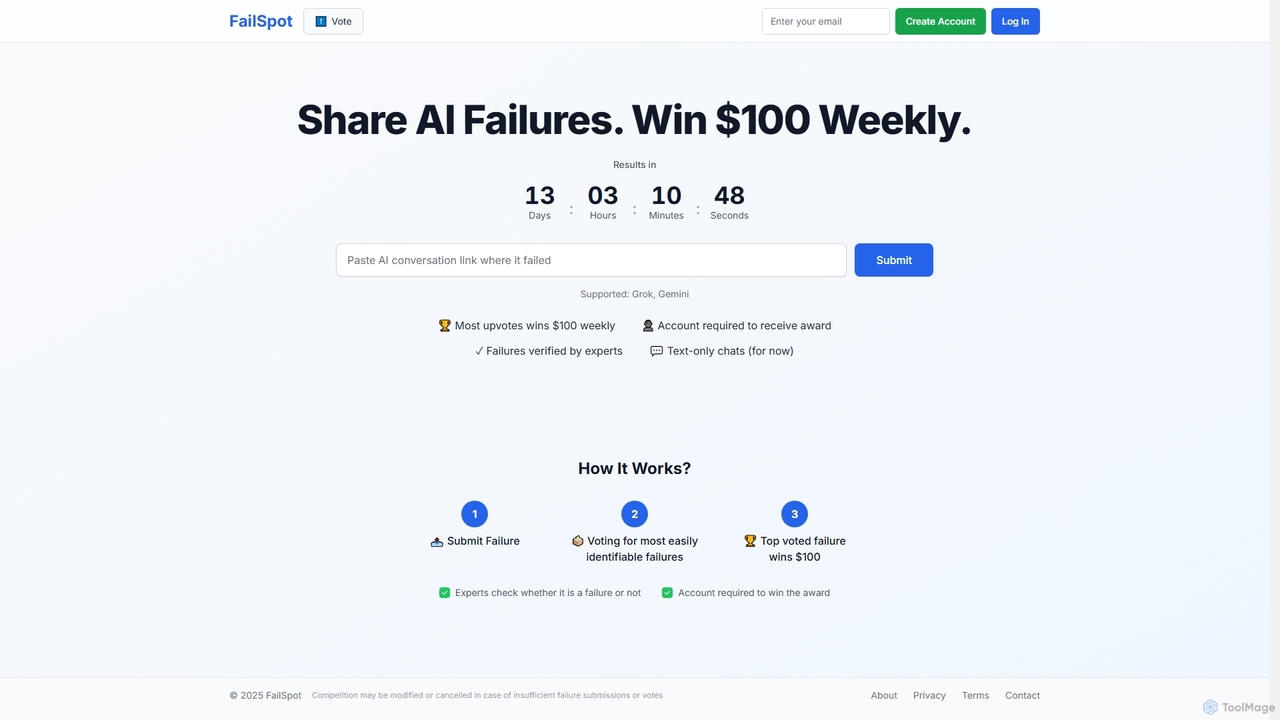
Failspot
Failspot is a community platform where users submit and vote on AI model failures, with experts verifying submissions. …
Failspot is a community platform where users submit and vote on AI model failures, with experts verifying submissions. The most upvoted failure wins a weekly $100 prize, fostering a collaborative environment for identifying and understanding AI limitations, particularly for models like Grok and Gemini.
About Evaluation
AI Evaluation tools are specialized platforms designed to rigorously assess the performance, fairness, robustness, and reliability of artificial intelligence models and systems. These sophisticated tools leverage advanced analytical techniques to quantify model behavior, identify potential biases, and detect vulnerabilities, ensuring that AI applications meet their intended objectives and perform ethically and predictably in real-world scenarios. As a critical component within the broader AI Testing framework, evaluation tools provide the necessary insights to validate model quality, track performance over time, and ensure compliance with regulatory standards, both before and after deployment.
Core Features
- Comprehensive Performance Metrics: Automatically computes a wide array of standard and custom metrics such as accuracy, precision, recall, F1-score, AUC, RMSE, and MAE, tailored for various model types including classification, regression, and generative AI. This allows for a granular understanding of model effectiveness.
