
Cleora 概覽
Cleora 是由 Synerise.com 團隊開發的一款通用開源模型,專為從複雜的異構關聯性資料中進行高效、可擴展的實體嵌入學習而設計。它擅長將實體及其互動——例如購物車中的商品、社交網路上的使用者或生物系統中的蛋白質——轉換為有意義的數值向量。這些向量(即嵌入)捕捉了潛在的關係和相似性,使其在下游的機器學習任務中具有極高的價值。
Cleora 的核心採用高效能的 Rust 語言建構,並透過使用者友善的 Python 套件 (pycleora) 提供介面,其處理速度比 DeepWalk 或 PyTorch-BigGraph 等傳統方法快上數個數量級。它基於從資料中導出的馬可夫轉移矩陣進行迭代隨機投影的原理運作,這種方法避免了負取樣帶來的雜訊和效率低落的問題。這使得它能夠在單台機器上處理超大規模的圖和超圖,這對於現實世界的應用是一個顯著的優勢。
如何使用 Cleora
對於熟悉 Python 的開發人員和資料科學家來說,使用 Cleora 非常簡單。該過程通常包括以下步驟:
- 安裝:直接使用 pip 安裝 Python 套件:
pip install pycleora。 - 資料準備:將您的資料建構為一系列超邊。超邊是一組共同出現的實體。例如,輸入檔案中的一行可以代表單次交易中購買的所有商品,用空格分隔。這可以從 pandas DataFrame 或任何 Python 迭代器中準備。
- 矩陣創建:使用
SparseMatrix.from_iterator()函數將您準備好的資料轉換為稀疏的馬可夫轉移矩陣。該矩陣代表了您的超圖內的關係。 - 嵌入初始化:您可以讓 Cleora 確定性地初始化嵌入向量,也可以提供您自己的初始向量。這一獨特功能允許您將外部資訊(例如來自文字的嵌入,如 Sentence-BERT,或影像的嵌入,如 ViT)融入圖結構中。
- 傳播:使用
mat.left_markov_propagate(embeddings)執行幾次馬可夫傳播迭代。通常,3 到 7 次迭代就足夠了。較少的迭代捕捉直接的共現關係,而更多的迭代則捕捉更深層次的上下文相似性。 - 標準化:對生成的嵌入向量進行標準化,通常使用 L2 範數,以確保它們位於一個超球面上。這使得它們可以使用餘弦相似度或點積進行比較。
- 使用:最終標準化的向量就是您的實體嵌入,可用於推薦、分類、分群或相似性搜尋任務。
Cleora 的核心功能
- 極致效能:採用 Rust 編寫,並針對並行和快取一致性進行了最佳化,使其速度極快。
- 可擴展性:能夠在單台普通機器上嵌入擁有數十億條邊的超大規模圖和超圖。
- 歸納式學習:能夠即時為新的、前所未見的實體生成嵌入,而無需重新訓練整個模型,有效解決了冷啟動問題。
- 穩定與確定性:與 Node2vec 等方法不同,Cleora 對相同的輸入資料在多次運行中產生相同的嵌入,確保了可重現性和穩定性。
- 超圖支援:原生處理超圖(例如,購物籃中的商品,群組中的使用者),這比簡單的成對圖分解功能更強大。
- Python 整合:提供無縫的 Python API (pycleora),並與 NumPy 深度整合,便於在資料科學工作流程中使用。
- 自訂初始化:允許使用者使用來自其他來源(如文字、影像模型)的向量來初始化嵌入,從而實現多模態分析。
Cleora 的使用案例
Cleora 的多功能性使其適用於各行各業的廣泛應用:
- 電子商務:為推薦系統(例如,「購買此商品的顧客還購買了...」)、商品相似性和購物籃分析創建強大的商品嵌入。
- 社交網路分析:嵌入使用者和內容以識別社群、預測連結和推薦內容。
- 生物資訊學:透過基於在生物通路中共現的蛋白質、藥物和基因進行嵌入來分析它們之間的相互作用。
