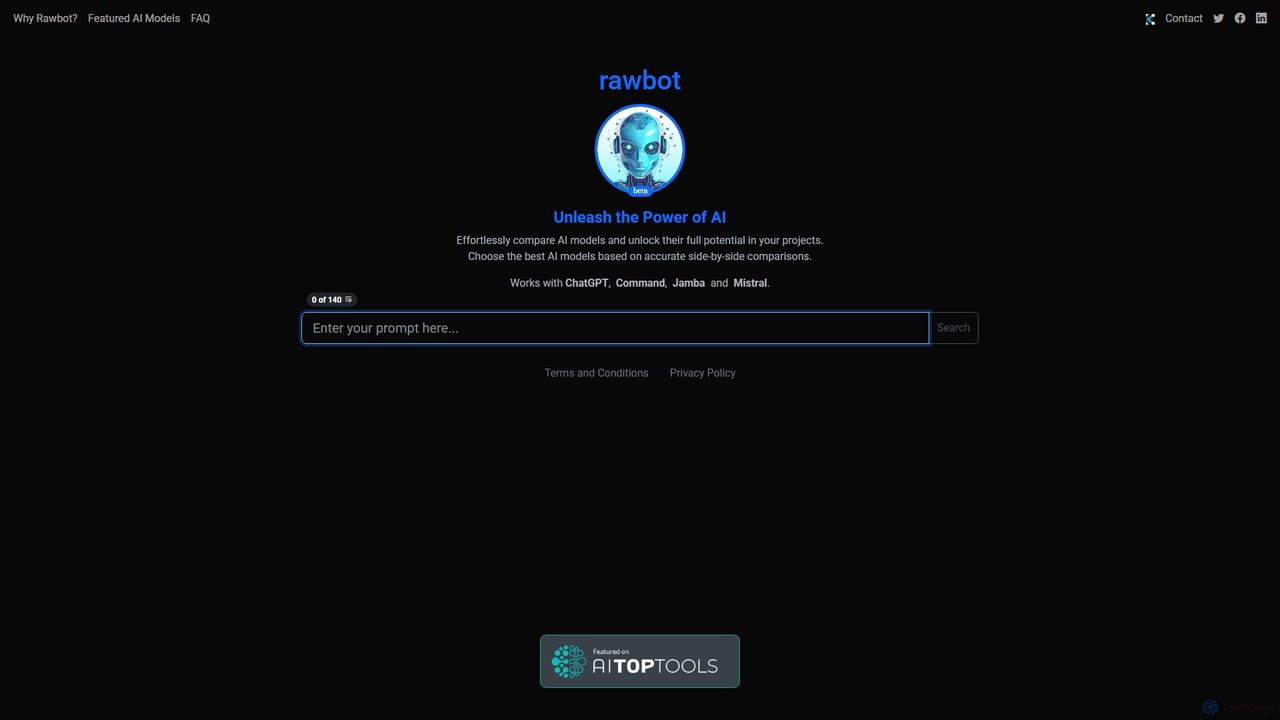
Rawbot
Rawbot là một công cụ AI trực quan để so sánh song song các mô hình ngôn ngữ …
Rawbot là một công cụ AI trực quan để so sánh song song các mô hình ngôn ngữ lớn một cách đơn giản và hiệu quả. Nhập một câu lệnh duy nhất và xem ngay lập tức các phản hồi từ nhiều mô hình khác nhau như ChatGPT, Mistral, Jamba và Command. Điều này giúp các nhà phát triển, nhà văn và nhà nghiên cứu đưa ra quyết định sáng suốt bằng cách đánh giá trực tiếp hiệu suất, phong cách và độ chính xác của mô hình cho nhu cầu cụ thể của họ, hợp lý hóa quy trình lựa chọn mô hình.
