで、最先端の音声AIソリューションの堅牢な基盤を提供します。
Models よくある質問
Models コメント (0)
ログインするとコメントを投稿できます
今すぐログインModelsウェブサイトトラフィック分析
最新のトラフィック状況
ステータス
月間トラフィックの傾向
地域
上位5か国/地域
-
🇺🇸 United States100.00%
人気キーワード
| キーワード | クリック単価 |
|---|---|
|
$0.00
|
|
|
$0.00
|
|
|
$0.00
|
|
|
$0.00
|
|
|
$0.00
|
Models 代替案
すべて表示
Play
playは、企業向けの高度な音声AIプラットフォームで、超リアルなテキスト読み上げ(TTS)モデルとインテリジェントな音声エージェントに特化しています。これにより、企業はカスタマーサービス、営業、運用向けの24時間365日対応の自動エージェントを作成できます。カスタムナレッジベース、実世界のアクションを実行するためのAPI連携、データセキュリティのためのオンプレミス展開、30以上の言語サポートといった機能を備え、playは企業の音声コミュニケーションの拡大とグローバルな顧客エンゲージメントの強化を支援します。
playは、企業向けの高度な音声AIプラットフォームで、超リアルなテキスト読み上げ(TTS)モデルとインテリジェントな音声エージェントに特化しています。これにより、企業はカスタマーサービス、営業、運用向けの24時間365日対応の自動エージェントを作成できます。カスタムナレッジベース、実世界のアクションを実行するためのAPI連携、データセキュリティのためのオンプレミス展開、30以上の言語サポートといった機能を備え、playは企業の音声コミュニケーションの拡大とグローバルな顧客エンゲージメントの強化を支援します。
LangSearch
LangSearchは、LLMアプリケーションをクリーンで正確な実世界のコンテキストに接続するために設計された、無料のWeb検索およびセマンティックリランクAPIを提供します。自然言語クエリ、ハイブリッド検索をサポートし、AIエージェント、チャットボット、RAGシステムの検索結果精度を向上させる高効率なリランカーを提供します。
LangSearchは、LLMアプリケーションをクリーンで正確な実世界のコンテキストに接続するために設計された、無料のWeb検索およびセマンティックリランクAPIを提供します。自然言語クエリ、ハイブリッド検索をサポートし、AIエージェント、チャットボット、RAGシステムの検索結果精度を向上させる高効率なリランカーを提供します。
voice_vector
voice_vectorは、高忠実度の音声クローニング、表現力豊かなテキスト読み上げ(TTS)、正確な音声認識を提供する強力なAI音声プラットフォームです。独自の従量課金制とサブスクリプションのハイブリッドモデルにより、コンテンツ制作者、開発者、企業に柔軟で費用対効果の高いソリューションを提供します。無制限のプライベートクローン音声を作成し、堅牢なAPIを介して高度な音声機能をプロジェクトに統合できます。
voice_vectorは、高忠実度の音声クローニング、表現力豊かなテキスト読み上げ(TTS)、正確な音声認識を提供する強力なAI音声プラットフォームです。独自の従量課金制とサブスクリプションのハイブリッドモデルにより、コンテンツ制作者、開発者、企業に柔軟で費用対効果の高いソリューションを提供します。無制限のプライベートクローン音声を作成し、堅牢なAPIを介して高度な音声機能をプロジェクトに統合できます。
Gabber
Gabberは、見て、聞いて、話すことができるリアルタイムのマルチモーダルAIアプリケーションを構築するための強力なプラットフォームです。VLM(Vision Language Models)、TTS(Text-to-Speech)、STT(Speech-to-Text)の低遅延推論と、迅速な開発とデプロイメントのためのグラフベースのオーケストレーションシステムを組み合わせて提供します。
