Hatchet
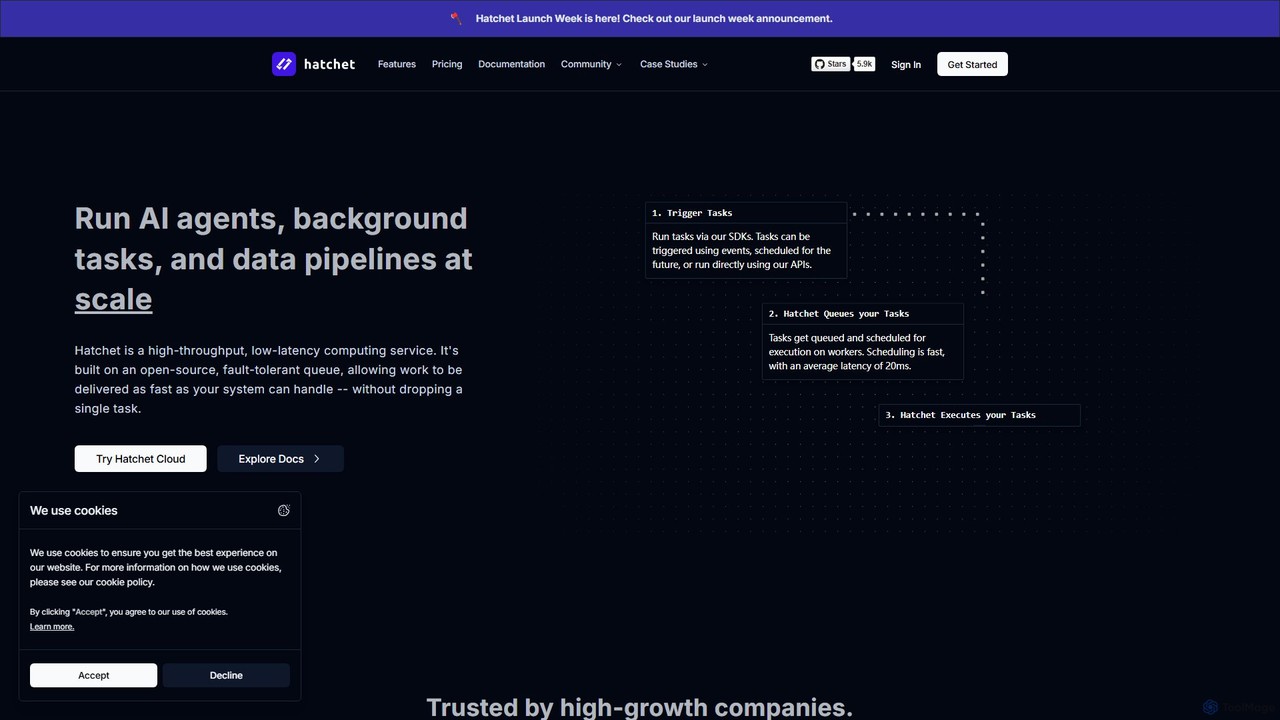
Hatchet 是一个分布式的、容错的任务队列,专为大规模运行 AI 代理、后台任务和数据管道而设计。它提供高吞吐量、低延迟的性能,确保不会丢失任何任务。借助适用于 Python、Go 和 TypeScript 的 SDK,开发人员可以轻松编排复杂的工作流、调度作业,并通过内置的可观测性工具监控执行。它既可以作为托管云服务使用,也可以自托管。
Hatchet 是一个分布式的、容错的任务队列,专为大规模运行 AI 代理、后台任务和数据管道而设计。它提供高吞吐量、低延迟的性能,确保不会丢失任何任务。借助适用于 Python、Go 和 TypeScript 的 SDK,开发人员可以轻松编排复杂的工作流、调度作业,并通过内置的可观测性工具监控执行。它既可以作为托管云服务使用,也可以自托管。
关于 编排
编排工具是AI驱动的解决方案,旨在自动化协调、管理和扩展复杂的AI工作流、模型和基础设施组件。这类工具利用先进的自动化和资源管理技术,确保各种AI服务、数据管道和计算资源能够无缝高效地协同工作。它们的核心价值在于简化整个AI生命周期,从开发、训练到部署和监控,显著减少手动操作,加速创新。
核心功能
- 工作流自动化:自动化执行AI管道中的顺序或并行任务,包括数据预处理、模型训练和部署。
- 资源管理:根据实时工作负载需求,动态分配和释放GPU、CPU等计算资源。
- 模型生命周期管理:管理AI模型在其整个运行周期中的版本控制、部署、扩展和持续监控。
- 集成能力:提供与各种AI服务、数据源以及云或本地部署环境的无缝连接。
- 监控与日志:通过详细的日志记录,提供工作流状态、资源利用率和模型性能的全面实时洞察。
适用场景
编排工具对于管理端到端机器学习工作流(从数据摄取到模型服务)的ML工程师和数据科学家至关重要。它们对于构建需要不同AI模型同步执行的多模态AI应用的开发者,以及在分布式计算基础设施上训练大型模型的研究人员也至关重要。
选择要点
选择AI编排平台时,应优先考虑其与现有工具和云提供商的集成生态系统。评估其可扩展性和灵活性以适应不同的工作负载,并评估其监控和可观测性功能的稳健性。同时,考虑平台的易用性、抽象级别以及整体成本效益,以确保其符合您的运营和预算需求。
