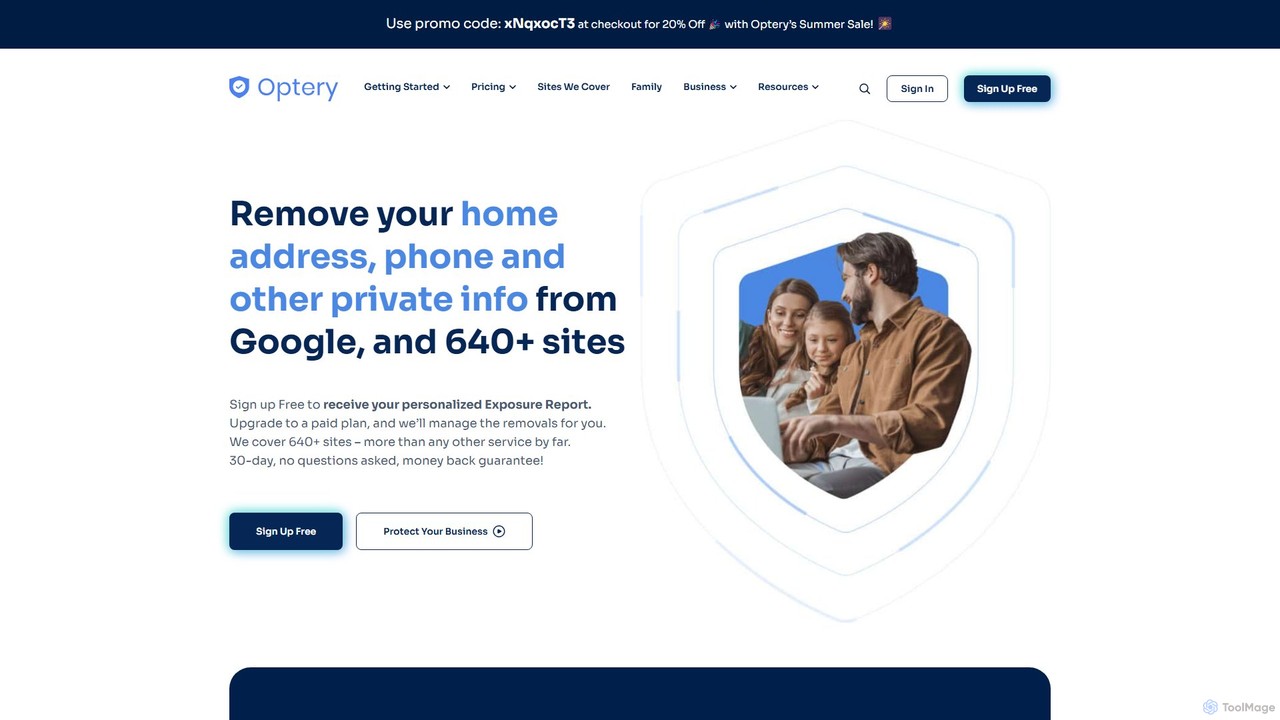
Optery
Optery 是一项自动化的数据移除服务,帮助您重获隐私。它会扫描超过640个数据代理和个人搜索网站,查找您被泄露的个人信息——如家庭住址、电话号码和电子邮件——并代表您自动提交退出请求。通过免费的自助工具和全面的付费计划,Optery能有效减少您的数字足迹,防止身份盗窃、垃圾信息和网络跟踪。
Optery 是一项自动化的数据移除服务,帮助您重获隐私。它会扫描超过640个数据代理和个人搜索网站,查找您被泄露的个人信息——如家庭住址、电话号码和电子邮件——并代表您自动提交退出请求。通过免费的自助工具和全面的付费计划,Optery能有效减少您的数字足迹,防止身份盗窃、垃圾信息和网络跟踪。
关于 隐私保护
AI隐私保护工具是一类利用人工智能保护个人及敏感数据的专业安全软件。它们采用数据匿名化、差分隐私和合成数据生成等技术,在数据处理与分析过程中最大限度地降低隐私风险。对于处理海量数据集的组织而言,这些工具至关重要,能在帮助其遵守GDPR、CCPA等法规的同时,依然提取有价值的洞察。其核心优势在于能自动化处理大规模、复杂且难以手动执行的隐私保护任务。
核心功能
- 数据匿名化与假名化:自动从数据集中移除或替换个人可识别信息(PII)。
- 合成数据生成:创建统计学上相似的人工数据集,其中不含任何真实用户信息,用于安全的测试与分析。
- 差分隐私:向数据输出中添加统计噪声,以保护个人身份,同时保持整体数据的准确性。
- 隐私风险评估:扫描数据集和系统,识别潜在的隐私漏洞和合规差距。
- 用户同意管理自动化:自动追踪和管理用户在不同平台上的数据使用同意授权。
适用场景
这类工具主要应用于医疗健康、金融和营销分析等处理大量敏感用户数据的行业。例如,医院可使用这些工具对患者记录进行匿名化处理以用于医学研究,营销公司则可以生成合成客户数据来训练推荐模型,而无需使用真实的客户信息。
选择要点
选择工具时,应考虑其提供的具体隐私技术(如匿名化或合成数据)。评估其与现有数据基础设施的兼容性,以及满足特定法规(如GDPR或HIPAA)要求的能力。此外,还需权衡隐私保护级别与数据效用之间的关系,因为更强的保护有时会降低数据分析的准确性。
隐私保护应用场景
为医学研究匿名化医疗数据
