
BenchLLM 概要
BenchLLMは、AIエンジニアによってAIエンジニアのために丹念に作られた、専門的なオープンソースの評価フレームワークです。大規模言語モデル(LLM)を搭載したアプリケーションにおける信頼性と予測可能性を確保するという重要な課題に直接取り組みます。AIモデルがより強力になり、製品に統合されるにつれて、体系的なテストの必要性は「あれば尚良い」ものから、開発ライフサイクルの不可欠な部分へと変化しました。BenchLLMは、LLMの確率的な性質と、決定論的で高品質なパフォーマンスへの要求との間のギャップを埋めるツールを提供します。
このフレームワークは、強力かつ柔軟に設計されており、開発者が包括的なテストスイートを作成、管理、実行できるようにします。これらのテストは、事実の正確性、ハルシネーションの検出から、特定の出力形式の遵守まで、モデルのパフォーマンスの様々な側面を評価できます。これらの評価を開発ワークフローに直接統合することで、チームは自信を持って構築し、リグレッションを早期に発見し、一貫して優れたユーザーエクスペリエンスを提供できます。
BenchLLMの使い方
BenchLLMの使用は直感的で、既存の開発ワークフローに適合するように設計されています。プロセスは通常、いくつかの主要なステップで構成されます:
- インストール: Pythonライブラリとして、BenchLLMはpipのようなパッケージマネージャを使用してプロジェクト環境に簡単にインストールできます。
- テストの定義: YAMLやJSONのようなシンプルで人間が読みやすい形式を使用して、直感的にテストケースを定義できます。各テストケースは、入力プロンプトと1つ以上の期待される出力で構成されます。これにより、テストをソースコードと一緒に保存できるため、バージョン管理と共同作業が容易になります。
- コードとの統合: BenchLLMは、LLMを呼び出す関数をラップするためのシンプルなAPIを提供します。OpenAIライブラリを直接使用している場合でも、LangchainエージェントやカスタムAPIを使用している場合でも、BenchLLMテスターに簡単に接続できます。
- テストの実行: テストは、強力なコマンドラインインターフェース(CLI)を使用するか、Python APIを介してプログラムで実行できます。CLIコマンド `bench run` は、定義されたテストスイートを実行し、モデルから予測を生成します。
- 評価とレポート: テストを実行した後、`Evaluator`(例:`SemanticEvaluator`)を使用して、モデルの実際の出力を期待される出力と比較します。その後、BenchLLMは、どのテストが合格し、どのテストが失敗したかを明確に示す洞察に満ちたレポートを生成し、デバッグと改善に必要なコンテキストを提供します。
BenchLLMの主な機能
- 柔軟なテスト定義: 管理しやすいYAMLまたはJSONファイルでテストを作成・整理し、明確でバージョン管理されたテストスイートを実現します。
- 強力なCLI: 堅牢なコマンドラインインターフェースにより、評価の実行、レポートの生成、CI/CDパイプラインへのテストのシームレスな統合が可能になり、完全な自動化を実現します。
