
Webcrawlerapi 概覽
Webcrawlerapi 是一個專門的API,旨在為開發人員簡化網路爬蟲和資料提取的過程。在資料對於訓練大型語言模型(LLM)和驅動AI應用至關重要的時代,傳統的網路抓取面臨著重大挑戰。這些挑戰包括處理動態JavaScript渲染的內容、繞過複雜的反機器人系統、管理代理以及將混亂的HTML清理成可用的格式。Webcrawlerapi 將所有這些複雜性抽象出來,提供了一個簡單而強大的介面,可將任何網站轉變為結構化的資料來源。
據報導,該服務擁有98%的成功率和僅6秒的平均抓取時間,專為效率和可靠性而構建。它使開發人員能夠專注於其核心應用邏輯,而不是陷入構建和維護可擴展抓取基礎設施的複雜細節中。透過提供一個連結,開發人員可以接收到乾淨、即用型的內容,格式包括Markdown、文本或原始HTML,非常適合輸入到AI模型訓練管道或RAG系統的知識庫中。
如何使用Webcrawlerapi
將 Webcrawlerapi 整合到您的專案中非常直接。該過程通常只需要幾行程式碼。首先,您需要在 Webcrawlerapi 網站上註冊以獲取您唯一的API存取金鑰。然後,您可以使用他們為流行程式語言提供的客戶端庫之一。
例如,在NodeJS環境中,您首先透過npm安裝客戶端庫:npm i webcrawlerapi-js。然後,在您的程式碼中,匯入該庫,使用您的API金鑰建立一個新的客戶端實例,並呼叫 `crawl` 方法。此方法接受諸如目標 `url`、所需的 `scrape_type`(例如 'markdown')以及可選的限制(如 `items_limit`)等參數。然後,API會在後台處理整個抓取過程,並返回一個包含提取資料的結構化JSON響應。Python、PHP和.NET也提供類似的簡單整合模式,使其對廣大開發人員都易於使用。