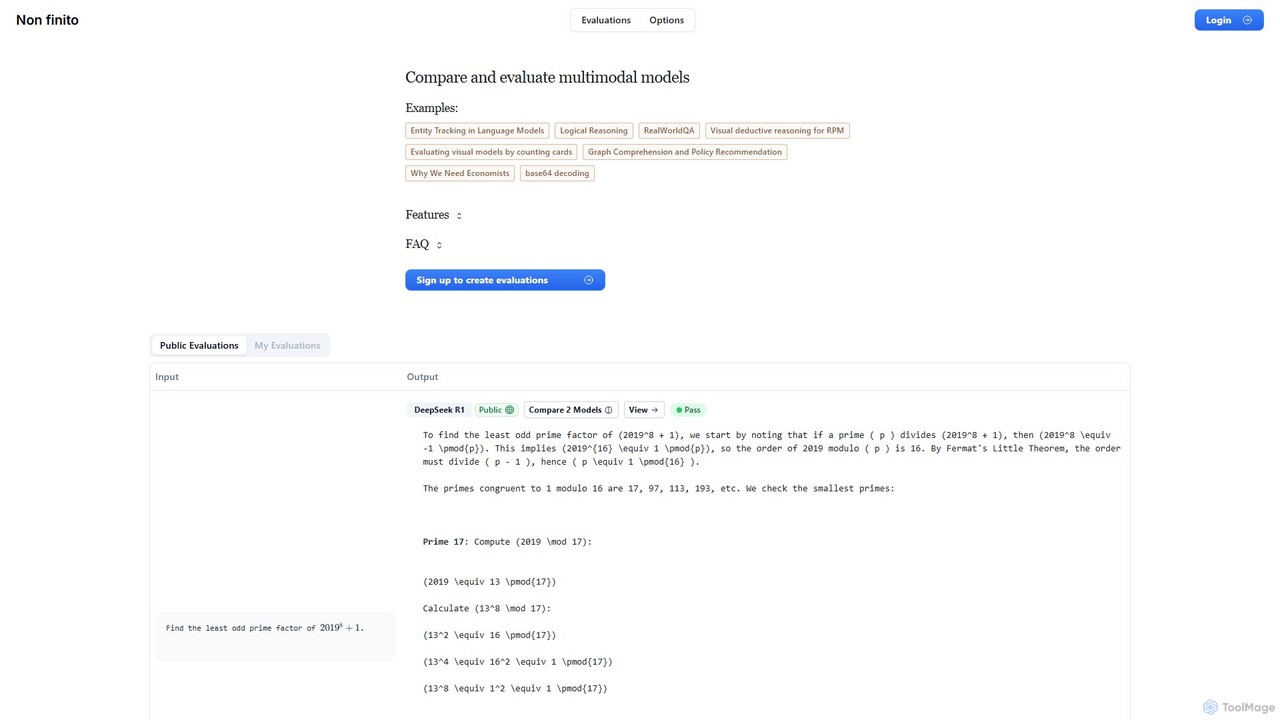
nonfinito
nonfinito là một nền tảng toàn diện để đánh giá và so sánh các mô hình AI đa …
nonfinito là một nền tảng toàn diện để đánh giá và so sánh các mô hình AI đa phương thức. Nó cho phép các nhà phát triển, nhà nghiên cứu và doanh nghiệp kiểm tra song song các LLM khác nhau trên các câu lệnh tùy chỉnh, đánh giá hiệu suất của chúng bằng xếp hạng đạt/không đạt và phân tích kết quả thô. Tạo các bài kiểm tra benchmark công khai hoặc riêng tư để tìm ra mô hình tốt nhất cho bất kỳ tác vụ nào.