- 多機能なAPI: 開発者フレンドリーなPython APIにより、アプリケーションコード内で直接、オンザフライのテストやカスタム評価ロジックを実装できます。
- 複数の評価戦略: 完全一致、正規表現、高度な意味的類似性チェックなど、様々な評価方法をサポートし、モデルの出力品質を正確に評価します。
- 幅広い互換性: OpenAIやLangchainなどの人気ライブラリを標準でサポートし、任何のカスタムLLM APIとも連携できるように拡張可能です。
- 包括的なレポート: 失敗、パフォーマンスメトリクス、リグレッションを強調表示する、明確で実用的な評価レポートを生成し、チームと簡単に共有できます。
- 本番環境の監視: このフレームワークは、本番環境でのモデルのパフォーマンスを監視し、パフォーマンスのドリフトを検出して継続的な信頼性を確保するために使用できます。
BenchLLMの使用例
BenchLLMは多用途であり、AI開発ライフサイクル全体の多くのシナリオで適用できます。主な使用例には、CI/CDでのリグレッションテスト(新しい変更がモデルのパフォーマンスを低下させていないことを自動的に検証)、ハルシネーションの検出(既知の答えがない質問(例:未来の出来事)を含むテストを作成し、モデルが適切に応答することを確認)、モデルのベンチマーキング(同じテストスイートを異なるLLM(例:GPT-4対Claude 3)やプロンプトのバリエーションに対して実行し、パフォーマンスを客観的に測定・比較)、そして品質保証(すべてのモデルバージョンがデプロイ前に満たすべき品質基準を設定)があります。
BenchLLMの利点
BenchLLMの主な利点は、開発者第一の考え方で構築されていることです。一部のクローズドボックスソリューションとは異なり、エンジニアに評価プロセスに対する完全な制御を与える、オープンで柔軟なツールです。オープンソースであるため、最大限の透明性とカスタマイズ性を提供します。これにより、LLM開発は試行錯誤から、より構造化され予測可能なエンジニアリング分野へと変わります。退屈でエラーが発生しやすい手動テスト作業を自動化することで、開発サイクルを大幅に効率化し、製品の品質を向上させ、開発者の生産性を高めます。
料金プラン
BenchLLMは、V7のチームによって構築・維持されている完全に無料のオープンソースツールです。誰でもGitHubリポジトリからダウンロード、使用、貢献することができます。全機能を使用するために有料プラン、サブスクリプション、隠れたコストは一切必要なく、個人開発者、スタートアップ、大企業にとってアクセスしやすい選択肢となっています。
BenchLLM コメント (0)
ログインするとコメントを投稿できます
今すぐログインBenchLLM 代替案
すべて表示
codegate
Codegateは、AIエージェントシステム向けのオープンソースのセキュリティゲートウェイおよびマルチプレキシングフレームワークです。Stacklokによって開発され、安全なワークスペースとポリシーベースのアクセス制御を提供し、開発者が複雑なマルチエージェントアプリケーションを安全かつ効率的に構築・管理できるようにします。