Webcrawlerapi的核心功能
- 自動連結處理: API智能地發現和管理網站上的所有內部連結,確保全面抓取,同時自動處理重複項和清理URL。
- 進階JavaScript渲染: 它使用穩定而強大的系統有效渲染動態的客戶端內容,克服了與Puppeteer或Playwright等工具相關的不穩定性和記憶體問題。
- 強大的反機器人規避: Webcrawlerapi 內建了處理驗證碼(CAPTCHA)、IP封鎖、速率限制和其他常見反機器人防禦的機制,確保了高成功率。
- 自動資料清理: 它包含強大的解析規則,可將原始、複雜的HTML轉換為乾淨、結構化的格式,如Markdown或純文字,為開發人員節省了大量的後處理時間。
- 可擴展的基礎設施: 該服務管理著一個分散式的爬蟲和代理基礎設施,使您能夠將資料提取工作從幾頁擴展到數百萬頁,而無需擔心底層硬體或網路管理。
- 開發者友善的API和SDK: 提供簡單的API和針對主流語言(如NodeJS、Python、PHP和.NET)的官方客戶端庫,並附有清晰的文檔。
Webcrawlerapi的使用案例
Webcrawlerapi 功能多樣,可應用於各種資料密集型任務。其主要用例圍繞AI和資料分析。
- LLM訓練資料收集: 系統地抓取網站、部落格和論壇,為訓練或微調自定義大型語言模型收集大量高品質、特定領域的文本資料。
- 檢索增強生成(RAG): 為RAG系統構建和維護最新的知識庫。抓取產品文檔、幫助中心或新聞網站,為LLM提供準確、即時的資訊以回答用戶查詢。
