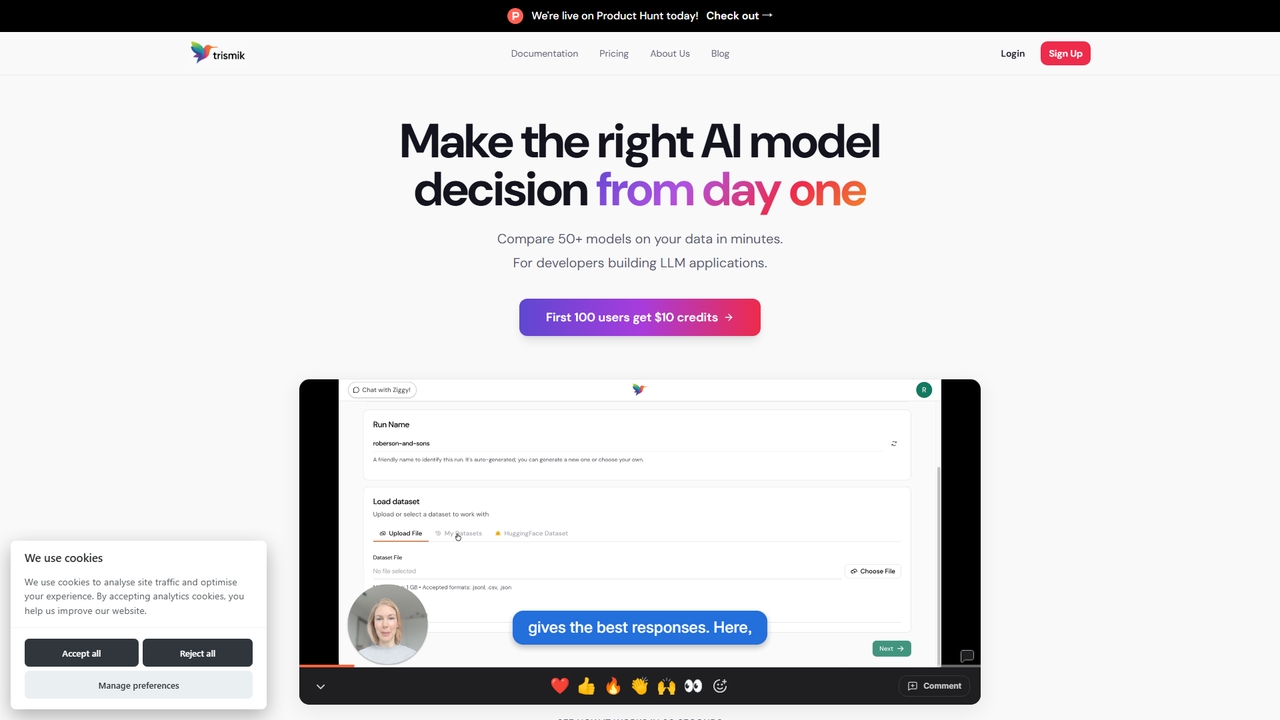
Trismik
幾分鐘內在您自己的資料上比較50多個LLM模型。基於證據做出關於品質、成本和速度的模型決策,無需猜測。
幾分鐘內在您自己的資料上比較50多個LLM模型。基於證據做出關於品質、成本和速度的模型決策,無需猜測。
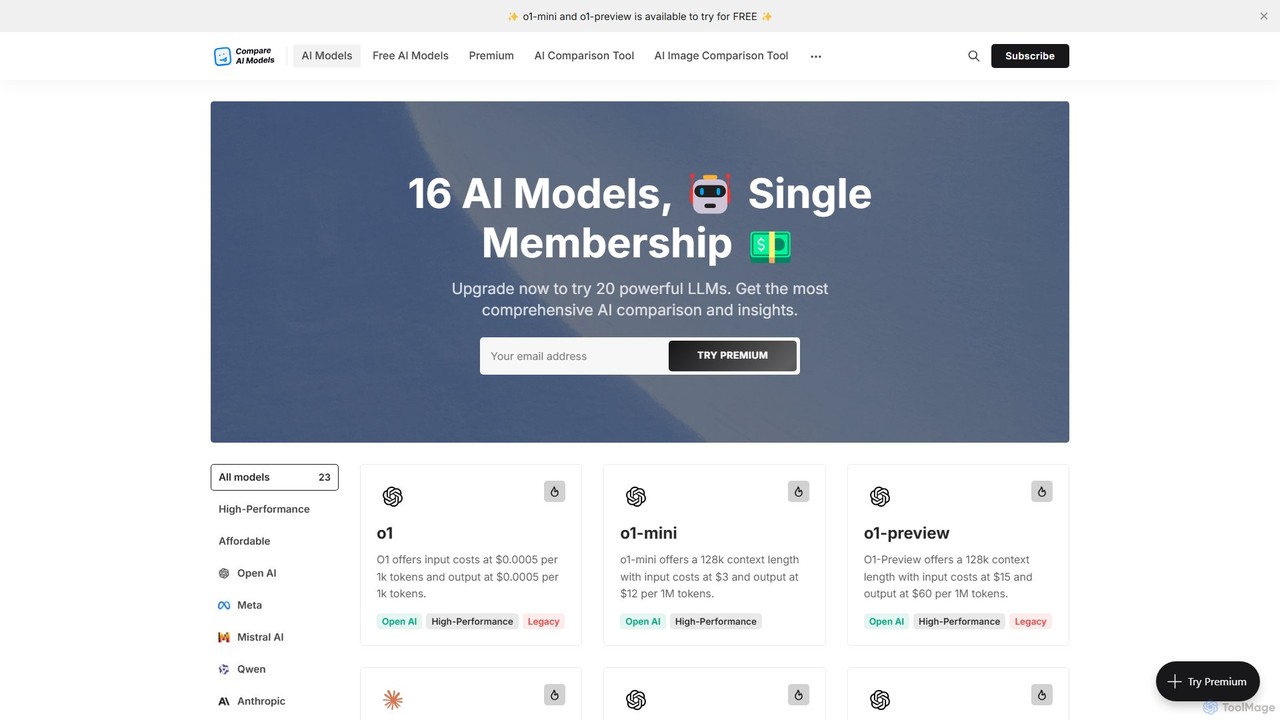
Compare AI Models
一個全面的平台,用於比較超過20種領先的大型語言模型(LLM)。它提供關於性能、API定價、上下文窗口和功能的詳細指標,並附帶免費聊天功能以直接測試模型。是開發人員、研究人員和企業尋找完美AI的必備工具。
一個全面的平台,用於比較超過20種領先的大型語言模型(LLM)。它提供關於性能、API定價、上下文窗口和功能的詳細指標,並附帶免費聊天功能以直接測試模型。是開發人員、研究人員和企業尋找完美AI的必備工具。
Joythee AI
Joythee AI 是一個先進的對話式AI平台,允許您同時與多個AI代理聊天。在單一介面中比較來自各種大型語言模型(LLM)的回覆,享受個人化對話,並透過無痕模式保護您的隱私。是個人、團隊和企業尋求提高生產力和創造力的理想選擇。
Joythee AI 是一個先進的對話式AI平台,允許您同時與多個AI代理聊天。在單一介面中比較來自各種大型語言模型(LLM)的回覆,享受個人化對話,並透過無痕模式保護您的隱私。是個人、團隊和企業尋求提高生產力和創造力的理想選擇。
關於 模型比較
模型比較工具是開發者工具包中的一類專業平台,旨在系統性地評估、基準測試和比較不同AI模型的性能。這些工具提供一個結構化環境,用於針對相同的輸入和資料集運行語言模型或圖像生成器等模型,從而客觀地衡量其輸出。它們對於制定數據驅動的決策至關重要,幫助開發者和研究人員為其特定應用選擇最準確、最具成本效益和最高效的模型。透過提供並排分析和量化指標,這些工具簡化了原本複雜耗時的模型選擇過程。
核心功能
- 並排測試環境:在統一介面中即時比較多個模型對同一提示詞的輸出。