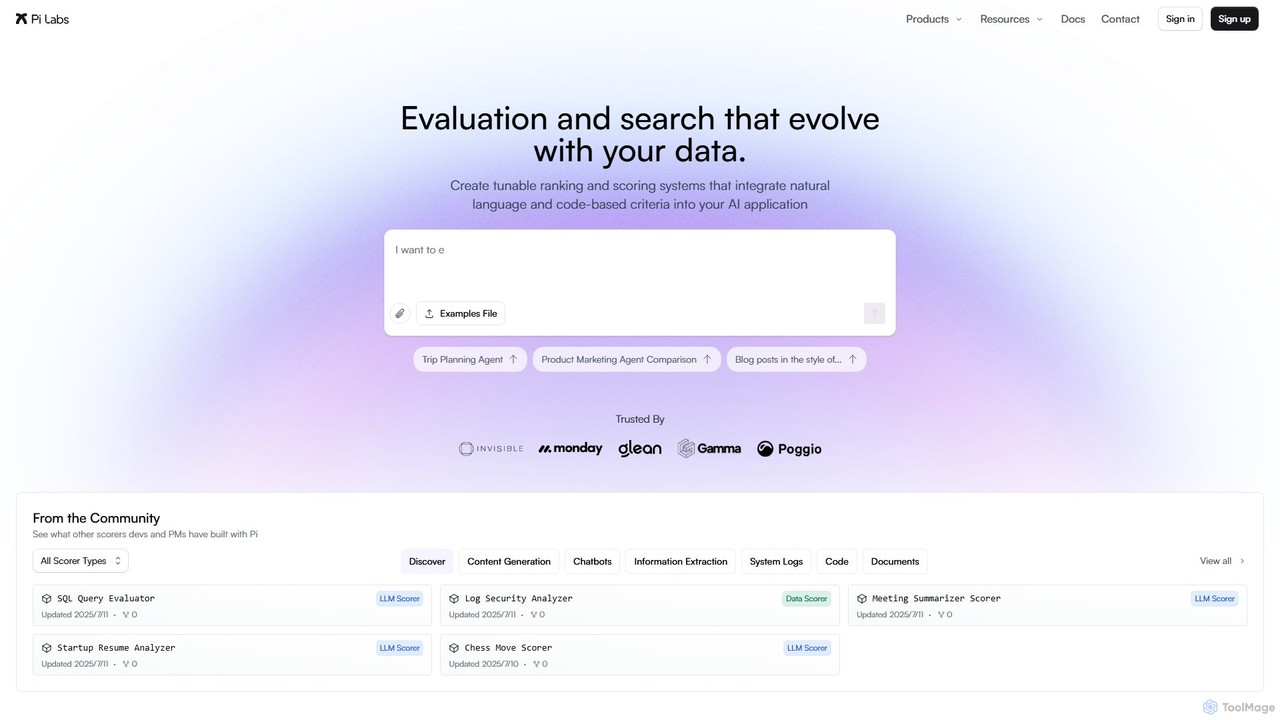
withpi.ai
Một nền tảng tập trung vào nhà phát triển để tạo ra các hệ thống chấm điểm và …
Một nền tảng tập trung vào nhà phát triển để tạo ra các hệ thống chấm điểm và đánh giá có thể điều chỉnh, nhanh chóng và tiết kiệm chi phí cho các ứng dụng AI. Nó chuyển đổi các tiêu chí định tính thành các chỉ số định lượng chính xác để giám sát mô hình, xếp hạng và tối ưu hóa RAG.
AfterQuery
AfterQuery là một phòng thí nghiệm nghiên cứu AI chuyên sâu về việc thúc đẩy các mô hình …
AfterQuery là một phòng thí nghiệm nghiên cứu AI chuyên sâu về việc thúc đẩy các mô hình nền tảng bằng cách tạo ra các bộ dữ liệu chất lượng cao do con người tạo ra và các tiêu chuẩn đánh giá không bị nhiễm bẩn. Nó tập trung vào việc cải thiện hiệu suất mô hình thông qua dữ liệu đào tạo vượt trội và đánh giá nghiêm ngặt.
OverallGPT
OverallGPT là một nền tảng sáng tạo cho phép bạn so sánh song song các câu trả lời …
OverallGPT là một nền tảng sáng tạo cho phép bạn so sánh song song các câu trả lời từ các mô hình AI hàng đầu như GPT-4, Claude, Gemini và Llama. Nó giúp bạn hiểu được điểm mạnh và điểm yếu riêng của chúng, và thậm chí tạo ra một 'Câu trả lời tổng thể' tổng hợp kết hợp các khía cạnh tốt nhất của mỗi câu trả lời, cho phép bạn đưa ra quyết định sáng suốt hơn và nâng cao năng suất.
Về Đánh giá mô hình
Công cụ Đánh giá Mô hình là các nền tảng chuyên dụng để đánh giá một cách có hệ thống về hiệu suất, độ chính xác và độ tin cậy của các mô hình học máy. Các công cụ này tự động hóa việc tính toán các chỉ số chính như độ chính xác (precision), độ bao phủ (recall), và điểm F1, đồng thời kiểm tra các yếu tố như độ lệch và độ bền. Chúng rất cần thiết cho các nhà phát triển và đội ngũ MLOps để xác thực hành vi của mô hình, so sánh các phiên bản khác nhau và đảm bảo hệ thống AI sẵn sàng cho môi trường sản xuất và hoạt động như dự kiến trong thế giới thực. Việc đánh giá nghiêm ngặt này xây dựng lòng tin và là một phần quan trọng trong chuỗi công cụ của nhà phát triển cho một AI có trách nhiệm.
