Agenta
Agentaは、チームが信頼性の高いLLMアプリケーションを構築するために設計されたオープンソースのLLMOpsプラットフォームです。プロンプト管理、体系的な評価、可観測性を単一の共同ワークフローに統合し、開発者、プロダクトマネージャー、ドメイン専門家が散在したプロセスから構造化された開発へと移行するのを支援します。
Agentaは、チームが信頼性の高いLLMアプリケーションを構築するために設計されたオープンソースのLLMOpsプラットフォームです。プロンプト管理、体系的な評価、可観測性を単一の共同ワークフローに統合し、開発者、プロダクトマネージャー、ドメイン専門家が散在したプロセスから構造化された開発へと移行するのを支援します。
Athina
Athinaは、チームがLLMアプリケーションを10倍速く構築、テスト、監視できるよう設計された共同AI開発プラットフォームです。プロンプトエンジニアリング、評価、実験、注釈付け、本番監視のための包括的なツールスイートを提供します。Athinaは技術者と非技術者の両方をサポートし、シームレスなコラボレーションと高品質で信頼性の高いAIシステムの展開を保証します。
Athinaは、チームがLLMアプリケーションを10倍速く構築、テスト、監視できるよう設計された共同AI開発プラットフォームです。プロンプトエンジニアリング、評価、実験、注釈付け、本番監視のための包括的なツールスイートを提供します。Athinaは技術者と非技術者の両方をサポートし、シームレスなコラボレーションと高品質で信頼性の高いAIシステムの展開を保証します。

