
KubeHA
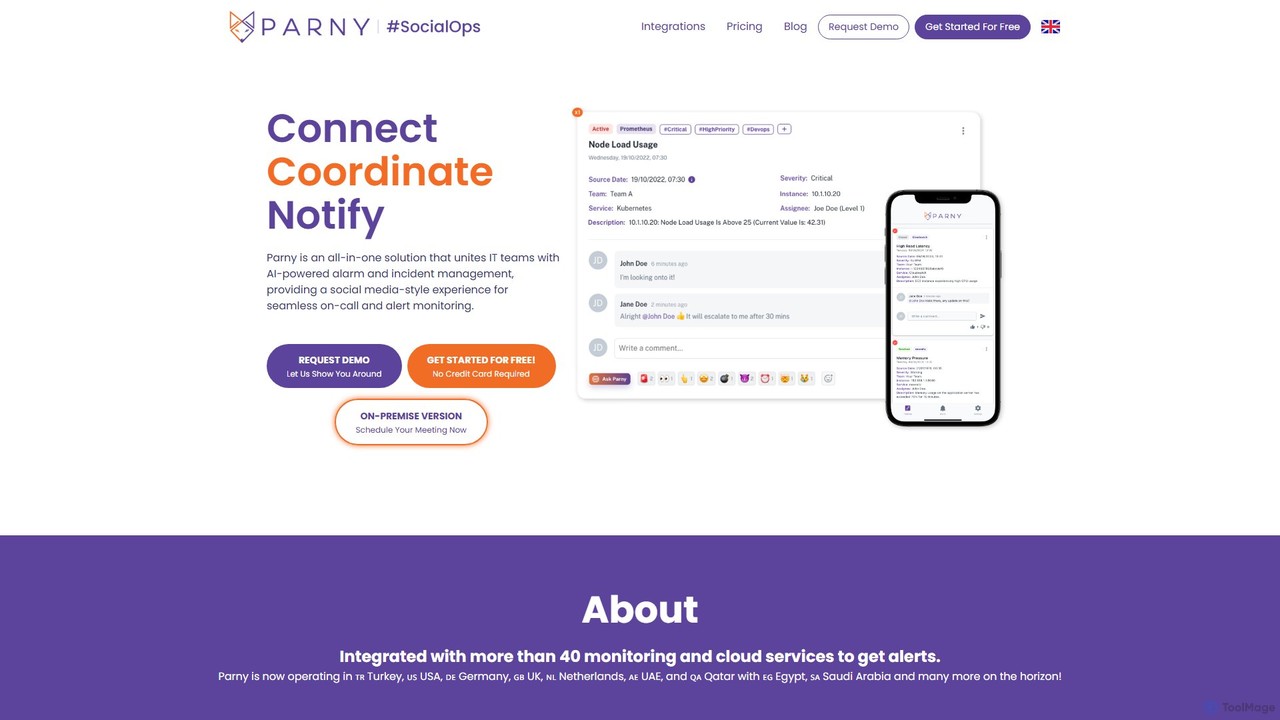
KubeHA 是一個由生成式AI驅動的SaaS平台,專為Kubernetes設計,提供監控、可觀測性、修復和探索(MORE)的一體化解決方案。它統一了日誌、指標、追蹤和事件,提供AI驅動的根本原因分析、智能修復建議和一鍵式修復,消除了工具泛濫問題,為SRE和DevOps團隊簡化了複雜的操作。
KubeHA 是一個由生成式AI驅動的SaaS平台,專為Kubernetes設計,提供監控、可觀測性、修復和探索(MORE)的一體化解決方案。它統一了日誌、指標、追蹤和事件,提供AI驅動的根本原因分析、智能修復建議和一鍵式修復,消除了工具泛濫問題,為SRE和DevOps團隊簡化了複雜的操作。
smallhours
smallhours 是一個為開發者打造的AI平台,可實現全天候自動化根本原因分析(RCA)。它透過OpenTelemetry與您的技術堆疊整合,監控系統,利用您的程式碼庫和執行手冊作為上下文診斷問題,將解決時間加快10倍,從而最大限度地減少停機時間並簡化值班職責。
smallhours 是一個為開發者打造的AI平台,可實現全天候自動化根本原因分析(RCA)。它透過OpenTelemetry與您的技術堆疊整合,監控系統,利用您的程式碼庫和執行手冊作為上下文診斷問題,將解決時間加快10倍,從而最大限度地減少停機時間並簡化值班職責。
Botkube
Botkube 是一款開源的協作式 Kubernetes AI 助理。它直接整合到您的 Slack 和 Microsoft Teams 等聊天平台中,集中進行即時監控、警報和故障排除。它透過將 K8s 管理引入您的日常通訊工具,賦能開發人員獨立管理其應用程式,並簡化 DevOps 工作流程。
Botkube 是一款開源的協作式 Kubernetes AI 助理。它直接整合到您的 Slack 和 Microsoft Teams 等聊天平台中,集中進行即時監控、警報和故障排除。它透過將 K8s 管理引入您的日常通訊工具,賦能開發人員獨立管理其應用程式,並簡化 DevOps 工作流程。

Releem
Releem 是一款由 AI 驅動的 MySQL 效能調校工具,旨在實現資料庫管理的自動化。它能自動偵測效能瓶頸,提供最佳化的伺服器設定,並為 SQL 查詢和索引提出改進建議。Releem 是開發人員、資料庫管理員和主機代管服務供應商的理想選擇,透過使用者友善的儀表板和持續的健康監控,簡化複雜的資料庫任務,提升應用程式速度,並降低基礎設施成本。
Releem 是一款由 AI 驅動的 MySQL 效能調校工具,旨在實現資料庫管理的自動化。它能自動偵測效能瓶頸,提供最佳化的伺服器設定,並為 SQL 查詢和索引提出改進建議。Releem 是開發人員、資料庫管理員和主機代管服務供應商的理想選擇,透過使用者友善的儀表板和持續的健康監控,簡化複雜的資料庫任務,提升應用程式速度,並降低基礎設施成本。
關於 監控
AI監控工具是一類使用機器學習來自動觀測和分析IT系統健康狀況與效能的軟體。它超越了傳統的基於閾值的警報,透過學習正常的運行模式來智慧偵測異常、預測潛在故障並識別根本原因。這使得IT維運團隊能夠在問題影響使用者之前主動解決,從而顯著減少停機時間並提高系統可靠性。這類工具是現代智慧維運(AIOps)策略的核心組成部分。
核心功能
- 智慧異常偵測:無需預先定義規則,自動識別系統行為與正常基線的偏差。
- 預測性分析:基於歷史數據預測未來的效能問題或資源短缺。
