
Diffbot 概覽
Diffbot 提供一套由人工智能驅動的工具,旨在理解和結構化公共網路的內容,有效地將其轉變為世界上最大、最全面的資料庫。其核心是 Diffbot 知識圖譜,一個龐大的、相互關聯的資料儲存庫,包含有關組織、人物、文章、產品等資訊。與需要為每個網站手動設定規則的傳統網路爬蟲不同,Diffbot 使用電腦視覺和自然語言處理技術,像人類一樣自動解讀網頁,無需針對特定網站進行配置即可提取結構化資料。
這項技術使開發人員和企業能夠擺脫網路資料的嘈雜和混亂,而是像存取一個乾淨、結構化的資料庫一樣存取它。無論您需要監控新聞、豐富客戶資料、進行市場研究,還是為機器學習模型提供動力,Diffbot 都能提供構建智能應用所需的乾淨、可靠的資料源。
如何使用 Diffbot
對於開發人員和資料團隊來說,開始使用 Diffbot 的過程非常簡單。主要透過其強大的 API 進行互動。
- 註冊帳戶:首先創建一個帳戶。Diffbot 提供一個免費計劃,包含 10,000 個積分和完整的 API 存取權限,讓您無需信用卡即可測試平台的功能。
- 取得您的 API 權杖:註冊後,您將從儀表板收到一個 API 權杖。此權杖用於驗證您對 Diffbot API 的所有請求。
- 選擇合適的 API:Diffbot 為不同的任務提供了幾種不同的 API:
- Extract API:將其指向任何 URL(如文章、產品頁面或論壇討論),它將自動返回結構化的 JSON 資料。無需任何規則。
- Crawl API:提供一個起始 URL,Diffbot 將系統地爬取整個網站,使用 Extract API 將每個相關頁面轉換為結構化資料。這非常適合從特定網站構建資料庫。
- Knowledge Graph Search API:查詢預先構建的知識圖譜,以查找超過 2.46 億個組織、16 億篇文章等資訊。您可以搜尋實體並構建精確的資料源。
- Knowledge Graph Enhance API:提供您自己的資料(例如,公司名稱),Diffbot 將使用知識圖譜中的全面資料對其進行豐富,例如收入、員工數量、社交資料和最新新聞。
- Natural Language API:提交原始文本以推斷實體、它們之間的關係,並進行情感分析。
- 整合與建構:使用 API 回應(JSON 格式)來驅動您的應用程式、填充您的資料庫或為您的分析儀表板提供資料。對於即時需求,您可以設定 webhook 以獲得即時通知,例如提及特定公司的新文章。
Diffbot 的核心功能
- 知識圖譜:一個龐大的、預先爬取並持續更新的網路圖譜,包含關於組織、人物、產品、文章及其關係的結構化資訊。