- 自動化基準測試:運行標準行業基準(如MMLU, HumanEval)對模型的多項能力進行評分。
- 成本與延遲分析:追蹤並比較每個模型推理的財務成本和響應時間。
- 定性評估:支援人工回饋,針對連貫性、風格或安全性等主觀標準進行評分。
- 版本控制與歷史記錄:記錄並追蹤評估實驗,以監控性能變化和迴歸。
適用場景
這些工具對AI開發者、MLOps工程師和產品經理在開發和維護生命週期中至關重要。它們可用於為新功能選擇基礎模型、評估微調效果,或在模型更新後進行迴歸測試。例如,一個建構客服聊天機器人的團隊會使用這些工具來比較來自OpenAI、Anthropic和Google的模型的對話能力和成本,然後再決定使用哪一個。
選擇要點
選擇模型比較工具時,應考慮其支援模型的廣度,包括商業API和開源選項。評估其提供的基準測試套件以及創建自訂評估資料集的靈活性。考察其與現有MLOps工作流和CI/CD管道的整合能力。最後,還需考慮支援團隊成員審查結果的協作功能,以及能隨評估需求擴展的定價模式。
模型比較應用場景
為新的聊天機器人選擇最佳大型語言模型
一個產品團隊正在開發一款新的人工智慧客服聊天機器人。他們使用模型比較工具來評估GPT-4、Claude 3 Sonnet和Llama 3 70B。團隊創建了一個包含100個常見客戶查詢的「黃金資料集」,並用它來測試這三個模型。該平台提供了並排的響應視圖,以及關於實用性和語氣的自動化指標。它還計算了每個模型每1000次對話的平均成本。根據結果,他們選擇了Claude 3 Sonnet,因為它在對話品質和營運成本之間為他們的特定用例提供了最佳平衡。
評估微調模型的效能
一位機器學習工程師在公司內部文件上微調了一個開源的Mistral 7B模型,用於問答任務。為了證明部署的合理性,他們使用比較工具將微調後的模型與基礎Mistral 7B模型以及像GPT-4這樣的專有模型進行基準測試。他們上傳了一個包含50個技術問題的測試集。該工具衡量了事實準確性和相關性。結果顯示,他們微調後的模型在準確性上比基礎模型高出30%,並且成本比GPT-4便宜10倍,為繼續部署提供了明確的證據。