Codegateは、AIエージェントシステム向けのオープンソースのセキュリティゲートウェイおよびマルチプレキシングフレームワークです。Stacklokによって開発され、安全なワークスペースとポリシーベースのアクセス制御を提供し、開発者が複雑なマルチエージェントアプリケーションを安全かつ効率的に構築・管理できるようにします。
vocode
Vocodeは、超リアルな音声AIエージェントを構築、デプロイ、スケーリングするためのオープンソースプラットフォームです。開発者に、自動化されたカスタマーサービス、営業電話、対話型音声応答(IVR)システムなどのタスク向けに、高度な音声ベースのLLMアプリケーションを作成するためのコアフレームワークとエンタープライズグレードのAPIを提供します。
Vocodeは、超リアルな音声AIエージェントを構築、デプロイ、スケーリングするためのオープンソースプラットフォームです。開発者に、自動化されたカスタマーサービス、営業電話、対話型音声応答(IVR)システムなどのタスク向けに、高度な音声ベースのLLMアプリケーションを作成するためのコアフレームワークとエンタープライズグレードのAPIを提供します。
Confident AI
Confident AIは、エンジニアリングチーム向けのLLM評価およびオブザーバビリティプラットフォームです。オープンソースのDeepEvalライブラリの作成者によって構築され、包括的なメトリクス、回帰テスト、詳細なトレースを通じてLLMアプリケーションのベンチマーク、保護、改善を支援し、一貫したAIパフォーマンスを保証します。
Confident AIは、エンジニアリングチーム向けのLLM評価およびオブザーバビリティプラットフォームです。オープンソースのDeepEvalライブラリの作成者によって構築され、包括的なメトリクス、回帰テスト、詳細なトレースを通じてLLMアプリケーションのベンチマーク、保護、改善を支援し、一貫したAIパフォーマンスを保証します。
CrewAI
CrewAIは、ロールプレイング型の自律AIエージェントを編成するための先進的なオープンソースフレームワークです。協調的知能を促進することで、異なる役割やツールを持つエージェントが複雑なタスクを解決するためにシームレスに連携することを可能にします。このマルチエージェントシステムは、エージェント間の対話、タスクの委任、ワークフロープロセスを管理し、自動コンテンツ作成から複雑なデータ分析まで、高度なアプリケーション開発を簡素化します。
CrewAIは、ロールプレイング型の自律AIエージェントを編成するための先進的なオープンソースフレームワークです。協調的知能を促進することで、異なる役割やツールを持つエージェントが複雑なタスクを解決するためにシームレスに連携することを可能にします。このマルチエージェントシステムは、エージェント間の対話、タスクの委任、ワークフロープロセスを管理し、自動コンテンツ作成から複雑なデータ分析まで、高度なアプリケーション開発を簡素化します。
CopilotKit
CopilotKitは、開発者がアプリ内AIコパイロットやエージェントアプリケーションを構築、デプロイ、カスタマイズするためのオープンソースのフルスタックフレームワークです。フロントエンドコンポーネント、バックエンドロジック、そしてあらゆるLLMやエージェントフレームワークとのシームレスな統合を提供し、強力なユーザー向けAIアシスタントの作成を可能にします。