- 自動提取:由人工智能驅動的技術,可自動識別並從各種頁面類型(文章、產品、討論等)中提取關鍵資訊,無需手動設定或規則。
- Crawlbot:一個智能網路爬蟲,可以將整個網站轉變為結構化資料庫,自動識別並從相關頁面提取內容。
- 自然語言處理 (NLP):先進的 NLP 功能,可理解超過 20 種語言的文本,執行實體識別(區分「蘋果」公司和「蘋果」水果),並進行主題級的情感分析。
- 資料豐富 (Enhance API):能夠獲取最少量的資訊(如公司名稱或電子郵件),並用知識圖譜中的數十個資料點對其進行豐富。
- 即時監控:透過精確的實體匹配和情感分析,為新聞和品牌提及構建客製化的、無噪音的源,並提供即時的電子郵件或 webhook 警報。
Diffbot 的使用案例
Diffbot 的結構化資料在眾多行業和職能中都極具價值:
- 市場情報:透過利用全球新聞、公司文件和產品資料,追蹤競爭對手、監控行業趨勢並分析市場動向。
- 風險與合規:對公司和個人進行盡職調查,監控供應鏈中的風險信號,並領先於監管變化。
- 銷售與行銷:豐富 CRM 中的潛在客戶資料,根據特定標準(例如,某個行業中剛剛獲得融資的公司)識別新客戶,並進行個人化推廣。
- 新聞與媒體監控:創建高度具體、即時的新聞源,透過精確的實體匹配和情感分析追蹤品牌、人物或主題的提及。
- 招聘:建立潛在候選人資料庫,識別人材,並用來自網路各處的資料豐富專業檔案。
- 機器學習:將知識圖譜用作高品質、結構化的訓練資料源,用於各種人工智能和機器學習模型。
Diffbot 的優勢特點
Diffbot 的主要優勢在於其能夠將整個網路視為一個可查詢的單一資料庫。它抽象化了網路爬取和資料清洗的複雜性。主要好處包括準確性、規模和效率。用戶無需構建和維護脆弱的、針對特定網站的爬蟲,而是可以依賴一個單一、強大的 API。實體感知的 NLP 確保了資料的品質和相關性,而預構建的知識圖譜則提供了對龐大資料集的即時存取,而這些資料集內部構建需要數年時間。
定價和計劃
Diffbot 提供分層定價結構,以適應從個人專案到大型企業的不同使用水平。
- 免費計劃:每月 0 美元。包括 10,000 個積分,完全的 API 存取權限,並且永久免費。非常適合測試和小型專案。
- 新創計劃:每月 299 美元。包括 250,000 個積分,專為需要即插即用式抓取和知識圖譜存取的小型團隊設計。
- 增強計劃:每月 899 美元。包括 1,000,000 個積分,可存取 Crawl 產品,並提供更高的 API 呼叫率。適合資料需求更大的成長型企業。
