
KubeHA
KubeHA 是一个由生成式AI驱动的SaaS平台,专为Kubernetes设计,提供监控、可观测性、修复和探索(MORE)的一体化解决方案。它统一了日志、指标、追踪和事件,提供AI驱动的根本原因分析、智能修复建议和一键式修复,消除了工具泛滥问题,为SRE和DevOps团队简化了复杂的操作。
KubeHA 是一个由生成式AI驱动的SaaS平台,专为Kubernetes设计,提供监控、可观测性、修复和探索(MORE)的一体化解决方案。它统一了日志、指标、追踪和事件,提供AI驱动的根本原因分析、智能修复建议和一键式修复,消除了工具泛滥问题,为SRE和DevOps团队简化了复杂的操作。
smallhours
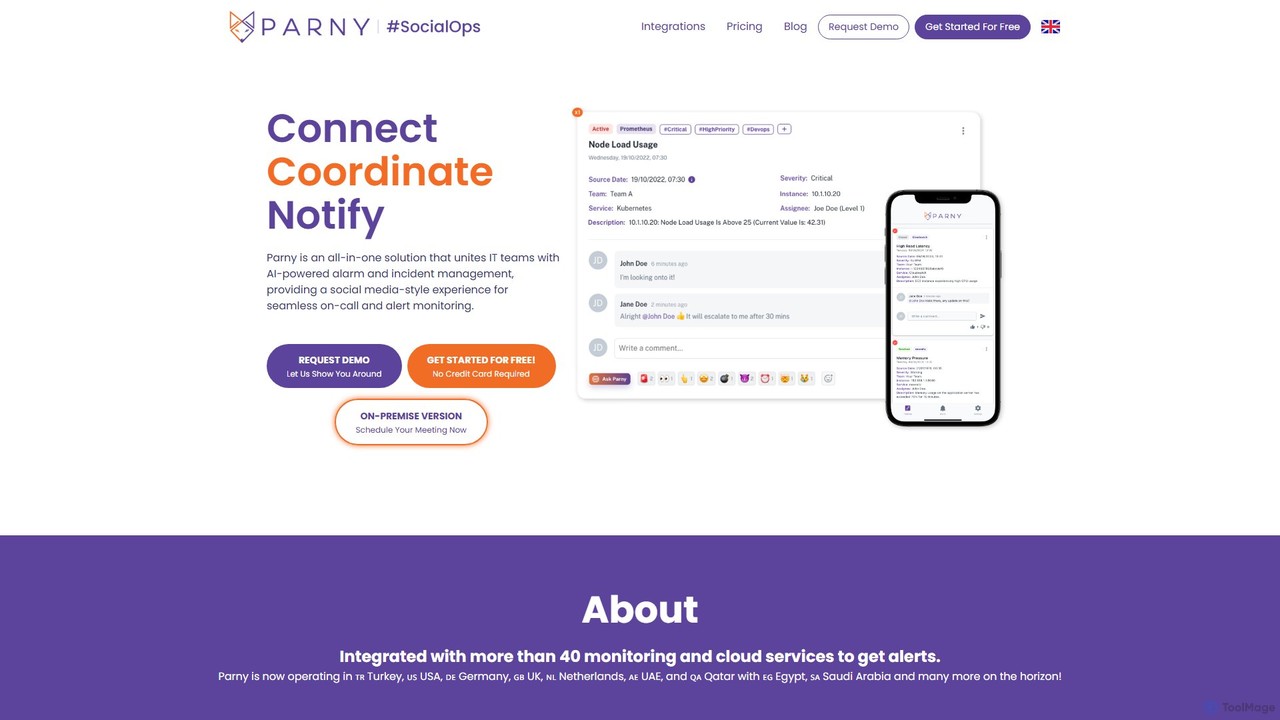
smallhours 是一个为开发者打造的AI平台,可实现全天候自动化根本原因分析(RCA)。它通过OpenTelemetry与您的技术栈集成,监控系统,利用您的代码库和运行手册作为上下文诊断问题,将解决时间加快10倍,从而最大限度地减少停机时间并简化值班职责。
smallhours 是一个为开发者打造的AI平台,可实现全天候自动化根本原因分析(RCA)。它通过OpenTelemetry与您的技术栈集成,监控系统,利用您的代码库和运行手册作为上下文诊断问题,将解决时间加快10倍,从而最大限度地减少停机时间并简化值班职责。
Botkube
Botkube 是一款开源的协作式 Kubernetes AI 助手。它直接集成到您的 Slack 和 Microsoft Teams 等聊天平台中,集中进行实时监控、警报和故障排除。它通过将 K8s 管理引入您的日常通信工具,赋能开发人员独立管理其应用程序,并简化 DevOps 工作流程。
Botkube 是一款开源的协作式 Kubernetes AI 助手。它直接集成到您的 Slack 和 Microsoft Teams 等聊天平台中,集中进行实时监控、警报和故障排除。它通过将 K8s 管理引入您的日常通信工具,赋能开发人员独立管理其应用程序,并简化 DevOps 工作流程。

Releem
Releem 是一款由 AI 驱动的 MySQL 性能调优工具,旨在实现数据库管理的自动化。它能自动检测性能瓶颈,提供优化的服务器配置,并为 SQL 查询和索引提出改进建议。Releem 是开发人员、数据库管理员和托管服务提供商的理想选择,通过用户友好的仪表盘和持续的健康监控,简化复杂的数据库任务,提升应用速度,并降低基础设施成本。
Releem 是一款由 AI 驱动的 MySQL 性能调优工具,旨在实现数据库管理的自动化。它能自动检测性能瓶颈,提供优化的服务器配置,并为 SQL 查询和索引提出改进建议。Releem 是开发人员、数据库管理员和托管服务提供商的理想选择,通过用户友好的仪表盘和持续的健康监控,简化复杂的数据库任务,提升应用速度,并降低基础设施成本。
关于 监控
AI监控工具是一类使用机器学习来自动观测和分析IT系统健康状况与性能的软件。它超越了传统的基于阈值的警报,通过学习正常的运行模式来智能检测异常、预测潜在故障并识别根本原因。这使得IT运维团队能够在问题影响用户之前主动解决,从而显著减少停机时间并提高系统可靠性。这类工具是现代智能运维(AIOps)策略的核心组成部分。
核心功能
- 智能异常检测:无需预定义规则,自动识别系统行为与正常基线的偏差。
- 预测性分析:基于历史数据预测未来的性能问题或资源短缺。
