Kubiks
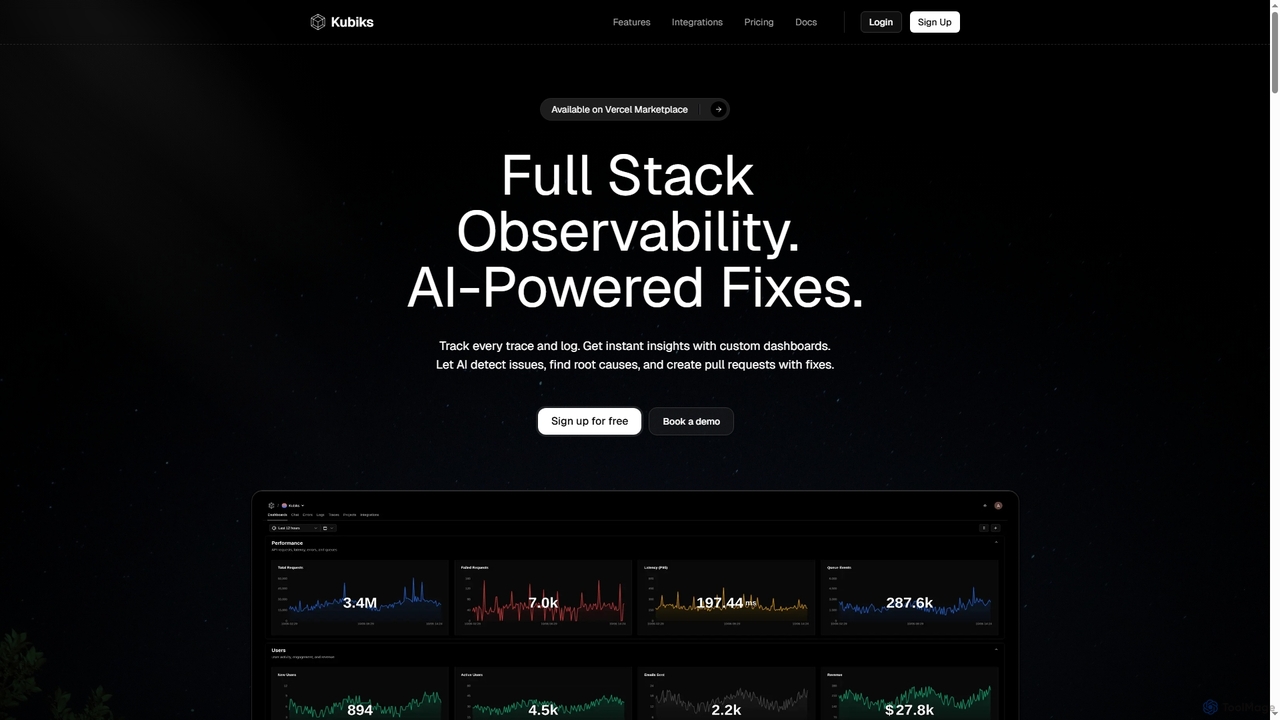
Kubiks is an AI-powered full-stack observability platform providing distributed tracing, logging, and custom dashboards. It automatically detects issues, …
Kubiks is an AI-powered full-stack observability platform providing distributed tracing, logging, and custom dashboards. It automatically detects issues, identifies root causes, and generates pull requests with fixes, helping engineering teams debug faster and proactively resolve problems.
About Site Reliability Engineering
Site Reliability Engineering (SRE) is a discipline that applies software engineering principles to infrastructure and operations problems, aiming to create highly reliable and scalable systems. It leverages automation, data-driven decision-making, and a focus on service level objectives (SLOs) to ensure the stability and performance of critical services. As a core component within the broader Operations category, SRE tools empower teams to proactively manage system health, respond efficiently to incidents, and continuously improve service reliability.
Core Features
- SLO/SLA Monitoring: Track and report on service level objectives and agreements to ensure performance targets are met.
- Incident Management & Automation: Streamline incident detection, alerting, response, and resolution processes through automated workflows.
- Error Budget Management: Define and track acceptable levels of unreliability, guiding development and operational priorities.
- Observability & Monitoring: Provide comprehensive insights into system behavior through logs, metrics, and traces for proactive issue identification.
- Capacity Planning: Forecast resource needs and optimize infrastructure to handle anticipated loads and prevent outages.
Applicable Scenarios
SRE tools are essential for organizations running complex, distributed systems, such as large-scale e-commerce platforms, SaaS providers, and financial services. They enable SRE teams, DevOps engineers, and platform engineers to maintain high availability, manage microservices reliability, and automate critical operational tasks, ensuring seamless user experiences and business continuity.
How to Choose
When selecting SRE tools, prioritize solutions that offer robust observability features, seamless integration with existing CI/CD pipelines and cloud platforms, and comprehensive incident management capabilities. Consider the tool's scalability, reporting features for SLO compliance, and its ability to support error budget tracking. User-friendliness and community support are also crucial for effective team adoption.
Site Reliability EngineeringUse Cases
Automating Incident Response Workflows
For on-call engineers and SRE teams, AI-powered SRE tools automate the detection of anomalies and critical incidents across distributed systems. They can trigger alerts, initiate diagnostic scripts, and even suggest remediation steps based on historical data, significantly reducing mean time to resolution (MTTR) and minimizing service disruption during critical outages.
Monitoring and Enforcing Service Level Objectives (SLOs)
SRE teams utilize these tools to define, monitor, and enforce Service Level Objectives (SLOs) for critical services. The tools continuously collect and analyze metrics (e.g., latency, error rate, availability), providing real-time dashboards and alerts when SLOs are at risk, allowing teams to proactively address performance degradation before it impacts users.
Proactive Capacity Planning and Resource Optimization
Infrastructure architects and SREs leverage SRE tools for data-driven capacity planning. By analyzing historical usage patterns and predicting future demand, these tools help optimize resource allocation, prevent bottlenecks, and ensure that systems can scale efficiently to meet traffic spikes, thereby avoiding costly over-provisioning or service outages due to under-provisioning.
Conducting Blameless Post-Mortem Analysis
After an incident, SRE tools facilitate comprehensive post-mortem analysis by aggregating logs, metrics, and traces from various sources. This enables SRE and development teams to identify root causes, understand contributing factors, and document lessons learned without assigning blame, fostering a culture of continuous improvement and preventing recurrence of similar issues.
Implementing and Managing Error Budgets
Product owners and SREs use these tools to implement and manage error budgets, which quantify the acceptable amount of unreliability for a service. The tools track the consumption of the error budget in real-time, providing clear signals to product and engineering teams on when to prioritize reliability work over new feature development, balancing innovation with stability.
Enhancing Observability Across Complex Distributed Systems
Platform engineers and SREs deploy these tools to gain deep observability into microservices architectures and cloud-native applications. By correlating metrics, logs, and traces across hundreds or thousands of services, the tools provide a unified view of system health, enabling rapid debugging, performance tuning, and a holistic understanding of system behavior.