- 企業計劃:自訂定價。為大規模資料操作提供客製化計劃,包括自訂積分分配、最高的 API 呼叫率、高級 SLA 支援和託管解決方案。
積分的消耗取決於 API 呼叫的類型和複雜性。其網站上提供了詳細的分類說明。
Diffbot 評論 (0)
登入後即可發表評論
立即登入Diffbot網站流量分析
最新流量情況
狀態
月度流量趨勢
地理位置
Top 5 國家/地區
-
🇺🇸 United States36.36%
-
🇮🇳 India28.03%
-
🇳🇬 Nigeria14.97%
-
🇨🇦 Canada10.37%
-
🇩🇪 Germany10.27%
流量來源
| 來源類型 | 百分比 |
|---|---|
|
直接訪問
|
93.32% |
|
外鏈引薦
|
6.03% |
|
郵件
|
0.65% |
熱門關鍵詞
| 關鍵詞 | 每次點擊費用 |
|---|---|
|
$0.00
|
|
|
$4.94
|
|
|
$0.00
|
|
|
$0.00
|
|
|
$0.00
|
Diffbot 替代方案
查看全部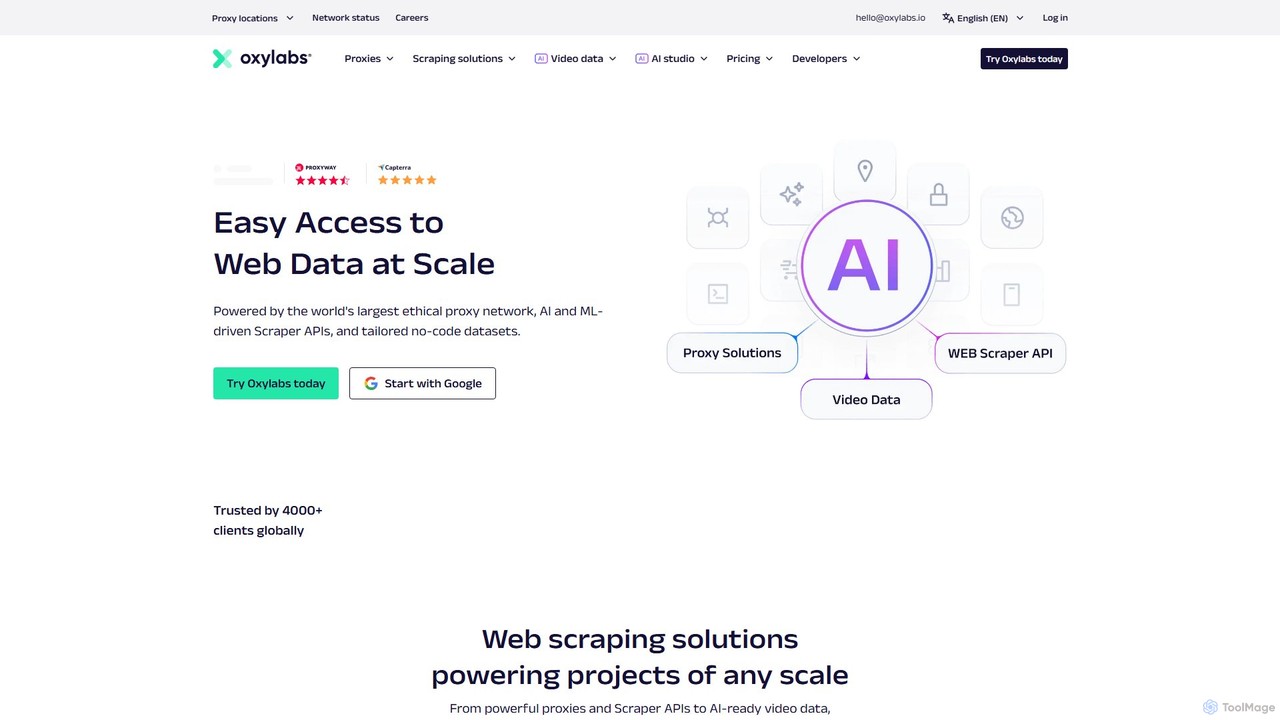
Oxylabs
Oxylabs 是一家領先的高級代理服務和企業級網路資料擷取解決方案供應商。它利用一個擁有超過1.77億個IP的、符合道德規範的大規模代理網路,提供由AI驅動的爬蟲API、網站解鎖器以及用於自然語言資料擷取的全新AI Studio。它使企業能夠大規模收集用於電子商務、網路安全、品牌保護和市場研究的公開網路資料,而不會被阻止。
Oxylabs 是一家領先的高級代理服務和企業級網路資料擷取解決方案供應商。它利用一個擁有超過1.77億個IP的、符合道德規範的大規模代理網路,提供由AI驅動的爬蟲API、網站解鎖器以及用於自然語言資料擷取的全新AI Studio。它使企業能夠大規模收集用於電子商務、網路安全、品牌保護和市場研究的公開網路資料,而不會被阻止。
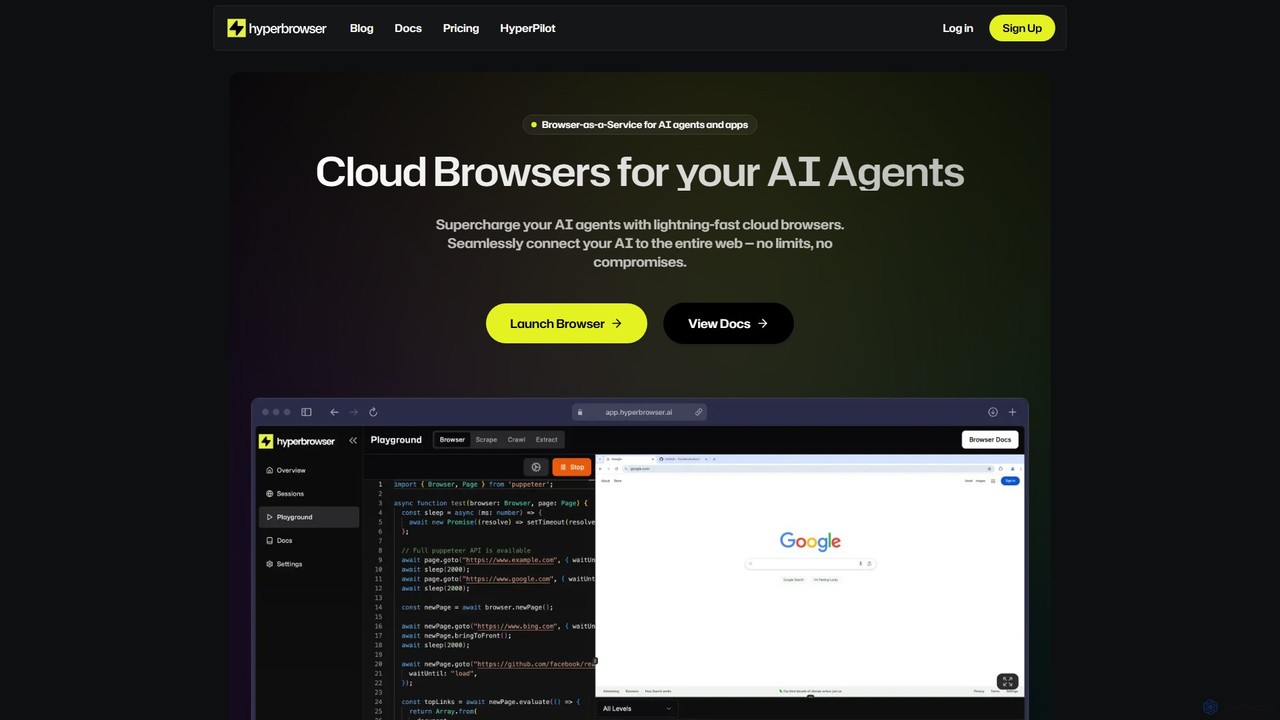
Hyperbrowser
Hyperbrowser 是一個專為 AI 代理和開發者設計的瀏覽器即服務(BaaS)平台。它提供可擴展、速度極快的雲端瀏覽器,用於自動化網頁任務、提取數據以及實現由 AI 驅動的網頁互動。憑藉隱身瀏覽、自動驗證碼破解和對開發者友好的 API 等功能,它為複雜的工作流程提供了無限可能。
Hyperbrowser 是一個專為 AI 代理和開發者設計的瀏覽器即服務(BaaS)平台。它提供可擴展、速度極快的雲端瀏覽器,用於自動化網頁任務、提取數據以及實現由 AI 驅動的網頁互動。憑藉隱身瀏覽、自動驗證碼破解和對開發者友好的 API 等功能,它為複雜的工作流程提供了無限可能。
