关于 评估
评估工具是一类旨在系统性评估AI模型性能、公平性和鲁棒性的AI驱动解决方案。这类工具利用各种指标、测试数据集和分析框架,深入洞察模型行为。它们的主要目的是确保模型在部署前后都可靠、准确且符合伦理,在更广泛的AI模型管理生命周期中发挥关键作用。
核心功能
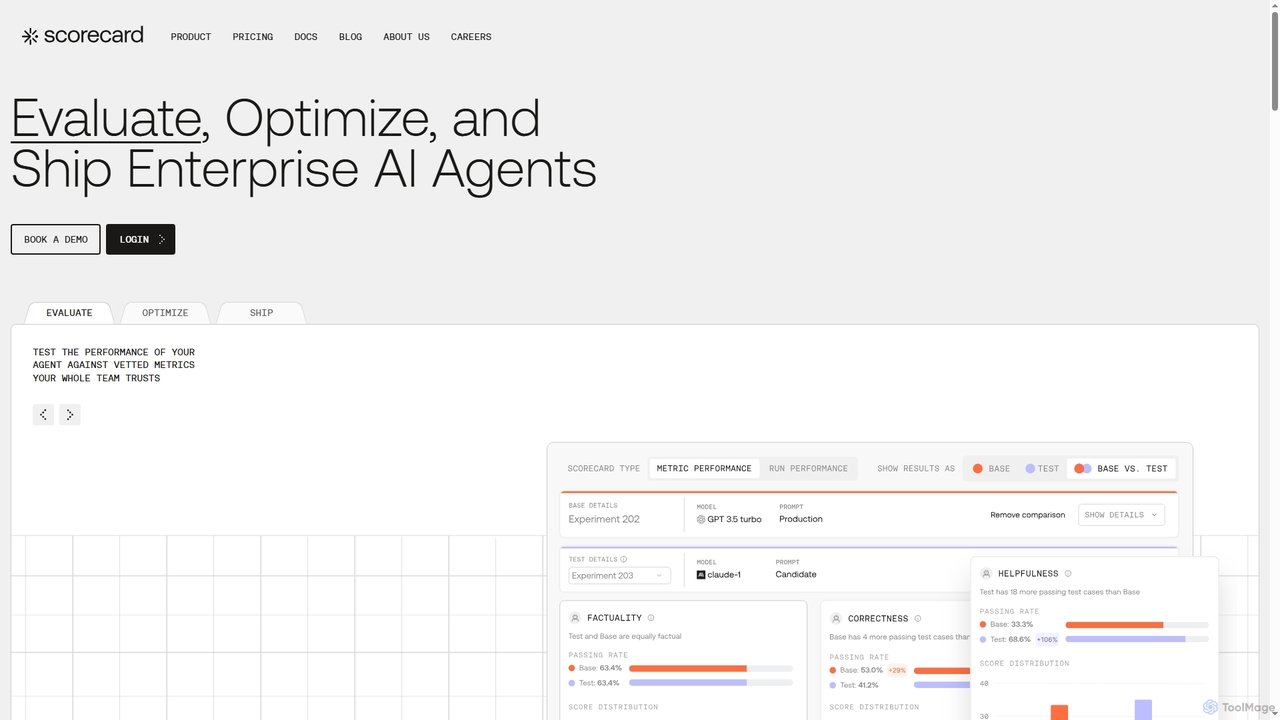
- 性能指标计算:量化模型准确率、精确率、召回率、F1分数及其他相关指标。
- 偏见检测与缓解:识别并衡量不同人口统计群体或数据段中的算法偏见。
- 鲁棒性测试:评估模型面对对抗性攻击或意外数据漂移时的稳定性和弹性。
- 可解释性(XAI)集成:提供模型做出特定预测的原因洞察,增强透明度。
- 模型版本比较:比较不同模型迭代或版本的性能,以追踪改进。
适用场景
AI模型评估工具在AI生命周期的各个阶段都至关重要。数据科学家利用它们进行严格的部署前验证,确保新模型达到性能基准。MLOps团队依靠它们持续监控已部署模型,检测性能漂移或数据质量问题。此外,研究人员和开发者也利用这些工具比较不同的模型架构并优化其AI解决方案。
选择要点
选择AI模型评估工具需要考虑多个因素。优先选择支持与您的模型类型和业务目标相关的全面评估指标的工具。寻找与您现有MLOps管道和数据源的强大集成能力。可扩展性、可解释性功能和强大的报告功能对于有效的模型治理和合规性也至关重要。
评估应用场景
部署前模型验证
数据科学家利用评估工具,在部署前对新的AI模型(例如欺诈检测系统)进行严格测试,以对抗多样化的数据集。这确保模型达到准确性和可靠性基准,识别可能导致生产中代价高昂错误的潜在弱点或边缘情况。此过程有助于验证模型在实际应用中的准备情况,从而最大限度地降低风险。
偏见与公平性评估
AI伦理学家和开发者利用评估平台系统性地检测和量化模型中的偏见,例如用于贷款申请或招聘的模型。通过分析不同人口统计群体间的预测结果,他们可以识别不公平的输出,理解其根本原因,并实施策略来缓解歧视行为,从而确保AI的道德部署。
持续性能监控
MLOps工程师将评估工具集成到其生产管道中,以持续监控已部署AI模型(例如推荐引擎)的性能。这些工具会随时间跟踪关键指标,在性能下降、数据漂移或概念漂移时向团队发出警报,从而实现主动干预,以保持模型的准确性和相关性。
比较模型选择
机器学习研究人员利用评估工具比较多个候选模型或同一模型的不同版本的性能。例如,在开发自然语言处理模型时,他们可以客观评估哪种架构或哪组超参数在各种语言任务中产生最佳结果,从而指导最佳模型选择。
监管合规报告
金融或医疗保健等受监管行业的企业使用评估工具为其AI系统生成全面的审计跟踪和性能报告。这有助于证明其符合行业标准和监管要求,例如可解释性指令或公平性指南,从而向审计师和利益相关者提供透明度和问责制。
对抗性鲁棒性测试
安全专家应用评估工具,针对对抗性攻击测试AI模型,特别是在自动驾驶或网络安全等关键应用中。通过模拟旨在欺骗模型的恶意输入,他们可以评估其鲁棒性并识别漏洞,从而增强模型抵御复杂威胁的能力,并确保其在敌对环境中的可靠性。