Tính Năng Cốt Lõi
- Tính toán Chỉ số Tự động: Tự động tính toán một loạt các chỉ số hiệu suất (ví dụ: Accuracy, F1-Score, AUC-ROC) cho các tác vụ phân loại và hồi quy.
- Đo lường Hiệu suất Chuẩn: Cho phép so sánh song song nhiều mô hình hoặc phiên bản trên các bộ dữ liệu được tiêu chuẩn hóa để xác định mô hình hoạt động tốt nhất.
- Kiểm tra Độ lệch và Công bằng: Phát hiện và định lượng các độ lệch trong dự đoán của mô hình trên các nhóm nhân khẩu học hoặc phân đoạn dữ liệu khác nhau.
- Kiểm tra Độ bền: Đánh giá sự ổn định và hiệu suất của mô hình trước các cuộc tấn công đối kháng, sự trôi dạt dữ liệu và các đầu vào không mong muốn.
- Khả năng Giải thích và Trực quan hóa: Tạo báo cáo, bảng điều khiển và các hình ảnh trực quan (như biểu đồ SHAP hoặc LIME) để giúp diễn giải các dự đoán và hành vi của mô hình.
Trường Hợp Sử Dụng
Các công cụ Đánh giá Mô hình chủ yếu được sử dụng bởi các nhà khoa học dữ liệu, kỹ sư học máy và nhà nghiên cứu AI trong các lĩnh vực như tài chính, y tế và công nghệ. Ví dụ, một tổ chức tài chính sử dụng các công cụ này để đánh giá tính công bằng của các mô hình chấm điểm tín dụng, trong khi một công ty y tế xác thực độ chính xác của mô hình chẩn đoán hình ảnh trước khi sử dụng lâm sàng. Chúng là một phần không thể thiếu của bất kỳ quy trình MLOps nào để đảm bảo chất lượng mô hình.
Cách Lựa Chọn
Khi chọn một công cụ Đánh giá Mô hình, hãy xem xét khả năng tương thích của nó với các framework mô hình của bạn (ví dụ: TensorFlow, PyTorch, scikit-learn). Đánh giá sự đa dạng của thư viện chỉ số và khả năng hỗ trợ các chỉ số tùy chỉnh. Đánh giá khả năng tích hợp của nó với hệ sinh thái MLOps hiện tại của bạn, chẳng hạn như các công cụ theo dõi thử nghiệm và quy trình CI/CD. Cuối cùng, hãy xem xét các tính năng cộng tác, báo cáo và các nhu cầu cụ thể như đánh giá LLM hoặc thị giác máy tính.
Đánh giá mô hìnhTrường hợp sử dụng
Đo lường hiệu suất phản hồi của LLM cho Chatbot
Một đội ngũ dịch vụ khách hàng sử dụng công cụ đánh giá mô hình để so sánh hai mô hình ngôn ngữ lớn (ví dụ: một mô hình mã nguồn mở đã được tinh chỉnh so với một API thương mại) cho chatbot mới của họ. Họ tải lên một 'bộ dữ liệu vàng' gồm các câu hỏi thường gặp của người dùng và các câu trả lời mong muốn. Công cụ tự động chạy cả hai mô hình, chấm điểm đầu ra của chúng dựa trên các chỉ số như mức độ liên quan, độ chính xác về giọng điệu và tính nhất quán về mặt thực tế, và trình bày một bảng điều khiển so sánh song song. Điều này cho phép đội ngũ lựa chọn một cách khách quan mô hình cung cấp trải nghiệm người dùng tốt hơn trước khi triển khai.
