Serpex
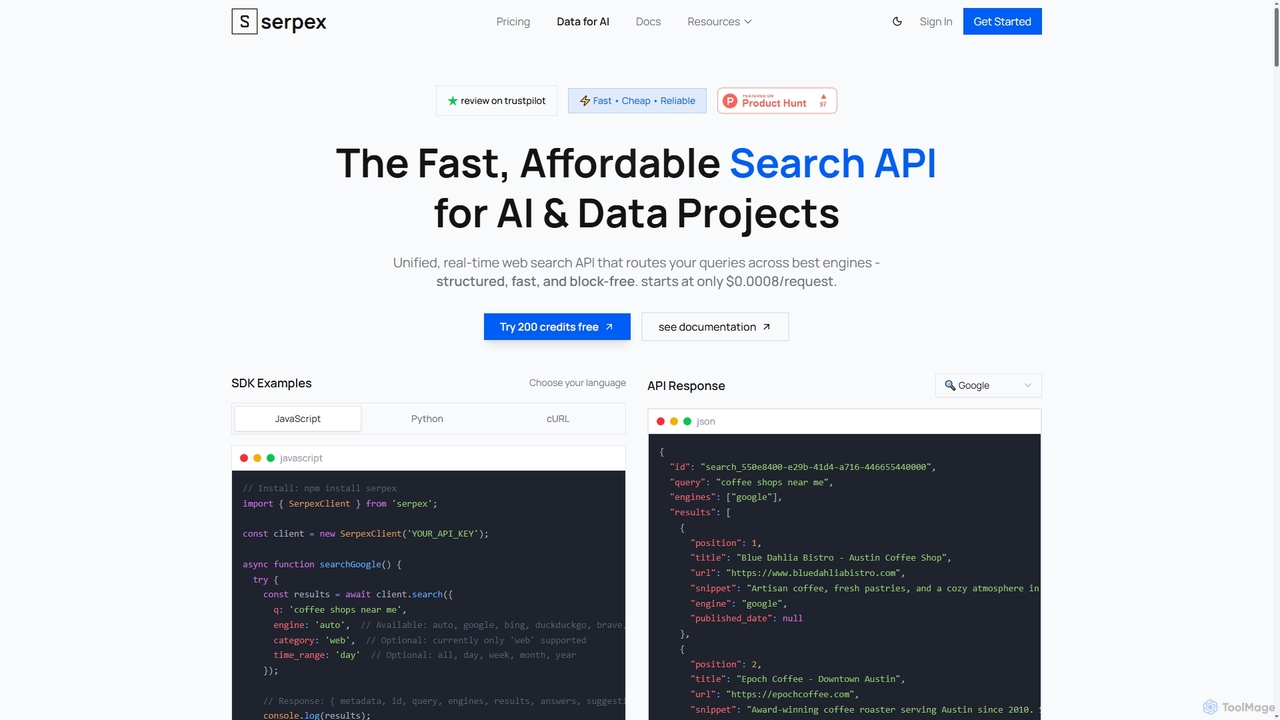
Serpex is a fast, affordable, and reliable search API designed for AI and data projects. It provides real-time, …
Serpex is a fast, affordable, and reliable search API designed for AI and data projects. It provides real-time, structured web search results from multiple major search engines, overcoming common challenges like CAPTCHAs and geo-blocks.
About Data Source
Data Source tools are platforms and services that provide curated, high-quality datasets essential for training, validating, and testing AI models. These tools offer access to a vast range of data types, including images, text, audio, and structured data, often pre-processed and annotated to accelerate machine learning workflows. They are a fundamental component of AI development, enabling developers and researchers to build robust and accurate systems without the prohibitive cost and time of collecting and labeling data from scratch. By providing ready-to-use or customizable datasets, these tools significantly lower the barrier to entry for creating sophisticated AI applications.
Core Features
- Diverse Dataset Libraries: Access to extensive collections of pre-existing, labeled datasets across various domains like computer vision and NLP.