- 市場研究與競爭分析: 自動從競爭對手網站提取產品詳情、定價資訊、客戶評論和行銷內容,以獲得戰略洞察。
- 內容聚合: 透過定期抓取多個來源並將資料整合到一個統一的平台中,為新聞聚合器、招聘網站或房地產列表網站提供支援。
Webcrawlerapi的優勢特點
Webcrawlerapi 的主要優勢在於其簡單性和效率。它允許開發團隊將整個網路抓取基礎設施和維護負擔外包出去。這意味著資料驅動產品的上市時間更快。98%的高成功率和強大的反機器人功能確保了資料管道的可靠性。此外,其透明的按量付費定價模式具有很高的成本效益,因為您只需為成功的請求付費,從而消除了與訂閱或構建內部解決方案相關的風險和開銷。
定價和計劃
Webcrawlerapi 採用直接透明的「按使用量付費」定價模式,完全避免了訂閱和隱藏費用。成本根據您每月成功抓取的頁面數量計算。該服務的定價中包含了無限的抓取作業、無限且自動管理的代理網路以及電子郵件支援。為了清晰地估算成本,網站提供了一個計算器。例如,一個月內抓取10,000個頁面大約需要20美元。這種模式非常適合各種規模的專案,從小規模實驗到大規模資料操作,因為成本與使用量成正比。該平台還允許用戶在購買前試用服務,很可能是透過為新帳戶分配免費信用額度的方式。
Webcrawlerapi 評論 (0)
登入後即可發表評論
立即登入Webcrawlerapi網站流量分析
最新流量情況
狀態
月度流量趨勢
地理位置
Top 5 國家/地區
-
🇺🇸 United States51.51%
-
🇮🇳 India14.82%
-
🇩🇪 Germany12.24%
-
🇪🇸 Spain11.01%
-
🇧🇷 Brazil10.42%
熱門關鍵詞
| 關鍵詞 | 每次點擊費用 |
|---|---|
|