CopilotKitは、開発者がアプリ内AIコパイロットやエージェントアプリケーションを構築、デプロイ、カスタマイズするためのオープンソースのフルスタックフレームワークです。フロントエンドコンポーネント、バックエンドロジック、そしてあらゆるLLMやエージェントフレームワークとのシームレスな統合を提供し、強力なユーザー向けAIアシスタントの作成を可能にします。
Blaxel
Blaxelは、AI開発者向けに設計されたサーバーレスコンピューティングプラットフォームであり、エージェント型AIアプリケーションを効率的に構築、デプロイ、スケーリングするためのインフラストラクチャとツールを提供します。サンドボックス化されたVM、統合LLMゲートウェイ、詳細な可観測性を特徴としています。
Blaxelは、AI開発者向けに設計されたサーバーレスコンピューティングプラットフォームであり、エージェント型AIアプリケーションを効率的に構築、デプロイ、スケーリングするためのインフラストラクチャとツールを提供します。サンドボックス化されたVM、統合LLMゲートウェイ、詳細な可観測性を特徴としています。
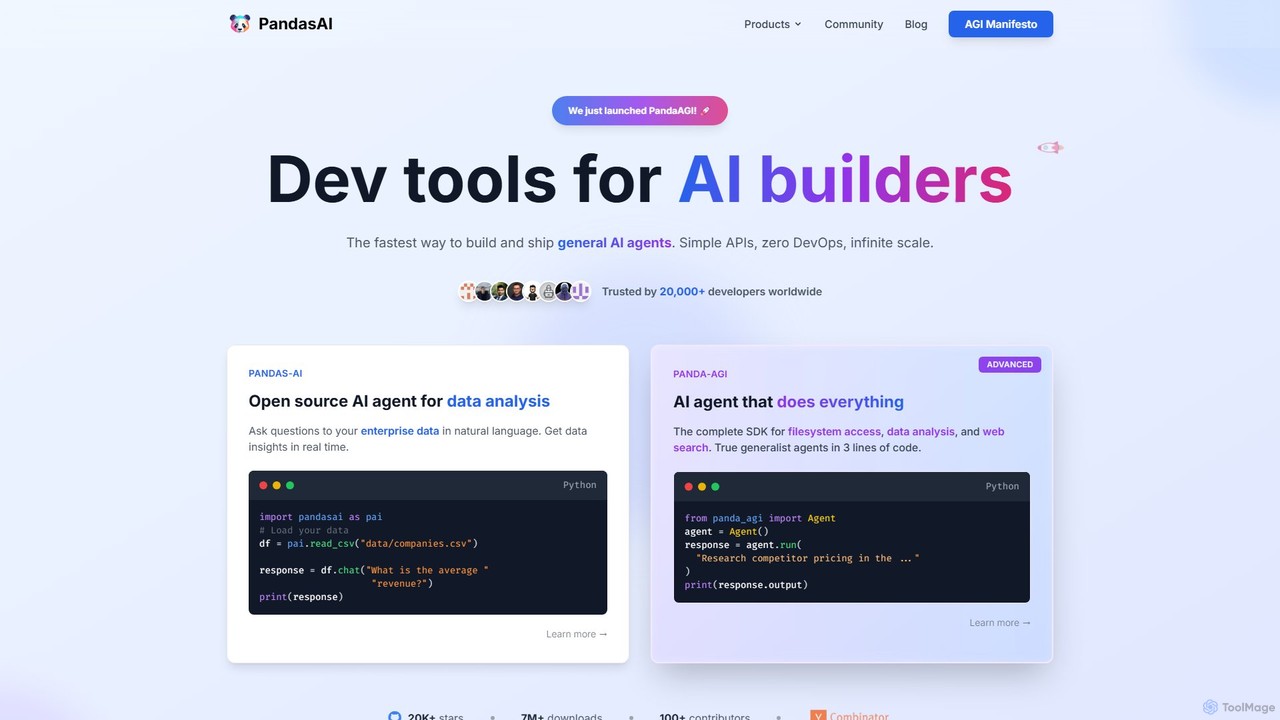
PandasAI
PandasAIは、AIアプリケーションを構築するための開発者向けツールスイートを提供します。自然言語を用いた対話型データ分析のためのオープンソースライブラリと、ウェブ検索やファイルシステムアクセスなどの複雑なタスクを実行できる汎用AIエージェントを作成するための高度なSDKであるPandaAGIが特徴です。
PandasAIは、AIアプリケーションを構築するための開発者向けツールスイートを提供します。自然言語を用いた対話型データ分析のためのオープンソースライブラリと、ウェブ検索やファイルシステムアクセスなどの複雑なタスクを実行できる汎用AIエージェントを作成するための高度なSDKであるPandaAGIが特徴です。
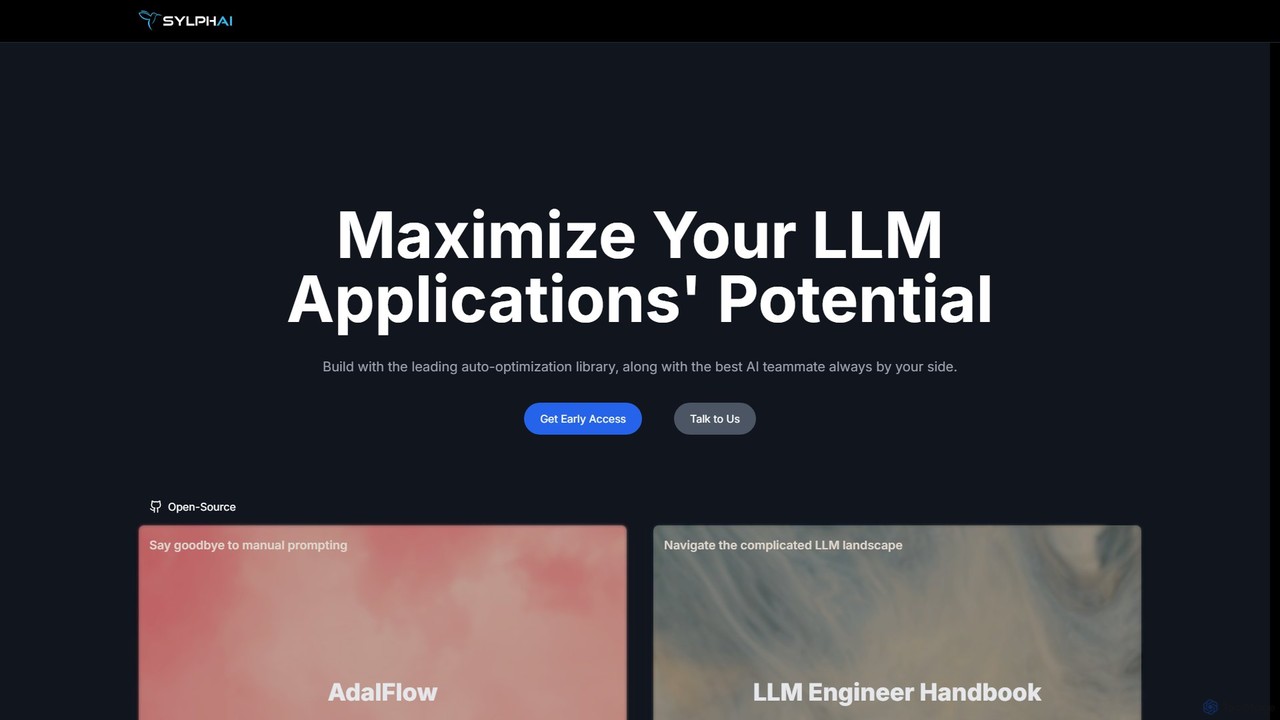
Sylph AI
Sylph AIは、LLMアプリケーションのポテンシャルを最大化するために設計された開発プラットフォームです。LLMタスクパイプラインを構築し自動最適化する主要なオープンソースライブラリ「AdalFlow」と、アイデア出しから本番稼働までの開発ワークフロー全体で専門的なガイダンスを提供する「AIチームメイト」を特徴としています。
Sylph AIは、LLMアプリケーションのポテンシャルを最大化するために設計された開発プラットフォームです。LLMタスクパイプラインを構築し自動最適化する主要なオープンソースライブラリ「AdalFlow」と、アイデア出しから本番稼働までの開発ワークフロー全体で専門的なガイダンスを提供する「AIチームメイト」を特徴としています。
BenchLLM AIツール
BenchLLM 埋め込み機能
下の埋め込みコードをコピーし、素敵なバッジをあなたのブログ、記事、またはアプリの公式サイトに貼り付けるだけで、このツールの詳細ページに直接トラフィックを誘導し、露出とユーザー数を素早く増やすことができます!

まだコメントはありません。最初のコメントをしてみませんか!