Gabberは、見て、聞いて、話すことができるリアルタイムのマルチモーダルAIアプリケーションを構築するための強力なプラットフォームです。VLM(Vision Language Models)、TTS(Text-to-Speech)、STT(Speech-to-Text)の低遅延推論と、迅速な開発とデプロイメントのためのグラフベースのオーケストレーションシステムを組み合わせて提供します。
Reducto
Reductoは、開発者および企業向けの高度なドキュメント取り込みAPIです。Agentic OCRと視覚言語モデルを使用して、ドキュメントを正確に解析、分割、抽出し、編集まで行います。様々なファイル形式の非構造化データを、構造化されたLLM対応の入力に変換し、複雑なドキュメント処理ワークフローを高い精度とエンタープライズレベルのセキュリティで自動化します。
Reductoは、開発者および企業向けの高度なドキュメント取り込みAPIです。Agentic OCRと視覚言語モデルを使用して、ドキュメントを正確に解析、分割、抽出し、編集まで行います。様々なファイル形式の非構造化データを、構造化されたLLM対応の入力に変換し、複雑なドキュメント処理ワークフローを高い精度とエンタープライズレベルのセキュリティで自動化します。
DistributeAI
DistributeAIは、開発者にスケーラブルで低コストのオープンソースAIモデルの広範なライブラリへのアクセスを提供する分散型AIスーパーコンピュータプラットフォームです。開発者フレンドリーなAPIとSDKを通じてAIアプリケーションの構築と展開を可能にし、ユーザーがアイドル状態のコンピューティングパワーを提供して収益化することもできます。
DistributeAIは、開発者にスケーラブルで低コストのオープンソースAIモデルの広範なライブラリへのアクセスを提供する分散型AIスーパーコンピュータプラットフォームです。開発者フレンドリーなAPIとSDKを通じてAIアプリケーションの構築と展開を可能にし、ユーザーがアイドル状態のコンピューティングパワーを提供して収益化することもできます。
Zetic.ai
Zetic.aiは、開発者が高価なGPUサーバーなしでAIモデルをエッジデバイスに直接デプロイできるようにするプラットフォームです。その自動化パイプラインであるZETIC.MLangeは、オンデバイス実行のためにモデルを最適化・変換し、NPUアクセラレーションにより最大60倍のパフォーマンス向上を実現し、データプライバシーを確保し、遅延を削減します。
Zetic.aiは、開発者が高価なGPUサーバーなしでAIモデルをエッジデバイスに直接デプロイできるようにするプラットフォームです。その自動化パイプラインであるZETIC.MLangeは、オンデバイス実行のためにモデルを最適化・変換し、NPUアクセラレーションにより最大60倍のパフォーマンス向上を実現し、データプライバシーを確保し、遅延を削減します。

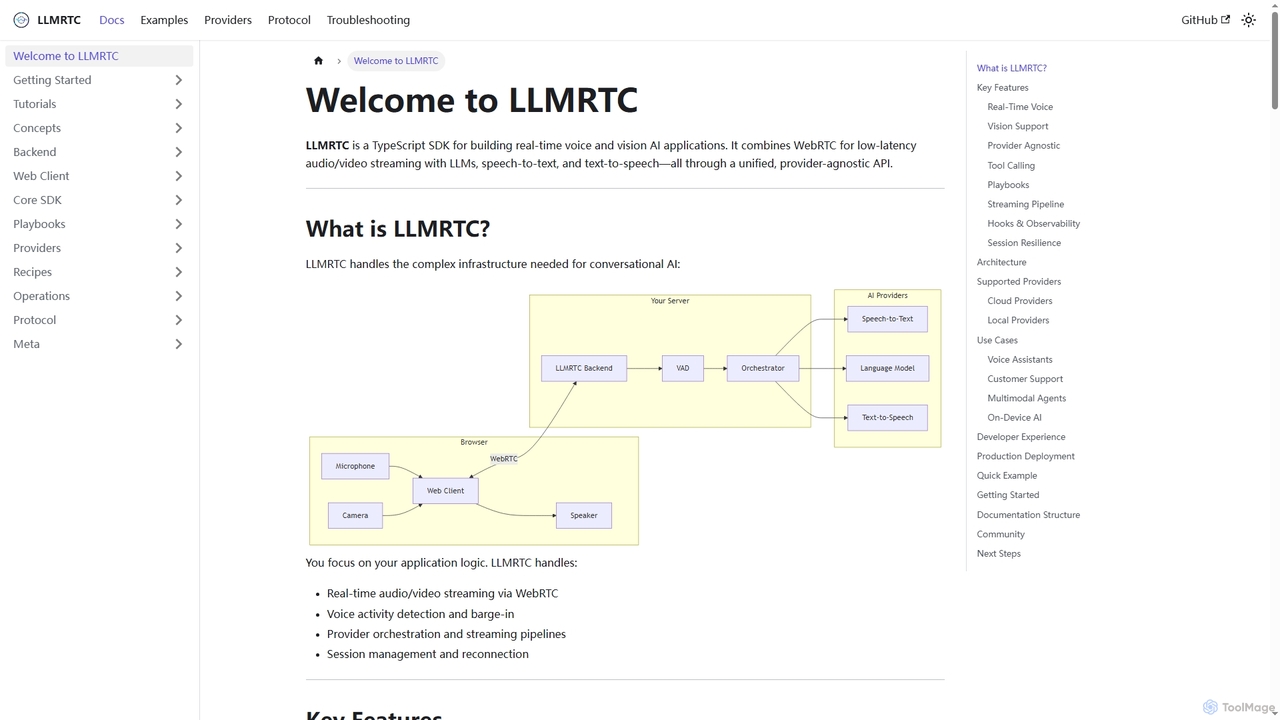
LLMRTC
LLMRTCは、リアルタイムの音声およびビジョンAIアプリケーション構築のためのTypeScript SDKです。WebRTCによる低遅延のオーディオ/ビデオストリーミングと、LLM、音声認識、音声合成技術を、統一されたプロバイダー非依存のAPIを通じてシームレスに統合します。開発者はアプリケーションロジックに集中でき、LLMRTCが複雑な会話型AIインフラストラクチャを処理します。
LLMRTCは、リアルタイムの音声およびビジョンAIアプリケーション構築のためのTypeScript SDKです。WebRTCによる低遅延のオーディオ/ビデオストリーミングと、LLM、音声認識、音声合成技術を、統一されたプロバイダー非依存のAPIを通じてシームレスに統合します。開発者はアプリケーションロジックに集中でき、LLMRTCが複雑な会話型AIインフラストラクチャを処理します。
Models タグ
Models 適用職種
Models AIツール
Models 埋め込み機能
下の埋め込みコードをコピーし、素敵なバッジをあなたのブログ、記事、またはアプリの公式サイトに貼り付けるだけで、このツールの詳細ページに直接トラフィックを誘導し、露出とユーザー数を素早く増やすことができます!

まだコメントはありません。最初のコメントをしてみませんか!