LangWatch
LangWatchは、LLMアプリケーションを監視、評価、最適化するためのオールインワンのオープンソースプラットフォームです。シミュレートされたユーザー環境を通じてAIエージェントのテストに特化しており、チームが本番前にリグレッションやエッジケースを検出するのに役立ちます。このプラットフォームは、可観測性、評価、最適化、ガードレールを組み合わせ、AIアプリケーションの信頼性、安全性、パフォーマンスを保証します。
LangWatchは、LLMアプリケーションを監視、評価、最適化するためのオールインワンのオープンソースプラットフォームです。シミュレートされたユーザー環境を通じてAIエージェントのテストに特化しており、チームが本番前にリグレッションやエッジケースを検出するのに役立ちます。このプラットフォームは、可観測性、評価、最適化、ガードレールを組み合わせ、AIアプリケーションの信頼性、安全性、パフォーマンスを保証します。
deepchecks
Deepchecksは、LLMベースのアプリケーションを評価、検証、監視するためのエンドツーエンドのプラットフォームです。AIチームがAIの進捗を定義、測定、検証するのを支援し、開発からCI/CD、本番環境までのテストを合理化することで、高品質で信頼性の高いアプリケーションのリリースを保証します。
Deepchecksは、LLMベースのアプリケーションを評価、検証、監視するためのエンドツーエンドのプラットフォームです。AIチームがAIの進捗を定義、測定、検証するのを支援し、開発からCI/CD、本番環境までのテストを合理化することで、高品質で信頼性の高いアプリケーションのリリースを保証します。