Kiểm tra tính công bằng của mô hình tuyển dụng
Một công ty công nghệ nhân sự sử dụng nền tảng đánh giá mô hình để kiểm tra công cụ sàng lọc hồ sơ do AI cung cấp. Nền tảng này phân tích các quyết định của mô hình trên một bộ dữ liệu thử nghiệm được chú thích bằng thông tin nhân khẩu học (ví dụ: giới tính, dân tộc). Nó tạo ra một báo cáo về tính công bằng, nêu bật bất kỳ sự chênh lệch thống kê nào trong tỷ lệ đề xuất giữa các nhóm khác nhau. Quá trình này giúp công ty xác định và giảm thiểu các thiên vị tiềm ẩn, đảm bảo công cụ của họ thúc đẩy các hoạt động tuyển dụng công bằng và tuân thủ các quy định.
Xác thực mô hình chẩn đoán hình ảnh y tế
Một công ty khởi nghiệp AI trong lĩnh vực chăm sóc sức khỏe đang phát triển một mô hình thị giác máy tính để phát hiện các bất thường trong ảnh X-quang. Trước khi xin cấp phép theo quy định, họ sử dụng một công cụ đánh giá mô hình để kiểm tra nghiêm ngặt hiệu suất của nó. Công cụ này tính toán các chỉ số quan trọng như độ nhạy, độ đặc hiệu và điểm AUC-ROC so với một bộ dữ liệu đã được các chuyên gia X-quang xác thực. Nó cũng tạo ra các hình ảnh trực quan, chẳng hạn như bản đồ nhiệt, cho thấy mô hình tập trung vào phần nào của hình ảnh để đưa ra dự đoán. Điều này cung cấp bằng chứng quan trọng về độ chính xác và độ tin cậy của mô hình để sử dụng trong lâm sàng.
Kiểm thử hồi quy cho hệ thống phát hiện gian lận
Một công ty fintech tích hợp một công cụ đánh giá mô hình vào quy trình CI/CD của mình. Trước khi triển khai phiên bản mới của mô hình phát hiện gian lận, một công việc tự động được kích hoạt. Công cụ này chạy mô hình mới trên một bộ dữ liệu được tuyển chọn gồm các mẫu gian lận lịch sử và các giao dịch bình thường. Sau đó, nó so sánh điểm F1 và tỷ lệ dương tính giả của mô hình mới với các tiêu chuẩn của mô hình đang hoạt động. Nếu hiệu suất giảm sút, việc triển khai sẽ tự động bị dừng lại, ngăn chặn một mô hình bị lỗi được đưa vào sản xuất và đảm bảo sự ổn định của hệ thống.
So sánh các công cụ đề xuất bằng thử nghiệm A/B
Một nền tảng thương mại điện tử muốn thử nghiệm một thuật toán đề xuất mới so với thuật toán hiện có. Họ sử dụng một khung đánh giá mô hình để thiết lập một thử nghiệm A/B, hướng 50% lưu lượng người dùng đến mỗi mô hình. Khung này ghi lại các tương tác của người dùng (nhấp chuột, mua hàng) cho cả hai nhóm. Sau một tuần, một nhà khoa học dữ liệu sử dụng bảng điều khiển của công cụ để so sánh các chỉ số kinh doanh chính như tỷ lệ nhấp (CTR) và tỷ lệ chuyển đổi. So sánh trực quan và các bài kiểm tra ý nghĩa thống kê cho thấy rõ thuật toán nào thúc đẩy sự tương tác và doanh thu nhiều hơn, cho phép đưa ra quyết định dựa trên dữ liệu.
Giám sát sự trôi dạt dữ liệu và khái niệm trong sản xuất
Một đội ngũ MLOps sử dụng một công cụ đánh giá để liên tục giám sát một mô hình dự báo nhu cầu đã được triển khai. Công cụ này so sánh phân phối thống kê của dữ liệu sản xuất trực tiếp với phân phối dữ liệu huấn luyện, tự động gắn cờ sự trôi dạt dữ liệu nếu có sự khác biệt đáng kể. Nó cũng giám sát độ chính xác dự đoán của mô hình trên dữ liệu đầu vào. Nếu độ chính xác giảm theo thời gian ngay cả khi dữ liệu đầu vào trông tương tự, điều đó báo hiệu sự trôi dạt khái niệm (tức là các mối quan hệ cơ bản đã thay đổi). Những cảnh báo này thúc đẩy đội ngũ điều tra và có khả năng huấn luyện lại mô hình trước khi hiệu suất của nó ảnh hưởng nghiêm trọng đến hoạt động kinh doanh.