$0.00
|
|
|
$0.00
|
|
|
$0.00
|
|
|
$0.00
|
|
|
$0.00
|
Webcrawlerapi 替代方案
查看全部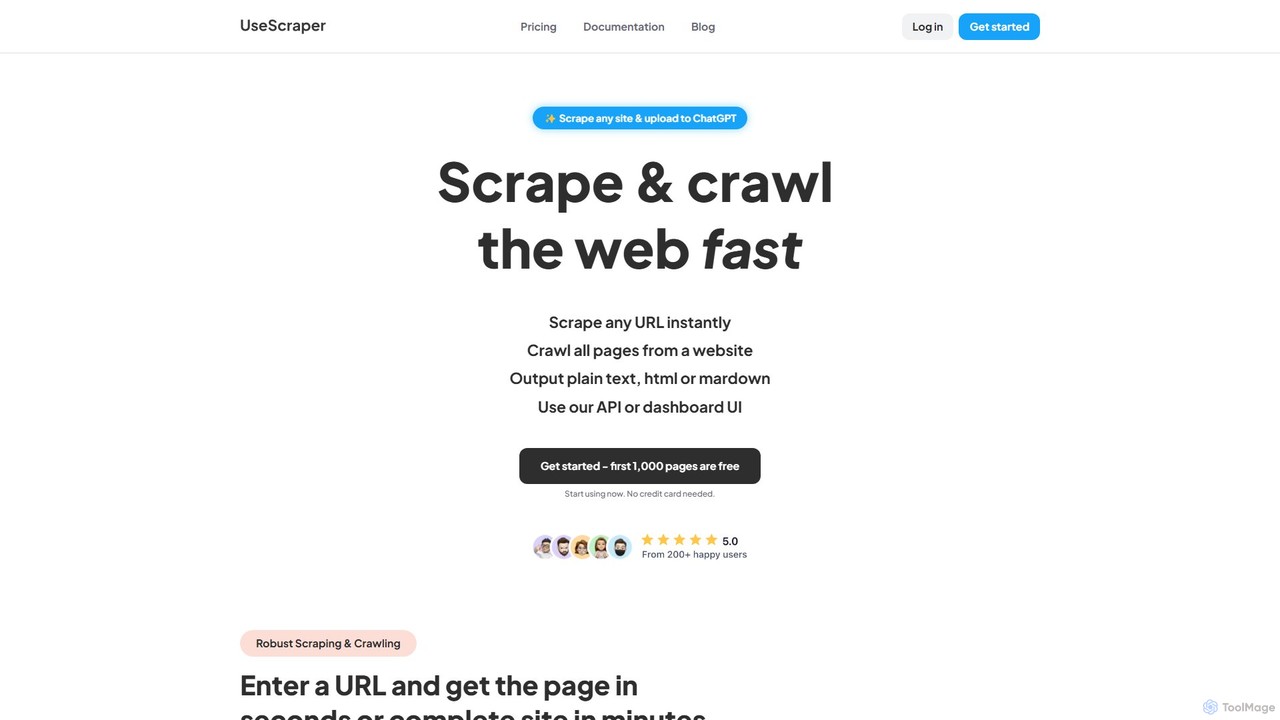
UseScraper
UseScraper 是一款功能強大的網路爬蟲和抓取 API,專為開發人員和 AI 應用而設計。它能高效地從任何網站提取數據,具有完整的 JavaScript 渲染、自動擴展的基礎設施以及清晰的 Markdown 等輸出格式,非常適合為 ChatGPT 等大型語言模型提供資料。
UseScraper 是一款功能強大的網路爬蟲和抓取 API,專為開發人員和 AI 應用而設計。它能高效地從任何網站提取數據,具有完整的 JavaScript 渲染、自動擴展的基礎設施以及清晰的 Markdown 等輸出格式,非常適合為 ChatGPT 等大型語言模型提供資料。

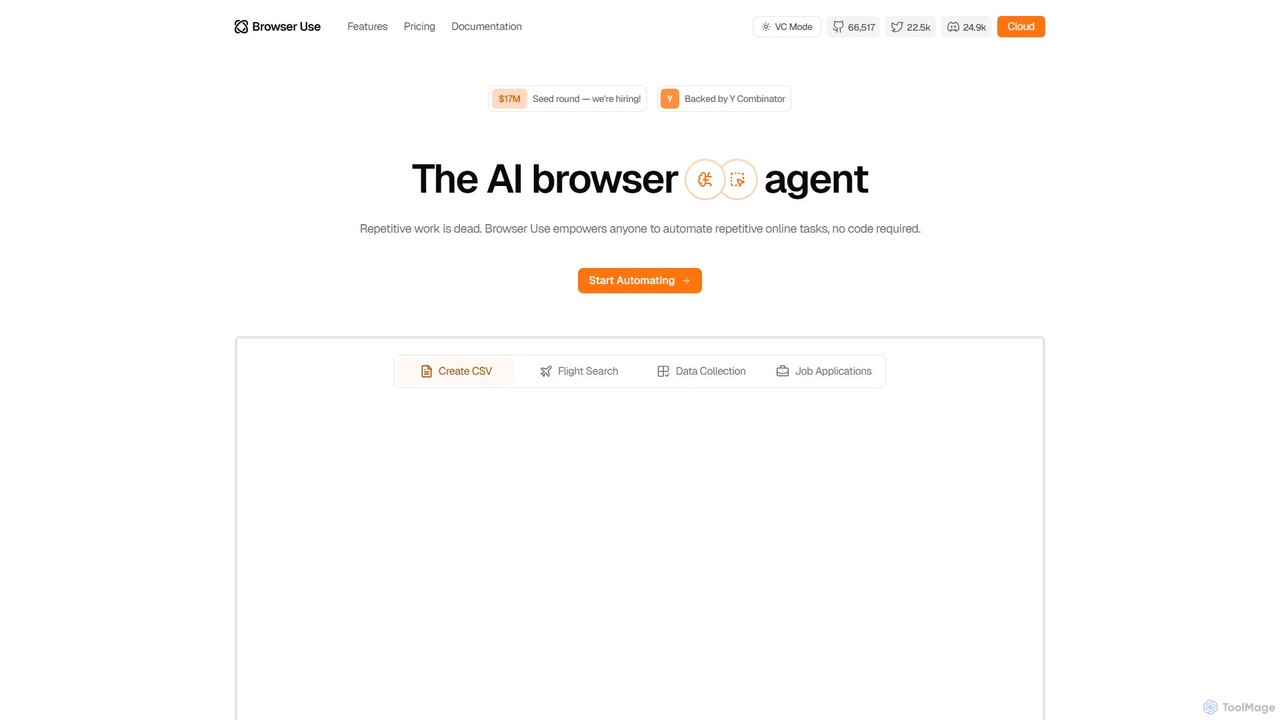
Browser Use
Browser Use 是一款由 AI 驅動的瀏覽器代理,無需任何程式碼即可自動執行重複性的線上任務。它可以處理複雜的資料擷取、表單填寫和其他基於 Web 的工作流程。該工具由 Y Combinator 支持,為使用者提供簡單的聊天介面,並為開發人員提供強大的 API,以簡化其線上活動。
Browser Use 是一款由 AI 驅動的瀏覽器代理,無需任何程式碼即可自動執行重複性的線上任務。它可以處理複雜的資料擷取、表單填寫和其他基於 Web 的工作流程。該工具由 Y Combinator 支持,為使用者提供簡單的聊天介面,並為開發人員提供強大的 API,以簡化其線上活動。
