thisorthis.ai
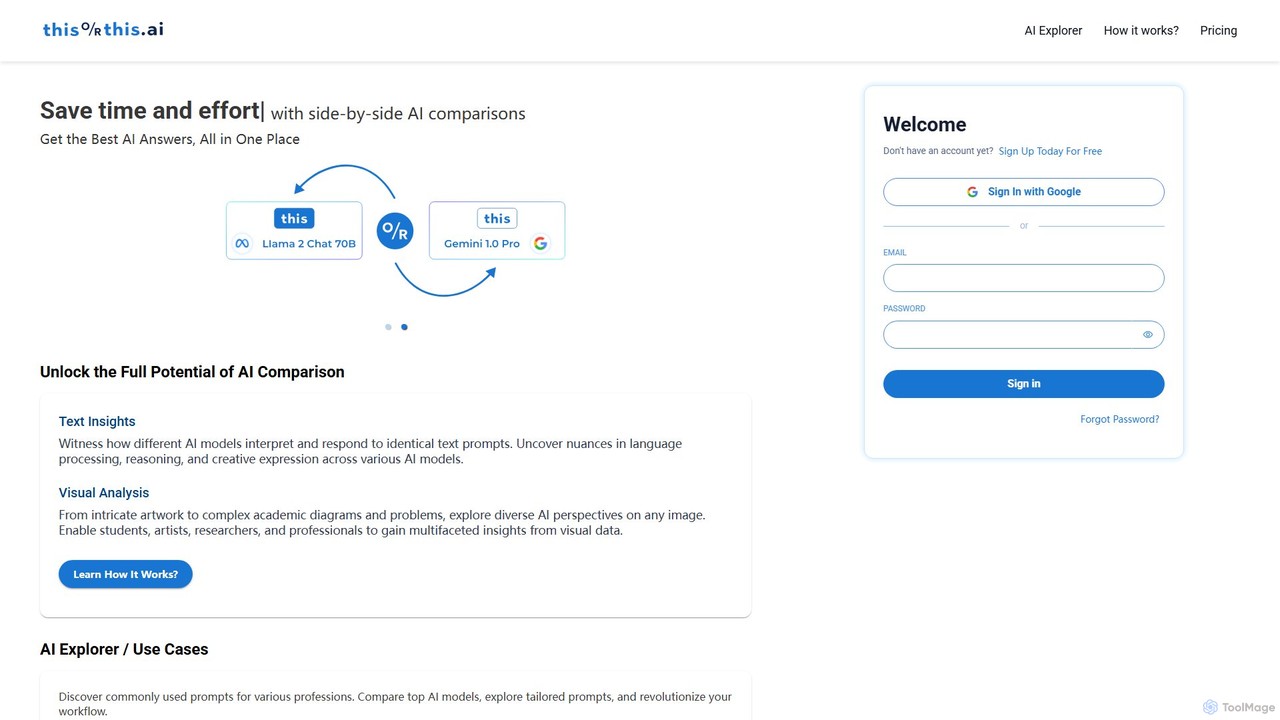
thisorthis.ai 是一个强大的生成式AI模型并排比较平台。只需提交一个提示(文本或图片),即可同时接收并评估多达6个不同模型(如GPT-4o、Gemini 1.5和Llama 3)的输出。它采用灵活的即用即付模式,无需多个订阅。对于希望为任何任务找到最优质AI生成回复的专业人士和研究人员来说,它是优化效率和产出质量的理想选择。
thisorthis.ai 是一个强大的生成式AI模型并排比较平台。只需提交一个提示(文本或图片),即可同时接收并评估多达6个不同模型(如GPT-4o、Gemini 1.5和Llama 3)的输出。它采用灵活的即用即付模式,无需多个订阅。对于希望为任何任务找到最优质AI生成回复的专业人士和研究人员来说,它是优化效率和产出质量的理想选择。
ChatPlayground AI
终极的AI语言模型并排比较平台。在单一、直观的界面中,对GPT-4o、Gemini、Claude、Llama等模型测试提示词,为您的需求找到最佳模型。
终极的AI语言模型并排比较平台。在单一、直观的界面中,对GPT-4o、Gemini、Claude、Llama等模型测试提示词,为您的需求找到最佳模型。
geminivsgpt
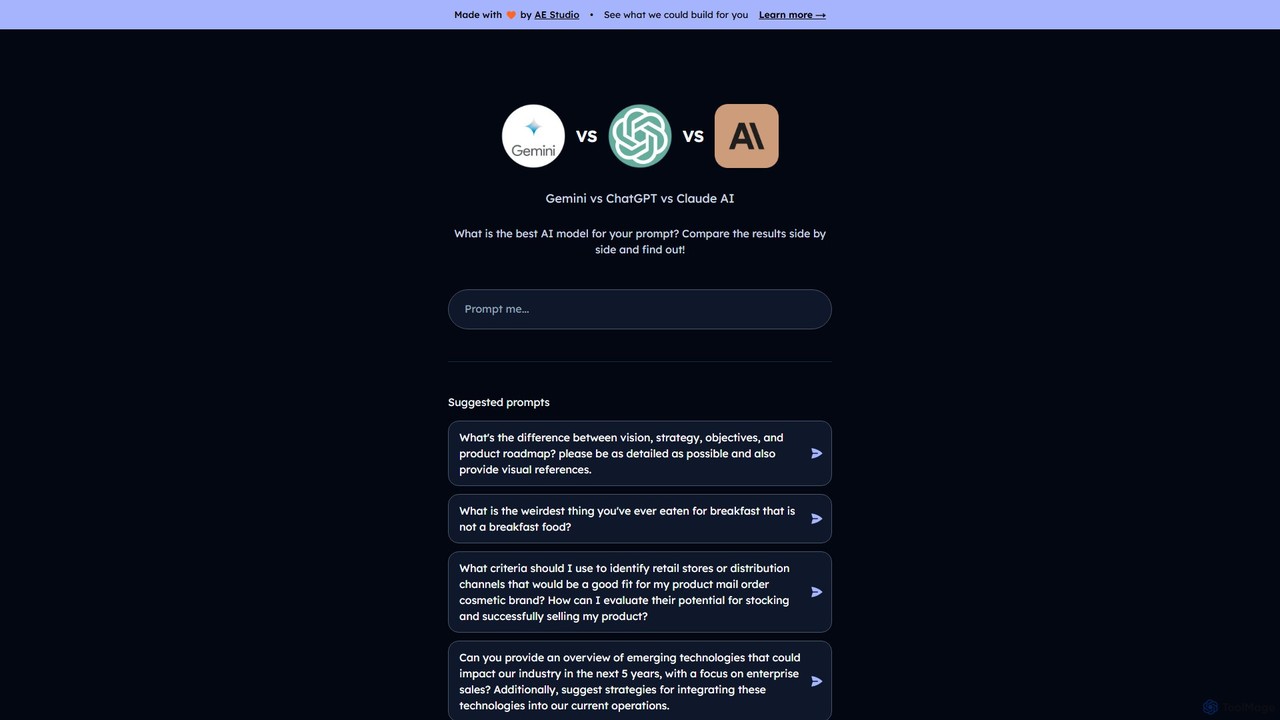
一款功能强大的免费在线工具,可即时比较来自谷歌Gemini、OpenAI ChatGPT和Anthropic Claude等主流AI模型的回复。输入单个提示词,并排查看结果,从而为您的写作、编码、研究和头脑风暴等特定需求确定最佳输出。
一款功能强大的免费在线工具,可即时比较来自谷歌Gemini、OpenAI ChatGPT和Anthropic Claude等主流AI模型的回复。输入单个提示词,并排查看结果,从而为您的写作、编码、研究和头脑风暴等特定需求确定最佳输出。
关于 模型比较
模型比较工具是一类专用平台,旨在使用同一提示词同时运行多个AI模型,以进行直接的并排评估。这类工具通过在统一界面中呈现大型语言模型(LLM)或图像生成器等不同模型的输出,简化了评估流程。用户可以客观地比较不同模型的响应质量、风格、准确性以及速度和成本等性能指标。通过免去逐一测试每个模型的繁琐工作,这些平台极大地提升了开发者、研究人员和内容创作者在决定集成或使用何种AI时的生产力。