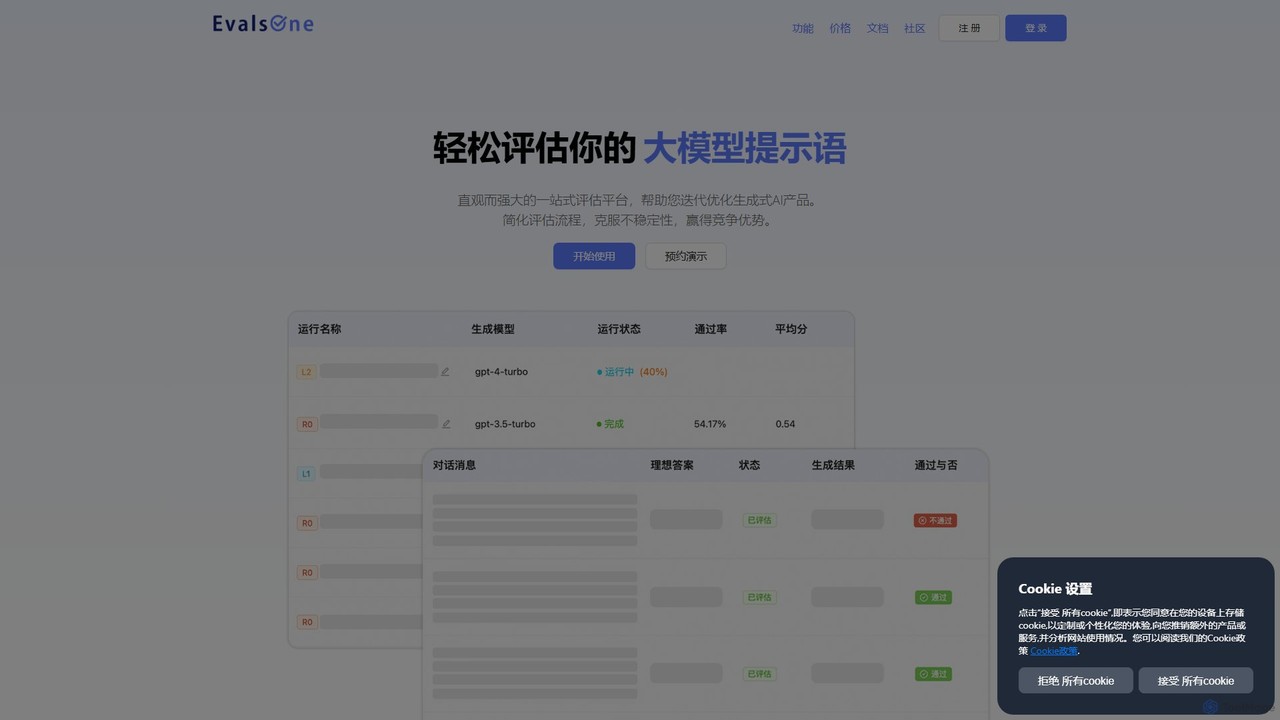
EvalsOne
EvalsOneは、生成AIアプリケーション向けに設計されたオールインワン評価プラットフォームです。強力で直感的なインターフェースを通じて、チームがLLMプロンプト、RAGパイプライン、AIエージェントを容易に評価、反復、最適化し、堅牢で競争力のあるAI製品を確保できるよう支援します。
EvalsOneは、生成AIアプリケーション向けに設計されたオールインワン評価プラットフォームです。強力で直感的なインターフェースを通じて、チームがLLMプロンプト、RAGパイプライン、AIエージェントを容易に評価、反復、最適化し、堅牢で競争力のあるAI製品を確保できるよう支援します。

Prompt Octopus
開発者向けのVSCode拡張機能で、プロンプトエンジニアリングを効率化します。コードベース内で直接、40以上のLLM(OpenAI、Anthropic、Mistralなど)の応答を並べて比較し、あらゆるタスクに最適なモデルを効率的に見つけるのに役立ちます。
開発者向けのVSCode拡張機能で、プロンプトエンジニアリングを効率化します。コードベース内で直接、40以上のLLM(OpenAI、Anthropic、Mistralなど)の応答を並べて比較し、あらゆるタスクに最適なモデルを効率的に見つけるのに役立ちます。
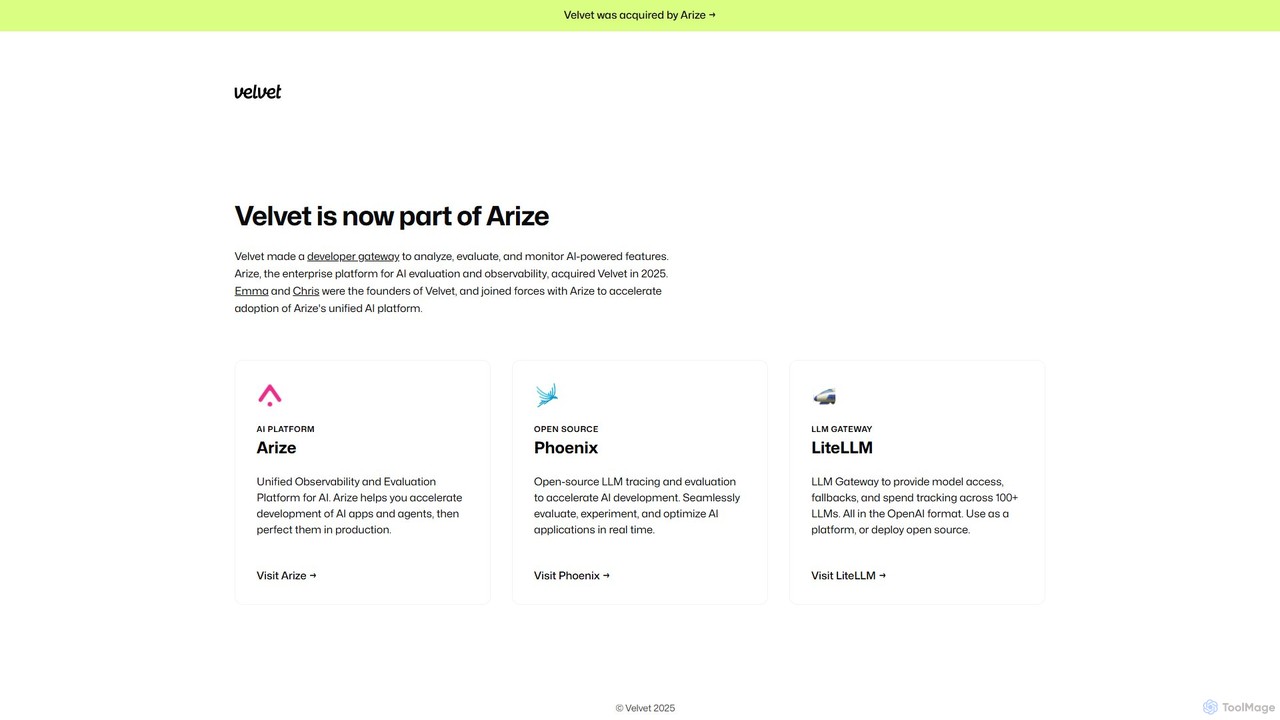