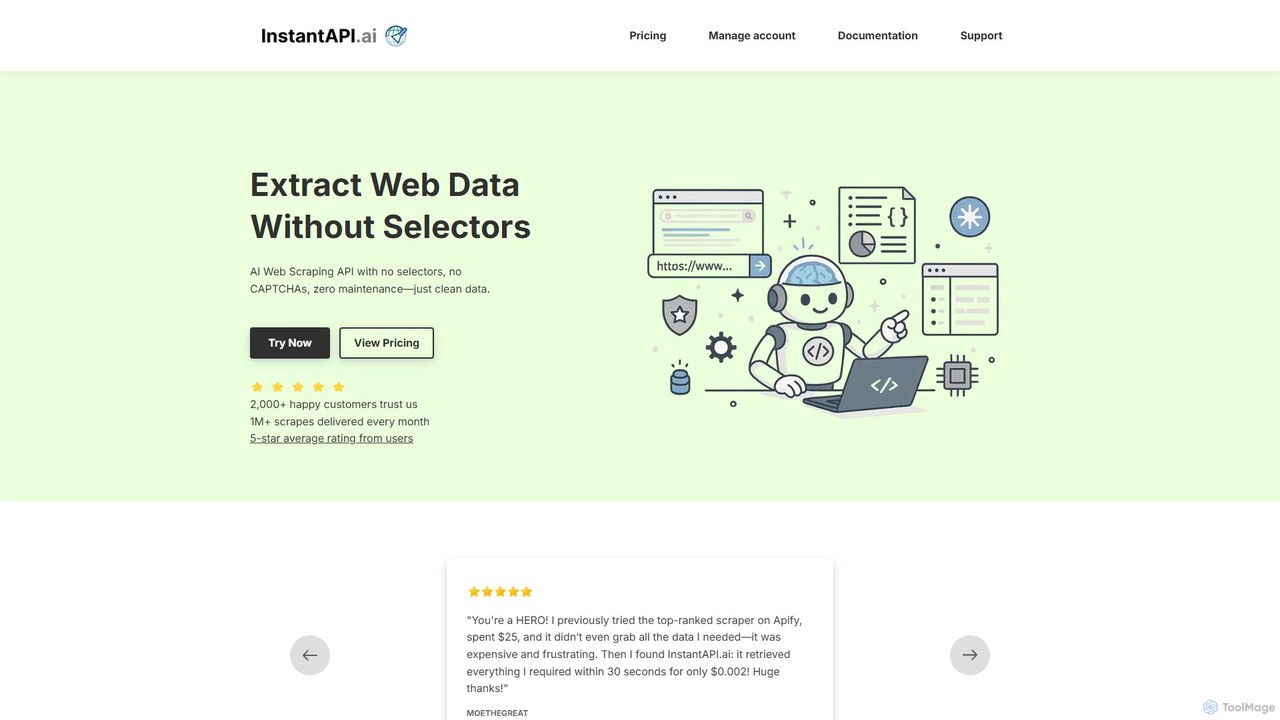
instantapi
instantapi 是一個由人工智能驅動的網頁抓取API,專為簡化和提速而設計。它允許用戶透過單個API調用從任何網站提取結構化數據,無需複雜的編碼或手動設定。對於需要快速、經濟、可靠的數據提取而又不想處理傳統網路爬蟲麻煩的開發人員、數據分析師和企業來說,這是一個理想的選擇。
instantapi 是一個由人工智能驅動的網頁抓取API,專為簡化和提速而設計。它允許用戶透過單個API調用從任何網站提取結構化數據,無需複雜的編碼或手動設定。對於需要快速、經濟、可靠的數據提取而又不想處理傳統網路爬蟲麻煩的開發人員、數據分析師和企業來說,這是一個理想的選擇。
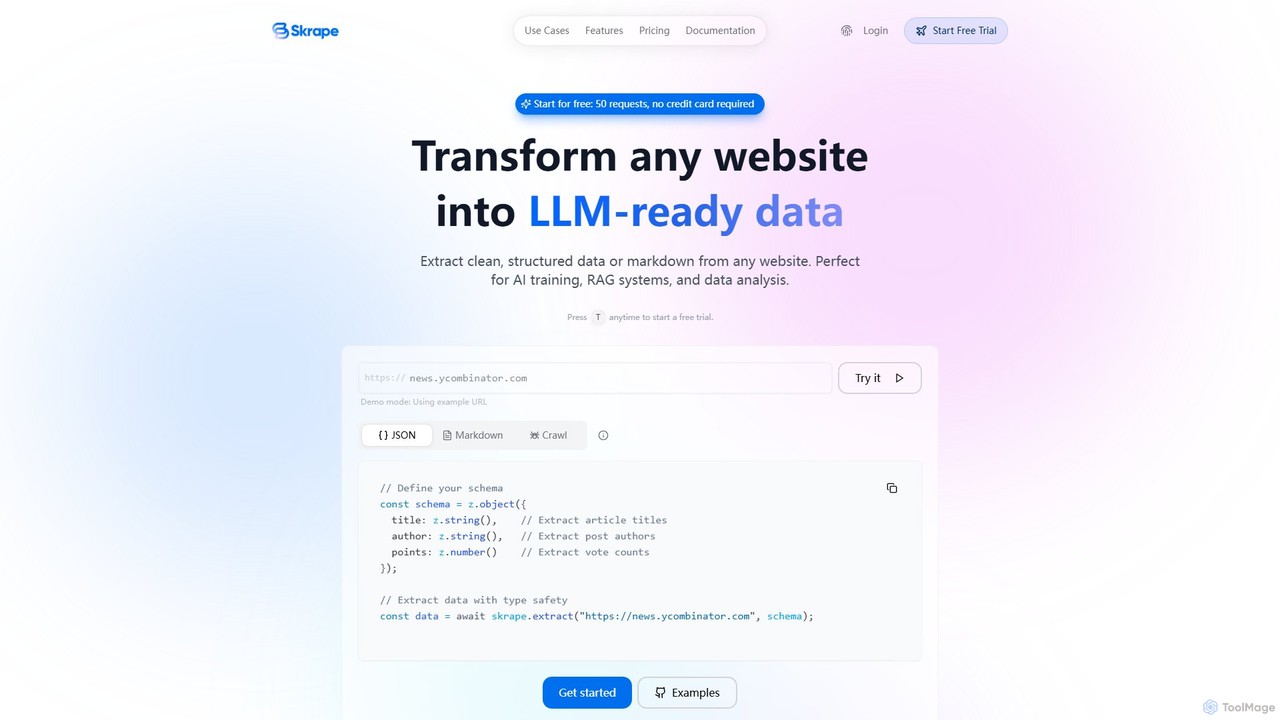
Skrape
Skrape 是一款由 LLM 驅動的網頁抓取 API,旨在將任何網站轉換為乾淨、結構化且適用於 LLM 的資料。它透過將網頁轉換為結構化 JSON 或純淨的 markdown 來簡化資料提取,是 AI 訓練、RAG 系統和資料分析的理想選擇。憑藉動態內容處理和智慧抓取等功能,Skrape 為開發人員和企業提供了自動化資料收集流程的可靠解決方案。
Skrape 是一款由 LLM 驅動的網頁抓取 API,旨在將任何網站轉換為乾淨、結構化且適用於 LLM 的資料。它透過將網頁轉換為結構化 JSON 或純淨的 markdown 來簡化資料提取,是 AI 訓練、RAG 系統和資料分析的理想選擇。憑藉動態內容處理和智慧抓取等功能,Skrape 為開發人員和企業提供了自動化資料收集流程的可靠解決方案。