針對模型API更新的回歸測試
一個MLOps團隊管理著一個依賴外部模型API的摘要功能。API提供商宣布了一個新版本。在切換之前,該團隊使用一個模型比較平台,將他們的500個測試文件套件分別通過新舊API版本運行。該平台會自動標記出新版本生成的任何與舊版本輸出相比明顯更短、連貫性更差或事實不正確的摘要。這種自動化的回歸測試可以防止服務品質下降,並確保平穩過渡到更新後的模型。
為行銷目的比較圖像生成模型
一家行銷代理商需要選擇一個圖像生成模型來創作廣告素材。他們使用比較工具,用20個與客戶產品相關的不同提示詞來測試DALL-E 3、Midjourney和Stable Diffusion。該工具允許他們的創意團隊對每個生成的圖像在提示詞遵循度、美學品質和品牌契合度方面進行1-5分的評分。匯總的分數顯示,雖然Midjourney生成的圖像在美學上最令人愉悅,但DALL-E 3在準確地融入提示詞中提到的特定產品細節方面更勝一籌,因此成為滿足他們需求的更好選擇。
優化摘要API的成本效益
一家新聞聚合服務使用大型語言模型來摘要文章。為了降低成本,他們希望找到在保持品質的同時最便宜的模型。透過使用比較工具,他們測試了五種不同的模型,從高階的GPT-4到更小的開源替代品。他們讓每個模型處理1000篇文章,並使用自動化的ROUGE分數來衡量摘要品質,同時該工具追蹤每個模型的成本。他們發現,一個量化版的Llama 3 8B模型能提供GPT-4 95%的品質,而成本僅為其10%,從而實現了可觀的月度節省。
跨多個模型進行提示詞的A/B測試
一位提示詞工程師的任務是為程式碼生成功能創建最有效的提示詞。他們沒有逐一測試提示詞,而是使用模型比較工具來設置一個矩陣實驗。他們輸入三種不同的提示詞變體,並在四種模型(例如GPT-4、Claude 3 Opus、Gemini Pro和一個專門的程式碼模型)上進行測試。該平台運行所有12種組合,並以熱圖形式呈現結果,顯示哪個提示詞-模型對能生成最準確、最高效的程式碼。這將提示詞優化過程的速度提高了十倍。