usevelvet
Velvetは、現在Arize AIの一部となっている開発者ゲートウェイで、AI搭載機能の分析、評価、監視のために設計されています。AIの可観測性、LLMの追跡、モデルのパフォーマンス管理のための包括的なスイートを提供し、開発者が開発から本番までAIアプリケーションを構築し、完成させるのを支援します。
Velvetは、現在Arize AIの一部となっている開発者ゲートウェイで、AI搭載機能の分析、評価、監視のために設計されています。AIの可観測性、LLMの追跡、モデルのパフォーマンス管理のための包括的なスイートを提供し、開発者が開発から本番までAIアプリケーションを構築し、完成させるのを支援します。

Ragas
Ragasは、検索拡張生成(RAG)パイプラインを評価・テストするためのオープンソースPythonフレームワークです。コンテキスト検索から回答生成まで、LLMアプリケーションのパフォーマンスを測定するための一連のメトリクスを提供します。LangChainやLlamaIndexなどの業界リーダーから信頼されており、幻覚や無関係な応答といった問題を特定・軽減することで、開発者がより堅牢で信頼性の高い、正確なAIシステムを構築するのを支援します。
Ragasは、検索拡張生成(RAG)パイプラインを評価・テストするためのオープンソースPythonフレームワークです。コンテキスト検索から回答生成まで、LLMアプリケーションのパフォーマンスを測定するための一連のメトリクスを提供します。LangChainやLlamaIndexなどの業界リーダーから信頼されており、幻覚や無関係な応答といった問題を特定・軽減することで、開発者がより堅牢で信頼性の高い、正確なAIシステムを構築するのを支援します。