编排应用场景
自动化MLOps管道部署
ML工程师在将机器学习模型持续部署到生产环境时常面临挑战,这涉及数据验证、特征工程、训练、评估和部署。编排工具自动化这些复杂的多阶段MLOps管道,在新数据或代码提交时触发每个步骤,并管理依赖关系和资源分配。这确保了模型可靠、快速的部署,将手动工作量减少高达70%,并加速AI解决方案的上市时间。
扩展AI推理服务
AI应用开发者需要确保其推理端点能够处理波动的用户需求,同时避免过度配置昂贵的资源。编排工具持续监控实时流量和模型延迟,自动在Kubernetes集群或无服务器环境中扩展或缩减推理实例(例如GPU Pods)的数量。这保证了AI服务的高可用性和响应速度,通过仅为实际消耗的资源付费来优化基础设施成本。
管理分布式AI模型训练
AI研究人员和ML工程师在训练大型基础模型时,需要将工作负载分布到多个GPU或机器上,这协调起来非常复杂。编排平台管理数据和模型参数的分布,协调集群中的训练任务,处理容错,并聚合结果。这使得大规模AI模型能够高效、稳健地训练,显著减少训练时间和操作复杂性,同时最大化计算资源利用率。
集成多模态AI工作流
构建复杂的AI应用,例如结合语音识别、自然语言处理和文本转语音的智能助手,需要无缝集成和顺序执行不同的AI模型。编排工具定义并管理这些多样化AI服务之间的数据流,将一个模型的输出作为下一个模型的输入,确保数据一致性和及时执行。这通过简化组件协调,从而简化了复杂、多功能AI应用的创建。
自动化AI数据预处理
数据工程师和科学家在模型训练前,需要花费大量时间对原始数据进行清洗、转换和特征提取。编排系统自动化整个数据管道,从各种来源摄取数据,经过多个预处理步骤(例如归一化、分词),直到存储准备好的特征。这确保了AI模型获得高质量、一致的数据,显著减少了手动数据准备时间,并提高了整体模型性能和可靠性。
持续AI模型监控与再训练
已部署的AI模型可能会受到数据漂移或概念漂移的影响,导致性能随时间下降。手动监控和再训练是资源密集型的。编排工具持续跟踪生产中的模型性能指标和数据特征。如果性能下降或检测到漂移,系统会自动触发再训练管道,并可能重新部署更新后的模型。这在动态环境中保持最佳模型准确性和相关性,确保AI应用在最少人工干预下保持有效。