- 自动化根因分析(RCA):关联来自不同数据源的事件,精确定位问题的源头。
- 动态阈值:根据系统负载和模式的变化自动调整警报阈值。
- 警报降噪:将相关警报分组并过滤掉无关通知,使团队能专注于关键事件。
适用场景
AI监控工具主要由技术驱动行业的IT运维、DevOps和网站可靠性工程(SRE)团队使用。例如,电商平台利用它预测流量高峰,以防止在促销活动期间服务器过载。软件公司则可以利用这些工具在新版本发布前识别应用程序代码中的性能瓶颈,确保流畅的用户体验。
选择要点
选择AI监控工具时,需考虑其与现有技术栈(如云服务商、数据库、CI/CD管道)的集成能力。评估其机器学习模型在异常检测和根因分析方面的成熟度。此外,还应考察其仪表盘的清晰度、警报系统的灵活性以及定价模式(可能基于主机、数据量或用户数)。
监控应用场景
主动预防电商平台服务中断
一家在线零售公司的SRE团队使用AI监控工具来确保大型促销活动期间的高可用性。该工具分析实时交易数据、服务器指标和用户行为。它检测到支付网关中一个传统监控工具会忽略的、细微且不寻常的延迟模式。通过将此模式与数据库查询时间的轻微增加相关联,AI预测数据库可能在一小时内过载。它自动向团队发出警报并指出具体根本原因,使他们能够主动扩展数据库资源,从而防止了一场可能造成数百万收入损失的全站服务中断。
自动化应用程序性能调试
一家SaaS公司的DevOps工程师将新的代码更新推送到生产环境。不久之后,AI监控工具检测到API错误率飙升,以及某个特定微服务的内存消耗逐渐增加。它没有生成数百个独立的警报,而是将日志、追踪和指标关联起来,精确定位到新代码中导致内存泄漏的具体函数。工程师收到的不是零散的警报,而是一份内容丰富的单一事件报告,这将平均解决时间(MTTR)从数小时的手动日志筛选缩短到仅几分钟的定向调试。
通过异常检测优化云成本
一个云基础设施团队管理着一个庞大的多云环境。AI监控工具持续分析资源利用模式。它识别出一组为临时项目配置但从未取消配置的虚拟机,这些虚拟机目前处于闲置状态并产生费用。它还标记了一个由于配置错误的扩展策略而持续过度配置资源的自动扩展组。通过标记这些成本异常,该工具帮助团队在不影响服务性能的情况下,将每月云账单节省超过20%。
早期安全威胁检测
一个安全运营(SecOps)团队将AI监控工具与其安全信息和事件管理(SIEM)系统集成。该工具建立了正常网络流量和用户活动的行为基线。然后,它标记了一次“低慢”数据窃取企图——一个被盗用的账户在很长一段时间内导出少量数据以逃避检测。AI识别出这种传统基于规则的安全警报无法发现的异常行为,并触发一个高优先级事件,使SecOps团队能够在发生重大数据丢失之前控制住这次泄露。
物联网设备的预测性维护
一家制造公司在其工厂车间部署了数千个物联网传感器。一个AI监控平台接收来自这些传感器的遥测数据,如温度、振动和压力。通过分析历史数据,AI模型学习特定机器部件的故障模式。它预测一个关键电机由于异常的振动特征,在未来72小时内发生故障的可能性为85%。这个预测性警报使维护团队能够在非工作时间安排更换,从而避免了代价高昂的意外停机和生产损失。
结合业务背景改善数字体验
一家金融服务公司使用AI监控工具来跟踪其在线银行平台的性能。该工具被配置为理解业务KPI,例如“成功贷款申请数”或“已完成的资金转账”。当它检测到贷款申请完成率下降时,它会自动将此业务指标与底层的IT性能数据相关联。它发现下降与身份验证服务中一个运行缓慢的特定API调用有关。这使得IT团队能够根据直接的业务影响,而不仅仅是技术严重性,来优先处理修复工作。