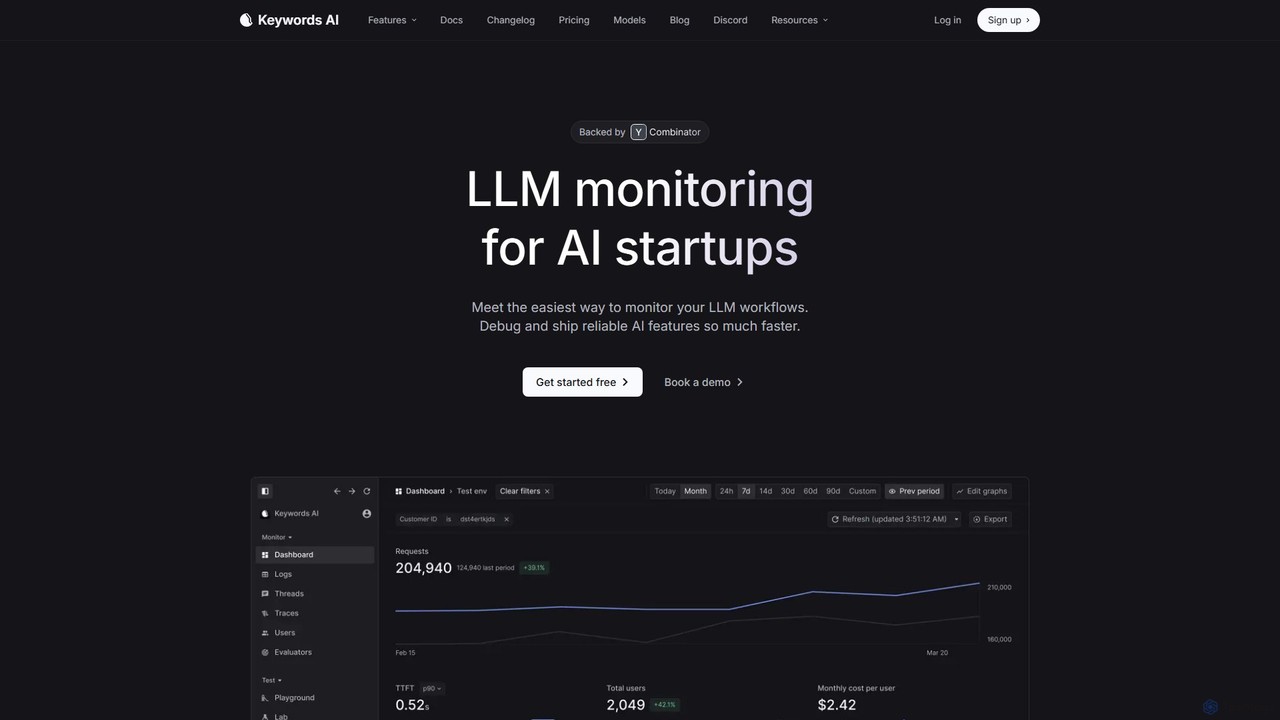
Keywords AI
Keywords AIは、AIスタートアップと開発者向けに設計された包括的なLLMオブザーバビリティ&モニタリングプラットフォームです。統一されたAPIを提供し、LLMワークフローのデプロイ、テスト、監視、最適化を行い、200以上のモデルをサポートします。簡単な2行のコード統合により、チームが信頼性の高いAI機能をより迅速に構築・提供できるよう支援します。
Keywords AIは、AIスタートアップと開発者向けに設計された包括的なLLMオブザーバビリティ&モニタリングプラットフォームです。統一されたAPIを提供し、LLMワークフローのデプロイ、テスト、監視、最適化を行い、200以上のモデルをサポートします。簡単な2行のコード統合により、チームが信頼性の高いAI機能をより迅速に構築・提供できるよう支援します。
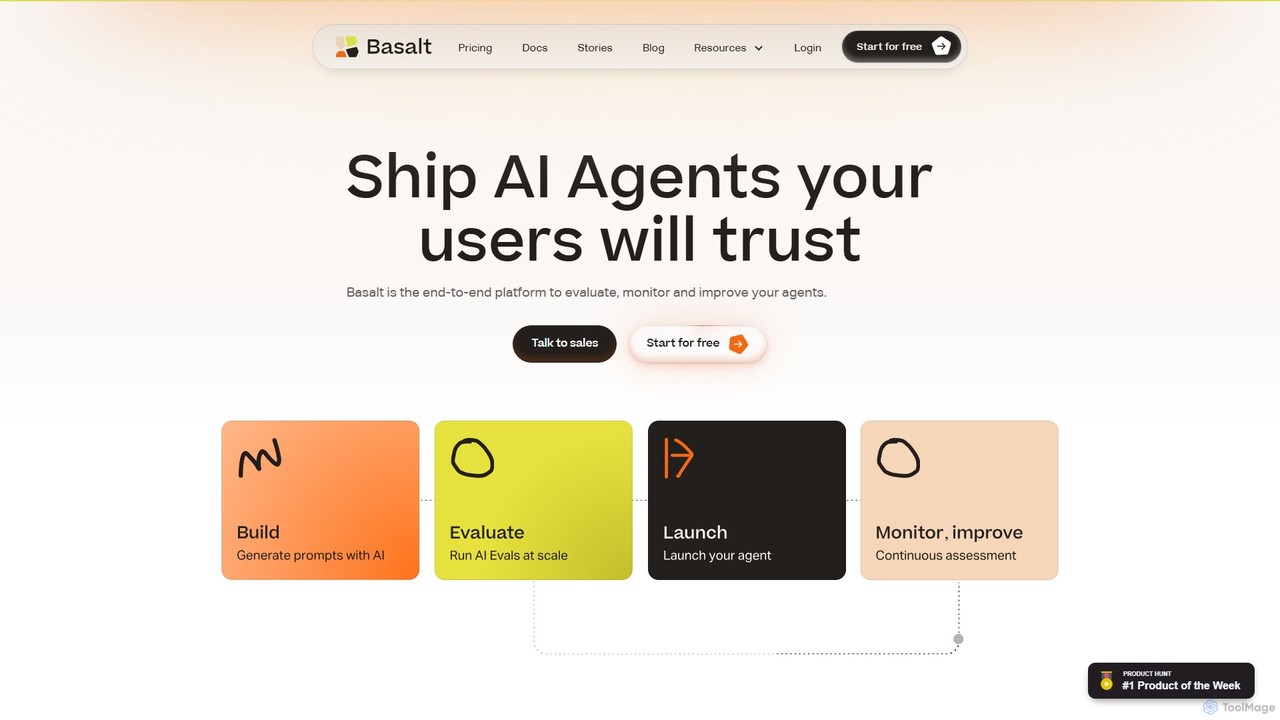
Basalt
Basaltは、開発者と製品チームが信頼性の高いAIエージェントを構築、評価、監視するためのエンドツーエンドプラットフォームです。自動評価、A/Bテスト、AIコパイロットによるプロンプトエンジニアリング、開発者フレンドリーなSDKなど、包括的なツールスイートを提供し、AI機能の信頼性と本番投入準備を確実にします。