Simplescraper
Simplescraper 是一款功能強大的網頁抓取工具,可在數秒內從任何網站擷取資料。它提供了一個使用者友善的 Chrome 擴充功能,用於無程式碼資料選取;基於雲端的自動化功能,用於大規模抓取;以及創新的 AI 增強功能,可透過簡單提示獲取洞察。將網站轉化為結構化資料(CSV、JSON)或即時 API,並與 Google Sheets 和 Airtable 等工具整合。
Simplescraper 是一款功能強大的網頁抓取工具,可在數秒內從任何網站擷取資料。它提供了一個使用者友善的 Chrome 擴充功能,用於無程式碼資料選取;基於雲端的自動化功能,用於大規模抓取;以及創新的 AI 增強功能,可透過簡單提示獲取洞察。將網站轉化為結構化資料(CSV、JSON)或即時 API,並與 Google Sheets 和 Airtable 等工具整合。
Nimbleway
Nimbleway 是一個企業級平台,專注於AI驅動的網路資料收集和可擴展的資料管道。它使企業能夠與即時網路資料互動,提供代理式網路搜尋、線上知識雲和強大的SDK等工具。該平台是零售、金融和AI領域的理想選擇,為競爭分析、價格監控和LLM模型訓練提供超精細的結構化資料,同時確保資料採集的合乎道德和法規。
Nimbleway 是一個企業級平台,專注於AI驅動的網路資料收集和可擴展的資料管道。它使企業能夠與即時網路資料互動,提供代理式網路搜尋、線上知識雲和強大的SDK等工具。該平台是零售、金融和AI領域的理想選擇,為競爭分析、價格監控和LLM模型訓練提供超精細的結構化資料,同時確保資料採集的合乎道德和法規。
webscrapeai
WebscrapeAI 是一個無需編碼、由人工智能驅動的平台,旨在自動化網路數據收集。只需提供一個URL並指定您需要的數據,人工智能即可處理整個擷取過程。它支援動態網站、批量擷取、代理整合,並為開發人員提供API,使數據提取變得快速、準確且人人可用。
WebscrapeAI 是一個無需編碼、由人工智能驅動的平台,旨在自動化網路數據收集。只需提供一個URL並指定您需要的數據,人工智能即可處理整個擷取過程。它支援動態網站、批量擷取、代理整合,並為開發人員提供API,使數據提取變得快速、準確且人人可用。
Diffbot AI工具
Diffbot 嵌入功能
只需複製下方嵌入代碼,將精美徽章貼到您的博客、文章或應用官網,即可把流量直接引導到本工具詳情頁,快速提升曝光與用戶量!

還沒有評論,成為第一個評論者吧!