核心功能
- 并排比较界面: 针对同一输入,并列显示来自不同模型的输出,便于直接比较文本或图像。
- 多模型支持: 集成来自OpenAI、Anthropic、Google等不同提供商以及开源社区的多种主流和特定领域的AI模型。
- 性能分析: 提供关键指标,如响应时间(延迟)、令牌数量以及每个模型输出的预估成本。
- 提示词管理: 允许用户保存、版本化和组织提示词,以进行可重复的系统性测试。
- API访问: 提供编程接口以运行比较,支持将其集成到自动化测试工作流和应用程序中。
适用场景
这类工具对于开发者选择最合适且最具成本效益的API、内容创作者优化提示词以找到最匹配品牌声调的模型、以及AI研究人员对模型能力进行基准测试都非常有价值。企业也使用它们来优化AI运营成本,通过识别能满足特定任务质量要求的更经济的模型。
选择要点
选择模型比较工具时,应考虑其支持的模型范围是否覆盖您的评估需求。评估其分析功能——是否提供您需要的成本、延迟和质量指标?同时,也要考量用户界面的易用性以及提示词管理和团队协作功能。对于开发者而言,用于自动化测试的API的可用性和文档质量是一个关键因素。
模型比较应用场景
为聊天机器人选择最佳LLM API
一位软件开发者正在构建一个客服聊天机器人,需要选择最有效且成本效益最高的语言模型(LLM)。通过使用模型比较工具,他们输入了50个常见的客户查询。该工具同时在GPT-4o、Claude 3 Sonnet和Llama 3上运行这些提示。开发者可以直接比较回复的相关性与语气、每个查询的平均延迟以及基于预期流量的各模型预估月度成本。这种数据驱动的方法让他们选择了Claude 3 Sonnet,因为它在特定用例中实现了质量与成本的最佳平衡,从而避免了数周的手动测试。
优化用于营销广告文案的提示词
一位营销文案撰稿人负责为新产品发布创作创意口号。他们使用模型比较工具,在多个以创意能力著称的模型(如GPT-4和Claude 3 Opus)上测试一个详细的提示词。并排显示的结果表明,一个模型擅长诙谐的俏皮话,而另一个模型则生成更具描述性和感染力的文本。通过观察这些不同的解读,文案撰稿人可以优化他们的提示词——例如增加“使用幽默语气”等约束条件——并为每种所需的广告文案类型确定最佳模型,从而确保营销活动更加多样化和有效。