Basaltは、開発者と製品チームが信頼性の高いAIエージェントを構築、評価、監視するためのエンドツーエンドプラットフォームです。自動評価、A/Bテスト、AIコパイロットによるプロンプトエンジニアリング、開発者フレンドリーなSDKなど、包括的なツールスイートを提供し、AI機能の信頼性と本番投入準備を確実にします。
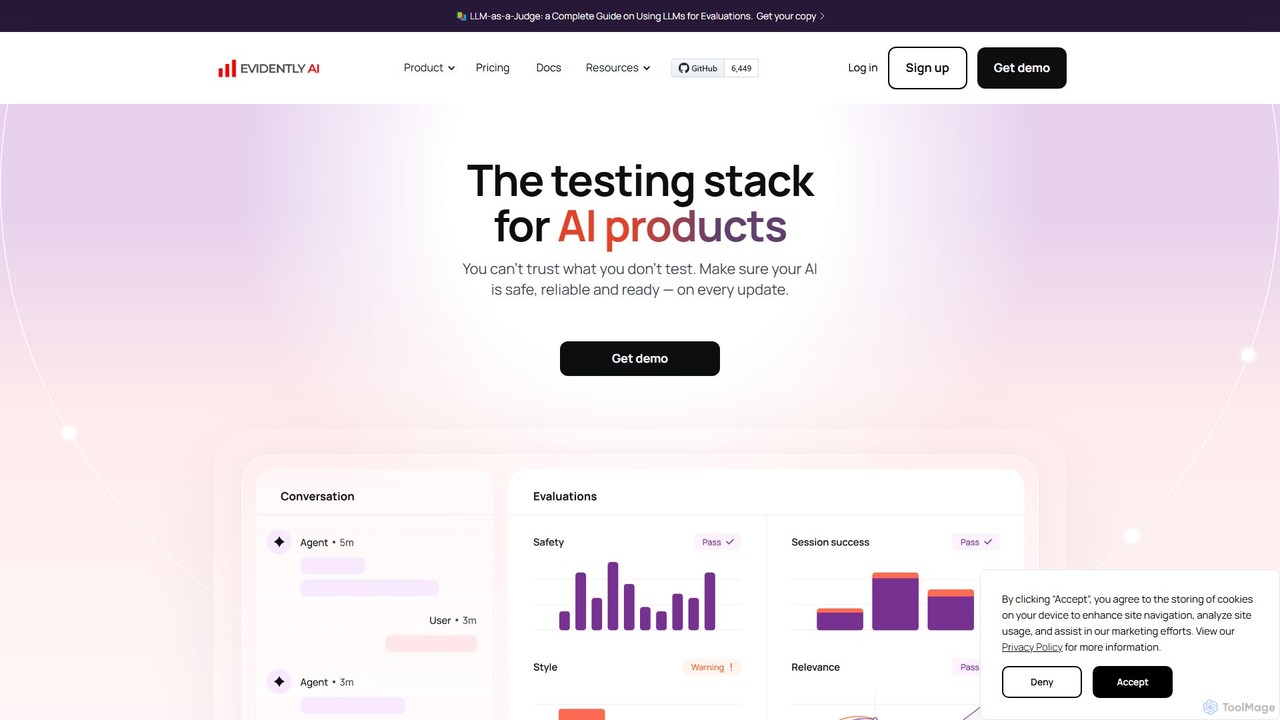
Evidently AI
Evidently AIは、LLMおよびMLモデルのモニタリングに特化した、AI製品向けの包括的なテスト・評価プラットフォームです。自動評価、合成データ生成、継続的テスト、敵対的攻撃を通じて、チームがAIの安全性、信頼性、パフォーマンスを確保するのを支援します。強力なオープンソースライブラリを基盤とし、データサイエンティストやMLOpsエンジニアが幻覚、データドリフト、PII漏洩などの問題をユーザーに影響が及ぶ前に検出できるよう設計されています。
Evidently AIは、LLMおよびMLモデルのモニタリングに特化した、AI製品向けの包括的なテスト・評価プラットフォームです。自動評価、合成データ生成、継続的テスト、敵対的攻撃を通じて、チームがAIの安全性、信頼性、パフォーマンスを確保するのを支援します。強力なオープンソースライブラリを基盤とし、データサイエンティストやMLOpsエンジニアが幻覚、データドリフト、PII漏洩などの問題をユーザーに影響が及ぶ前に検出できるよう設計されています。