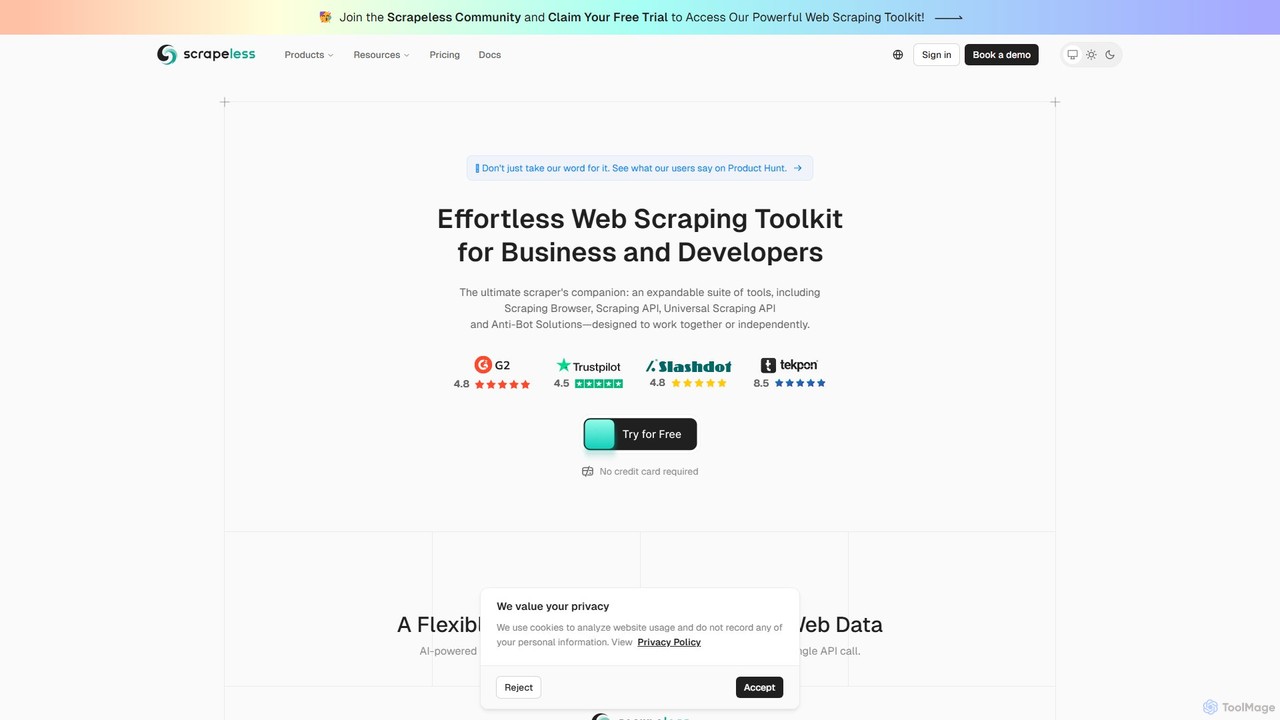
Scrapeless
一款為開發者和企業設計的AI驅動的網路爬蟲工具包。它提供包括爬蟲瀏覽器、通用爬蟲API和深度SERP API在內的一整套工具,可輕鬆大規模提取公共網路數據。它專注於繞過反機器人措施,為電子商務、市場研究和AI模型訓練提供結構化數據,並以可靠性和易用性為核心。
一款為開發者和企業設計的AI驅動的網路爬蟲工具包。它提供包括爬蟲瀏覽器、通用爬蟲API和深度SERP API在內的一整套工具,可輕鬆大規模提取公共網路數據。它專注於繞過反機器人措施,為電子商務、市場研究和AI模型訓練提供結構化數據,並以可靠性和易用性為核心。
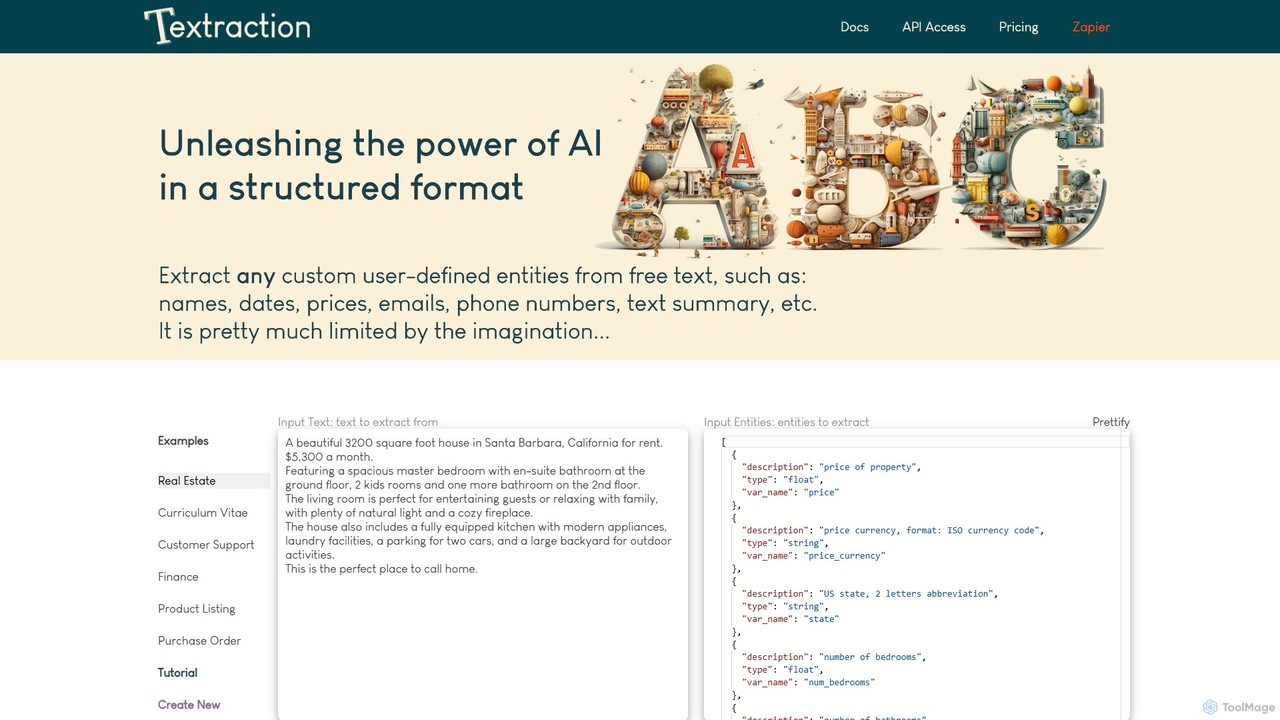
Textraction
Textraction 是一款強大的人工智慧API,可將非結構化文本轉換為結構化數據。只需用自然語言描述您需要的資訊,即可從文件、電子郵件或網頁內容中提取任何實體。透過無縫的API和Zapier整合,它能自動化數據提取過程,將雜亂的文本轉換為乾淨、可直接用於表格的JSON格式,支援多種語言和無限的自訂用例。
Textraction 是一款強大的人工智慧API,可將非結構化文本轉換為結構化數據。只需用自然語言描述您需要的資訊,即可從文件、電子郵件或網頁內容中提取任何實體。透過無縫的API和Zapier整合,它能自動化數據提取過程,將雜亂的文本轉換為乾淨、可直接用於表格的JSON格式,支援多種語言和無限的自訂用例。

Apify