- Bias & Fairness Analysis: Identifies and quantifies algorithmic biases across different demographic groups, sensitive attributes, or data segments. Tools offer various fairness metrics (e.g., disparate impact, equal opportunity) and visualization techniques to support ethical AI development and mitigate discriminatory outcomes.
- Robustness Testing & Adversarial Defense: Evaluates model resilience against adversarial attacks, data perturbations, noise injection, and unexpected inputs. This feature helps uncover vulnerabilities and ensures stable, reliable performance even under challenging or malicious conditions.
- Explainability (XAI) Integration: Provides actionable insights into model decision-making processes, helping users understand why a model made a particular prediction. Techniques like SHAP, LIME, and feature importance are often integrated to enhance transparency and build trust in AI systems.
- Continuous Monitoring & Data Drift Detection: Monitors deployed models for shifts in input data distributions (data drift), concept drift, or performance degradation over time. Automated alerts and dashboards enable proactive intervention, ensuring models remain relevant and accurate in dynamic environments.
Applicable Scenarios
Data scientists and machine learning engineers utilize AI Evaluation tools to rigorously validate new models before production deployment, ensuring they meet predefined performance benchmarks, ethical standards, and robustness requirements. AI product managers leverage these tools to compare different model versions, track their impact on key business performance indicators, and make informed decisions about model updates. Furthermore, compliance officers and auditors rely on these platforms to audit AI systems for regulatory adherence, transparency requirements, and to demonstrate accountability in AI-driven processes.
How to Choose
When selecting an AI Evaluation tool, consider its compatibility with your existing machine learning frameworks (e.g., TensorFlow, PyTorch) and the specific types of models you need to evaluate. Prioritize tools that offer a comprehensive range of evaluation metrics, robust capabilities for bias detection and explainability, and strong features for adversarial robustness testing. Look for seamless integration with your MLOps pipeline, scalable infrastructure to handle large datasets, intuitive reporting dashboards, and strong community support or vendor services to facilitate continuous monitoring and improvement of your AI assets.
EvaluationUse Cases
Validating a New Fraud Detection Model
A data scientist uses an AI evaluation tool to assess the precision, recall, and F1-score of a newly developed fraud detection model. They analyze false positives and negatives, identify potential biases against certain transaction types, and ensure the model's robustness against simulated adversarial attacks before deployment, aiming for a 95% accuracy rate with minimal false positives.
Ensuring Fairness in Loan Application Scoring
A financial institution's ML engineer employs an evaluation tool to analyze a credit scoring model for fairness. They check for disparate impact across different demographic groups (e.g., age, gender, ethnicity) and use fairness metrics to identify and mitigate biases, ensuring equitable access to credit and compliance with anti-discrimination regulations.
Benchmarking AI Model Performance for Product Features
An AI product manager uses evaluation tools to compare the performance of multiple natural language processing (NLP) models for a new customer service chatbot feature. They benchmark response accuracy, latency, and user satisfaction scores across different model versions to select the most effective and efficient solution for production.
Monitoring Deployed AI Models for Performance Degradation
An MLOps team integrates an evaluation tool into their production pipeline to continuously monitor a recommendation engine. The tool automatically detects data drift in user behavior patterns and concept drift in item popularity, alerting the team to potential performance drops and triggering model retraining to maintain recommendation relevance and accuracy.
Auditing AI Systems for Regulatory Compliance
A compliance officer in the healthcare sector uses an AI evaluation platform to audit a diagnostic AI model. They verify the model's explainability by generating LIME/SHAP explanations for specific predictions, assess its robustness against data variations, and document fairness metrics to demonstrate adherence to privacy regulations and ethical AI guidelines.
Testing AI Model Robustness Against Adversarial Attacks
A cybersecurity researcher utilizes an AI evaluation tool to test the vulnerability of a computer vision model used in autonomous vehicles. They generate adversarial examples (e.g., slight image perturbations) to trick the model into misclassifying objects, identifying weaknesses that could be exploited and informing strategies to enhance the model's security and reliability.