- 金融服務:透過識別交易圖中的異常模式來偵測詐欺活動。
- 學術研究:分析合著網路以發現研究社群和有影響力的作者。
Cleora 的優勢特點
Cleora 因其幾個關鍵優勢而在其他嵌入框架中脫穎而出:
- 無與倫比的速度:它比許多流行的替代方案(例如,在基準測試中比 DeepWalk 快 190 倍以上)要快得多。
- 生產就緒:其穩定性、歸納能力和即時更新能力使其非常適合部署在即時生產環境中。
- 高品質嵌入:在完整的轉移矩陣上進行顯式隨機遊走且無需負取樣的方法,可以產生更高品質和更準確的嵌入。
- 資源效率:它被設計為在單台機器上高效運行,減少了對昂貴的分散式計算叢集的需求。
- 簡單與靈活:該模型在概念上簡單而強大,在資料輸入和嵌入初始化方面提供了靈活性。
定價和計劃
Cleora 是一個在 MIT 授權下發布的完全開源的專案。這意味著它對於學術和商業用途都是完全免費的。沒有付費方案或隱藏費用。原始碼在 GitHub 上公開提供,任何人都可以使用、檢查或貢獻。
Cleora 評論 (0)
登入後即可發表評論
立即登入Cleora 替代方案
查看全部
Streamlit
Streamlit 是一個開源 Python 框架,使開發人員和資料科學家能夠在幾分鐘內為機器學習和資料科學建構和共享精美的自訂 Web 應用程式。Streamlit Community Cloud 提供一個免費平台,用於部署、管理和與世界分享這些公共應用程式,營造一個協作創新的環境。
Streamlit 是一個開源 Python 框架,使開發人員和資料科學家能夠在幾分鐘內為機器學習和資料科學建構和共享精美的自訂 Web 應用程式。Streamlit Community Cloud 提供一個免費平台,用於部署、管理和與世界分享這些公共應用程式,營造一個協作創新的環境。
marimo
marimo 是一款面向現代資料科學和人工智慧的開源響應式 Python 筆記本。它提供了一個可重現、Git 友好且互動式的環境,其中筆記本即是純 Python 腳本。其功能包括內建的 AI 輔助、SQL 儲存格以及將筆記本作為 Web 應用程式共享的能力,從而簡化了從實驗到生產的工作流程。
marimo 是一款面向現代資料科學和人工智慧的開源響應式 Python 筆記本。它提供了一個可重現、Git 友好且互動式的環境,其中筆記本即是純 Python 腳本。其功能包括內建的 AI 輔助、SQL 儲存格以及將筆記本作為 Web 應用程式共享的能力,從而簡化了從實驗到生產的工作流程。
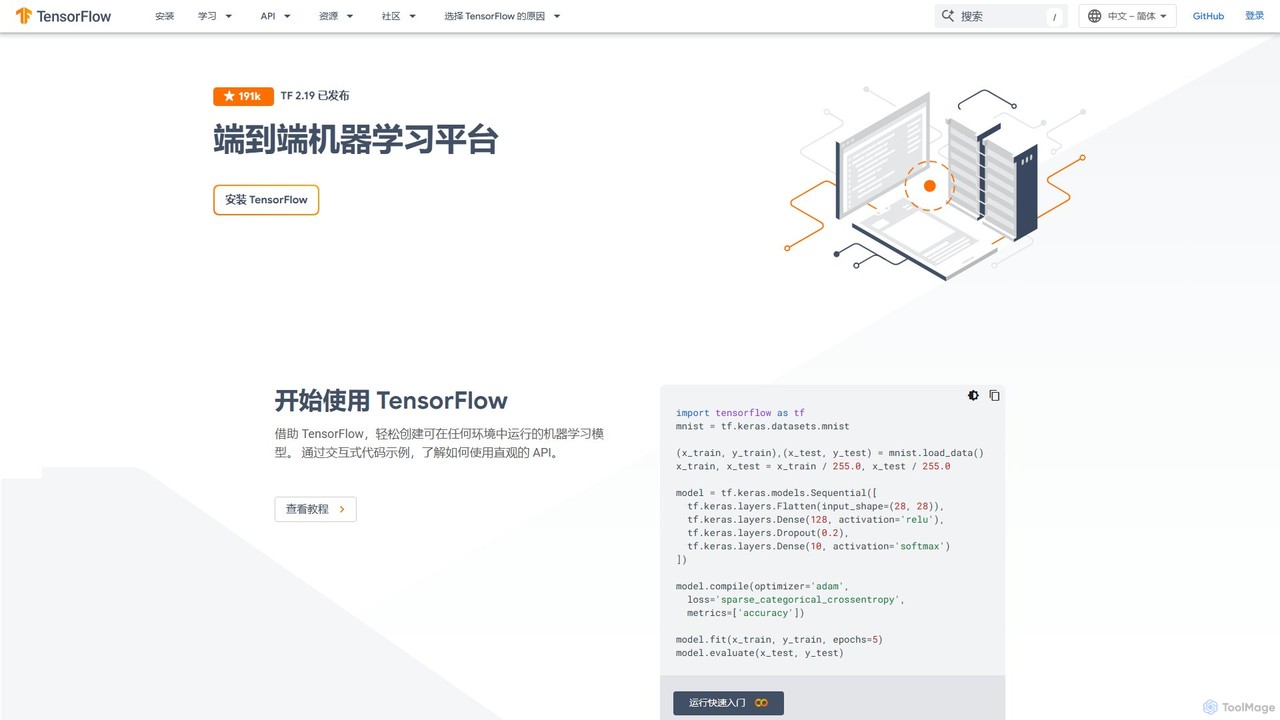
TensorFlow
TensorFlow 是由谷歌開發的端對端開源機器學習平台。它提供了一個全面、靈活的工具、函式庫和社群資源生態系統,讓研究人員和開發人員能夠建構和部署由機器學習驅動的應用程式。從初學者到專家,TensorFlow 提供了用於輕鬆建構模型的直觀高階 API 和用於進階研究的強大低階 API,支援在伺服器、邊緣裝置和瀏覽器上進行部署。
TensorFlow 是由谷歌開發的端對端開源機器學習平台。它提供了一個全面、靈活的工具、函式庫和社群資源生態系統,讓研究人員和開發人員能夠建構和部署由機器學習驅動的應用程式。從初學者到專家,TensorFlow 提供了用於輕鬆建構模型的直觀高階 API 和用於進階研究的強大低階 API,支援在伺服器、邊緣裝置和瀏覽器上進行部署。
Cleora AI工具
Cleora 嵌入功能
只需複製下方嵌入代碼,將精美徽章貼到您的博客、文章或應用官網,即可把流量直接引導到本工具詳情頁,快速提升曝光與用戶量!

還沒有評論,成為第一個評論者吧!