- 自動化根因分析(RCA):關聯來自不同資料來源的事件,精確定位問題的源頭。
- 動態閾值:根據系統負載和模式的變化自動調整警報閾值。
- 警報降噪:將相關警報分組並過濾掉無關通知,使團隊能專注於關鍵事件。
適用場景
AI監控工具主要由技術驅動產業的IT維運、DevOps和網站可靠性工程(SRE)團隊使用。例如,電商平台利用它預測流量高峰,以防止在促銷活動期間伺服器過載。軟體公司則可以利用這些工具在新版本發布前識別應用程式碼中的效能瓶頸,確保流暢的使用者體驗。
選擇要點
選擇AI監控工具時,需考慮其與現有技術堆疊(如雲端服務供應商、資料庫、CI/CD管道)的整合能力。評估其機器學習模型在異常偵測和根因分析方面的成熟度。此外,還應考察其儀表板的清晰度、警報系統的靈活性以及定價模式(可能基於主機、資料量或使用者數)。
監控應用場景
主動預防電商平台服務中斷
一家線上零售公司的SRE團隊使用AI監控工具來確保大型促銷活動期間的高可用性。該工具分析即時交易數據、伺服器指標和使用者行為。它偵測到支付閘道中一個傳統監控工具會忽略的、細微且不尋常的延遲模式。透過將此模式與資料庫查詢時間的輕微增加相關聯,AI預測資料庫可能在一小時內過載。它自動向團隊發出警報並指出具體根本原因,使他們能夠主動擴展資料庫資源,從而防止了一場可能造成數百萬收入損失的全站服務中斷。
自動化應用程式效能偵錯
一家SaaS公司的DevOps工程師將新的程式碼更新推送到生產環境。不久之後,AI監控工具偵測到API錯誤率飆升,以及某個特定微服務的記憶體消耗逐漸增加。它沒有產生數百個獨立的警報,而是將日誌、追蹤和指標關聯起來,精確定位到新程式碼中導致記憶體洩漏的具體函式。工程師收到的是一份內容豐富的單一事件報告,這將平均解決時間(MTTR)從數小時的手動日誌篩選縮短到僅幾分鐘的定向偵錯。
透過異常偵測優化雲端成本
一個雲端基礎設施團隊管理著一個龐大的多雲環境。AI監控工具持續分析資源利用模式。它識別出一組為臨時專案配置但從未取消配置的虛擬機,這些虛擬機目前處於閒置狀態並產生費用。它還標記了一個由於配置錯誤的擴展策略而持續過度配置資源的自動擴展群組。透過標記這些成本異常,該工具幫助團隊在不影響服務效能的情況下,將每月雲端帳單節省超過20%。
早期安全威脅偵測
一個安全營運(SecOps)團隊將AI監控工具與其安全資訊和事件管理(SIEM)系統整合。該工具建立了正常網路流量和使用者活動的行為基線。然後,它標記了一次「低慢」資料竊取企圖——一個被盜用的帳戶在很長一段時間內匯出少量資料以逃避偵測。AI識別出這種傳統基於規則的安全警報無法發現的異常行為,並觸發一個高優先級事件,使SecOps團隊能夠在發生重大資料遺失之前控制住這次洩漏。
物聯網設備的預測性維護
一家製造公司在其工廠車間部署了數千個物聯網感測器。一個AI監控平台接收來自這些感測器的遙測數據,如溫度、振動和壓力。透過分析歷史數據,AI模型學習特定機器部件的故障模式。它預測一個關鍵馬達由於異常的振動特徵,在未來72小時內發生故障的可能性為85%。這個預測性警報使維護團隊能夠在非工作時間安排更換,從而避免了代價高昂的意外停機和生產損失。
結合業務背景改善數位體驗
一家金融服務公司使用AI監控工具來追蹤其線上銀行平台的效能。該工具被配置為理解業務KPI,例如「成功貸款申請數」或「已完成的資金轉帳」。當它偵測到貸款申請完成率下降時,它會自動將此業務指標與底層的IT效能數據相關聯。它發現下降與身份驗證服務中一個運行緩慢的特定API呼叫有關。這使得IT團隊能夠根據直接的業務影響,而不僅僅是技術嚴重性,來優先處理修復工作。