一家医学研究机构需要分析患者记录以识别疾病趋势。为遵守HIPAA法规,他们使用AI隐私保护工具自动处理数千份记录。该工具能识别并编辑所有个人可识别信息(PII),如姓名、地址和社会安全号码,并用不可识别的占位符替换。这使得研究人员可以安全地处理大规模健康数据,在不损害患者机密性的前提下加速医学发现。
为软件测试生成合成数据
一家金融科技公司正在开发一种新的欺诈检测算法。由于隐私法规的限制,他们不能使用真实的客户交易数据进行测试。因此,他们的开发团队使用合成数据生成工具。该工具分析真实数据的统计属性,并创建一个模仿其模式、分布和相关性的全新人工数据集。这使得开发人员可以在一个真实的环境中严格测试他们的算法,而无需暴露任何敏感的客户财务信息,从而确保了安全性和产品质量。
在营销分析中确保GDPR合规
一家欧洲电子商务公司通过分析客户行为来实现个性化营销。为遵守GDPR,他们使用差分隐私工具查询客户数据库。当分析师运行查询(例如“按城市划分的平均购买价值是多少?”)时,该工具会向结果中添加经过数学校准的统计噪声。这为业务决策提供了准确的汇总洞察,同时在数学上使其无法通过逆向工程数据来识别任何单个人的购买习惯,从而在默认情况下保护了用户隐私。
从法律文件中编辑敏感信息
一家律师事务所需要与外部法律顾问共享数千份案件文件,但必须首先编辑所有机密的客户信息。手动审查每份文件既慢又容易出错。他们部署了一款AI隐私保护工具,该工具使用自然语言处理(NLP)扫描文件,识别姓名、地址和财务细节等实体,并自动进行编辑。这个过程将文件准备时间减少了90%以上,并显著降低了意外泄露敏感信息的风险。
在开发环境中保护客户数据
一家软件公司需要真实数据来测试新的电子商务功能。使用实时生产数据库的副本会带来重大的安全风险。为解决此问题,他们使用数据假名化工具。该工具创建数据库的副本,但将真实的客户姓名、电子邮件和电话号码替换为虚假但结构上有效的数据。这为开发团队提供了一个用于测试的高保真数据集,能准确反映真实世界场景,同时不会暴露任何实际的客户PII,并保持对数据保护法的遵守。
自动化用户同意管理
一家全球媒体公司运营着多个网站和应用程序,每个平台都为不同目的收集用户数据。手动跟踪所有平台上的用户同意偏好是无法管理的,并有违反CCPA等隐私法的风险。他们实施了一个由AI驱动的同意管理平台。该工具集中管理同意记录,根据用户位置和当地法律自动显示同意横幅,并确保数据处理系统自动尊重用户的选择(例如,选择退出)。这简化了合规流程,并通过透明的数据处理建立了用户信任。