Apify 是一個全端式網路爬蟲和自動化平台,使開發人員能夠建構、部署和發布被稱為「Actor」的資料提取工具。它提供了一個龐大的預建構爬蟲市場,適用於 Google 地圖、Instagram 和 TikTok 等熱門網站,並配有強大的雲端基礎設施用於創建自訂解決方案。憑藉對 Python 和 JavaScript、開源函式庫以及無縫整合的支援,Apify 簡化了任何規模的網路資料收集過程。
Apify 是一個全端式網路爬蟲和自動化平台,使開發人員能夠建構、部署和發布被稱為「Actor」的資料提取工具。它提供了一個龐大的預建構爬蟲市場,適用於 Google 地圖、Instagram 和 TikTok 等熱門網站,並配有強大的雲端基礎設施用於創建自訂解決方案。憑藉對 Python 和 JavaScript、開源函式庫以及無縫整合的支援,Apify 簡化了任何規模的網路資料收集過程。

CapSolver
CapSolver 是一款由人工智慧驅動的自動驗證碼識別服務,專為開發人員和RPA專業人士設計。它提供高準確率、快速且可擴展的解決方案,用於繞過包括 reCAPTCHA、hCaptcha 和 FunCaptcha 在內的各種驗證碼,從而實現無縫的網頁抓取、資料提取和流程自動化。
CapSolver 是一款由人工智慧驅動的自動驗證碼識別服務,專為開發人員和RPA專業人士設計。它提供高準確率、快速且可擴展的解決方案,用於繞過包括 reCAPTCHA、hCaptcha 和 FunCaptcha 在內的各種驗證碼,從而實現無縫的網頁抓取、資料提取和流程自動化。
Webcrawlerapi AI工具
Webcrawlerapi 嵌入功能
只需複製下方嵌入代碼,將精美徽章貼到您的博客、文章或應用官網,即可把流量直接引導到本工具詳情頁,快速提升曝光與用戶量!

還沒有評論,成為第一個評論者吧!