Reliable Agents
一个关于代理式自动化(agentic automation)的权威指南和基准测试平台。它为开发者提供交互式市场地图、性能分析和关于网页浏览及计算机控制工具的报告,帮助他们构建可靠的AI代理。
一个关于代理式自动化(agentic automation)的权威指南和基准测试平台。它为开发者提供交互式市场地图、性能分析和关于网页浏览及计算机控制工具的报告,帮助他们构建可靠的AI代理。
关于 基准测试
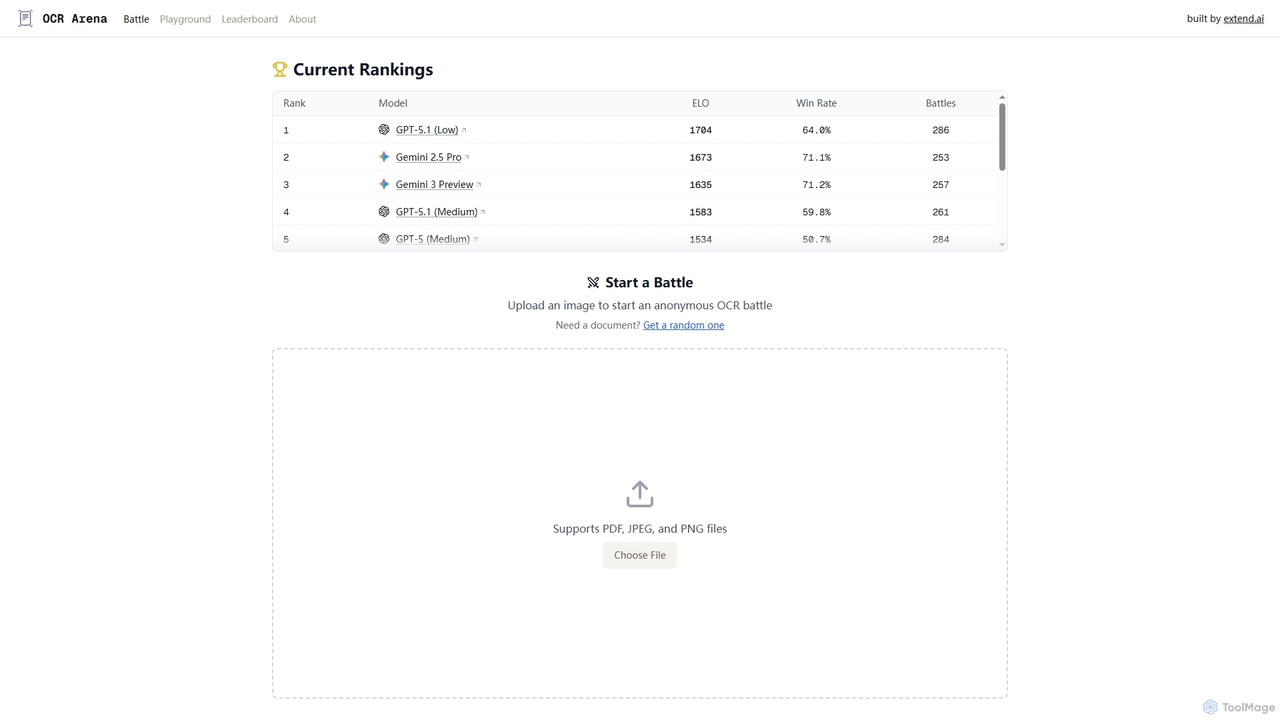
AI基准测试工具是一类专门的开发者工具,用于系统性地评估和比较AI模型、算法及硬件的性能。它们通过在通用数据集上执行标准化测试,来衡量准确率、推理速度、延迟和资源消耗等关键指标。这个过程提供客观、数据驱动的洞见,帮助开发者识别性能瓶颈、验证改进效果,并为其AI系统选择最合适的组件。这类工具对于确保结果的可复现性以及对照行业标准跟踪进展至关重要。
核心功能
- 标准化测试套件:为图像分类或自然语言处理等常见任务提供预配置的基准和数据集。
- 性能指标跟踪:衡量包括准确率、F1分数、延迟、吞吐量和内存使用在内的广泛指标。
- 对比分析:提供并排的仪表板,以比较不同模型、框架或硬件设置的性能。
- 环境控制:确保测试条件的一致性和可复现性,以保证公平可靠的比较。
- 排行榜生成:根据选定的性能指标自动对模型或系统进行排名,便于清晰评估。
适用场景
这些工具对于监控生产模型的MLOps工程师、比较新颖算法的AI研究人员,以及评估新型AI加速器效率的硬件制造商至关重要。它们也常用于CI/CD流水线中,进行自动化的性能回归测试。
选择要点
选择基准测试工具时,应考虑其对您特定AI框架(如TensorFlow、PyTorch)的支持程度、可跟踪指标的广度、其处理大规模实验的扩展能力,以及与您现有开发工作流和基础设施的集成能力。
基准测试应用场景
为生产部署选择模型
一个MLOps团队需要部署一个新的欺诈检测模型。他们使用基准测试工具在标准化数据集上评估三个候选模型。该工具不仅衡量预测准确率,还衡量推理延迟和内存占用。根据显示其中一个模型为其实时API提供了最佳准确率与速度平衡的对比报告,团队自信地选择了该模型进行部署。
评估AI加速器硬件
一家半导体公司正在为AI工作负载推出一款新的GPU。为了展示其优越性,他们的团队使用行业标准的基准测试套件(如MLPerf)进行测试。他们在BERT和ResNet-50等模型上,将其GPU的性能(吞吐量和能效)与竞争对手进行比较。生成的排行榜成为证明其硬件价值的关键营销资产。
确保学术研究的可复现性
一个大学研究实验室开发了一种新颖的优化算法。为了发表他们的研究成果,他们必须证明其相对于现有方法的有效性。他们使用一个基准测试框架,在受控环境中运行所有实验,细致地跟踪训练时间、收敛速度和最终模型准确率。这确保了他们的结果是可复现的,并为同行评审提供了公平、可验证的比较。
CI/CD中的自动化回归测试
一家软件公司将基准测试工具集成到其AI功能的CI/CD流水线中。每当开发人员提交新代码时,流水线会自动在一组黄金数据集上触发基准测试。该工具会检查更改是否对处理速度或输出质量产生了负面影响。如果检测到性能回归,构建将失败,从而防止较慢的代码进入生产环境。
优化云基础设施成本
一家初创公司正在部署计算机视觉服务,并希望最大限度地降低运营费用。他们使用基准测试工具在各种云实例类型(例如,不同的CPU/GPU配置)上测试其模型的性能。该工具通过将性能数据与公共云定价相关联来衡量每次推理的成本。这种分析帮助他们确定了既能满足其延迟服务等级协议(SLA)又最具成本效益的实例。
验证和比较LLM API
一个产品团队正在构建一个依赖大型语言模型(LLM)API的应用程序。他们正在考虑几个提供商,并使用基准测试工具向每个API发送一组精选的提示。该工具根据响应质量(使用评估模型)、延迟和速率限制来评估和比较这些提供商,使团队能够就集成哪个API做出明智的、有数据支持的决策。