- Synthetic Data Generation: Capability to create artificial data to augment real-world datasets, cover edge cases, or protect privacy.
- Data Annotation Services: Integrated or partnered services for labeling raw data to make it suitable for supervised learning models.
- Data Quality and Versioning: Features to ensure data consistency, manage different versions of datasets, and track data provenance for reproducibility.
- API and SDK Access: Programmatic access to download, stream, and manage datasets directly within development environments.
Use Cases
Data Source tools are critical for Machine Learning Engineers, Data Scientists, and AI Researchers. They are used for training computer vision models for object detection, developing natural language processing applications with large text corpora, and benchmarking the performance of new algorithms against established industry standards. These tools are invaluable in sectors like autonomous vehicles, healthcare for medical imaging analysis, and finance for fraud detection modeling.
How to Choose
When selecting a Data Source tool, consider the relevance and quality of the datasets for your specific problem. Evaluate the licensing and usage rights to ensure they align with your project's commercial or research goals. Assess the ease of integration through APIs and the platform's data management features, such as versioning. Finally, compare pricing models, whether they are open-source, subscription-based, or pay-per-use, to find a solution that fits your budget and project scale.
Data SourceUse Cases
Training a Computer Vision Model for Autonomous Driving
An AI startup developing perception systems for autonomous vehicles needs a vast and diverse dataset of road scenes. Instead of spending months and significant capital on collecting and manually annotating images, their ML team uses a Data Source platform. They access a pre-labeled dataset with millions of images containing pedestrians, vehicles, and traffic signs. This allows them to rapidly train and iterate on their object detection models, significantly accelerating their development cycle and improving model accuracy on critical edge cases.
Fine-tuning an NLP Model for Customer Support
A company wants to build a specialized chatbot for its technical support. General-purpose language models lack the specific jargon and problem-solving context of their industry. A data scientist on the team uses a Data Source tool to acquire a large corpus of anonymized technical support conversations and documentation. By fine-tuning their base language model on this domain-specific data, they create a chatbot that understands user issues with high accuracy and provides relevant solutions, reducing the workload on human agents.
Generating Synthetic Data for Medical Imaging
A research institute is developing an AI model to detect a rare disease from MRI scans. Due to patient privacy and the scarcity of cases, they have a very small dataset, which leads to model overfitting. The research team uses a Data Source tool with synthetic data generation capabilities. They generate thousands of realistic, yet artificial, MRI scans showing various stages of the disease. This augmented dataset allows them to train a more robust and generalized model, significantly improving its diagnostic accuracy without compromising patient confidentiality.
Benchmarking a New Recommendation Algorithm
An e-commerce company's data science team has developed a novel recommendation algorithm. To prove its effectiveness, they need to compare it against existing methods on a standardized dataset. They use a Data Source hub to download well-known public datasets like MovieLens or Amazon Reviews. This allows them to conduct a fair and reproducible experiment, measuring metrics like precision and recall. The results, benchmarked on a public dataset, provide a credible basis for deciding whether to deploy the new algorithm into production.
Training a Fraud Detection Model with Transactional Data
A fintech company aims to improve its real-time fraud detection system. Their internal data is limited and may not cover emerging fraudulent patterns. They subscribe to a Data Source service that provides large, anonymized, and regularly updated transactional datasets. By training their machine learning models on this extensive data, they can identify subtle correlations and anomalies indicative of fraud more effectively. This access to external data allows their system to stay ahead of evolving threats and reduce financial losses for their customers.
Localizing a Voice Assistant for New Markets
A tech company is expanding its AI-powered voice assistant to Southeast Asia. To ensure the assistant understands local accents and dialects, they need large amounts of high-quality speech data. Using a Data Source provider specializing in audio, they license multilingual speech datasets covering various languages and regional accents. This allows their speech recognition team to train and fine-tune models for each new market efficiently, ensuring a high-quality user experience from day one and accelerating their global expansion strategy.