评估用于游戏资产创作的图像模型
一位视频游戏工作室的概念艺术家需要为新的奇幻角色生成创意。他们使用一个支持图像生成模型的模型比较工具。艺术家输入一个详细的提示:“一位坚忍的精灵战士,身穿发光的银色盔甲,手持水晶长矛,身处黑暗的魔法森林中,照片级写实风格。” 该工具同时从DALL-E 3、Midjourney和Stable Diffusion生成图像。通过比较输出结果,艺术家注意到Midjourney产生了最具氛围感的灯光,Stable Diffusion在盔甲细节上表现更佳,而DALL-E 3最能捕捉面部表情。这使他们能够选择合适的工具,甚至结合不同输出的元素来完成最终的概念艺术。
关于AI模型偏见的学术研究
一位AI伦理研究员正在研究不同语言模型在讨论敏感话题时如何表现出偏见。他们使用模型比较工具,系统地将一系列与性别、种族和职业相关的提示词输入到包括开源和专有模型在内的十几个不同模型中。该工具的统一界面使他们能够高效地收集和分类数百个回复。然后,他们可以分析输出中是否存在刻板印象语言或偏见假设的模式,为他们的研究论文贡献宝贵的实证数据。能够一次性测试多个模型对于进行全面和比较性的研究至关重要。
为内部摘要任务优化AI成本
一家大公司的产品经理希望实施一项AI功能来总结内部周报。最初选择的GPT-4虽然提供高质量的摘要,但成本高昂。为了优化开支,该经理使用模型比较工具,在Mistral Large等更便宜的替代方案以及各种微调的开源模型上测试摘要提示。他们评估了10份样本报告,并并排比较输出的准确性和连贯性。该工具的成本估算器显示,其中一个开源模型以30%的成本提供了GPT-4 95%的质量。这使得公司能够在不大幅牺牲质量的情况下,经济高效地部署该功能。
模型能力教学演示
一位教授“人工智能导论”课程的大学教授在现场讲座中使用了模型比较工具。为了说明“模型对齐”的概念,他们输入了提示:“用一个五岁小孩能懂的简单类比来解释量子计算。” 该工具展示了来自一个高度技术化模型、一个通用模型和一个为教育内容微调的模型的答案。学生们可以立即看到每个模型如何不同地解释“简单类比”这一约束。这种实践演示比纯理论解释更能提供对模型优势和专业化的记忆深刻且直观的理解。