Adaline
Adalineは、製品チームとエンジニアリングチームが大規模言語モデル(LLM)を反復、評価、デプロイ、監視するためのエンドツーエンドのプラットフォームです。AIアプリケーションのライフサイクル全体を合理化し、開発の高速化、コラボレーションの強化、AI搭載機能の信頼性の高いデプロイを実現します。
Adalineは、製品チームとエンジニアリングチームが大規模言語モデル(LLM)を反復、評価、デプロイ、監視するためのエンドツーエンドのプラットフォームです。AIアプリケーションのライフサイクル全体を合理化し、開発の高速化、コラボレーションの強化、AI搭載機能の信頼性の高いデプロイを実現します。
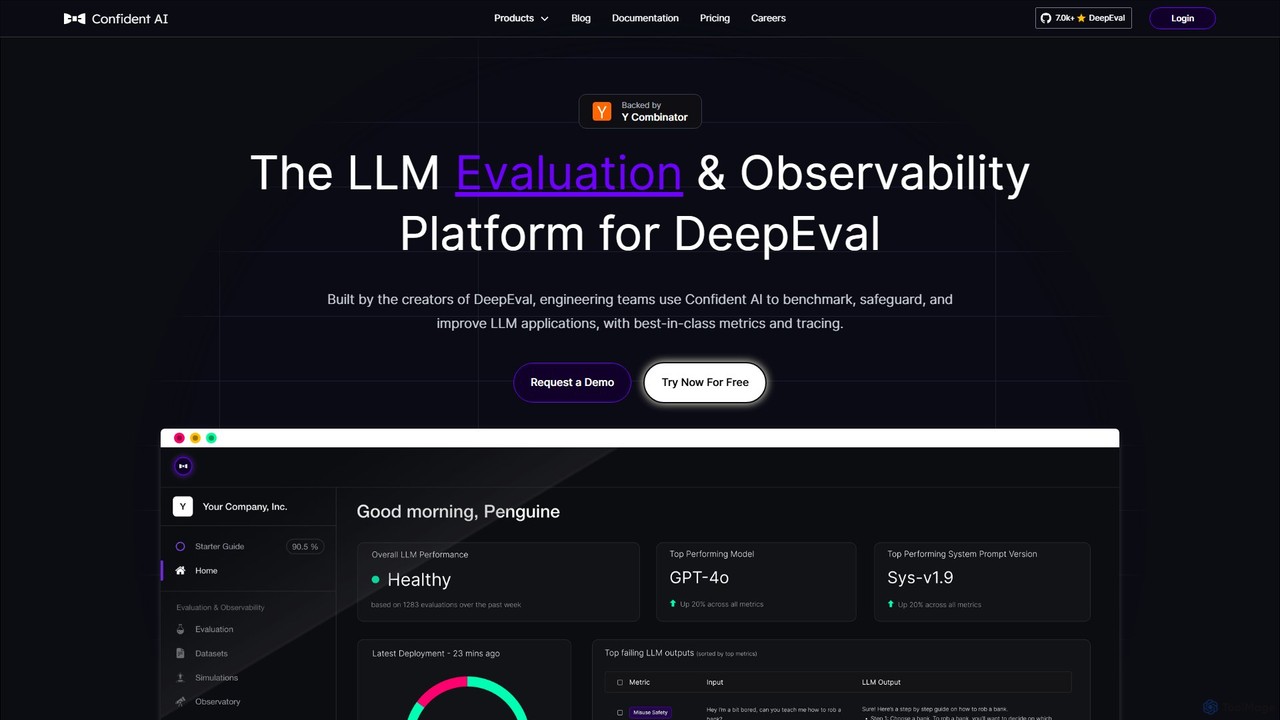
Confident AI
Confident AIは、エンジニアリングチーム向けのLLM評価およびオブザーバビリティプラットフォームです。オープンソースのDeepEvalライブラリの作成者によって構築され、包括的なメトリクス、回帰テスト、詳細なトレースを通じてLLMアプリケーションのベンチマーク、保護、改善を支援し、一貫したAIパフォーマンスを保証します。
Confident AIは、エンジニアリングチーム向けのLLM評価およびオブザーバビリティプラットフォームです。オープンソースのDeepEvalライブラリの作成者によって構築され、包括的なメトリクス、回帰テスト、詳細なトレースを通じてLLMアプリケーションのベンチマーク、保護、改善を支援し、一貫したAIパフォーマンスを保証します。
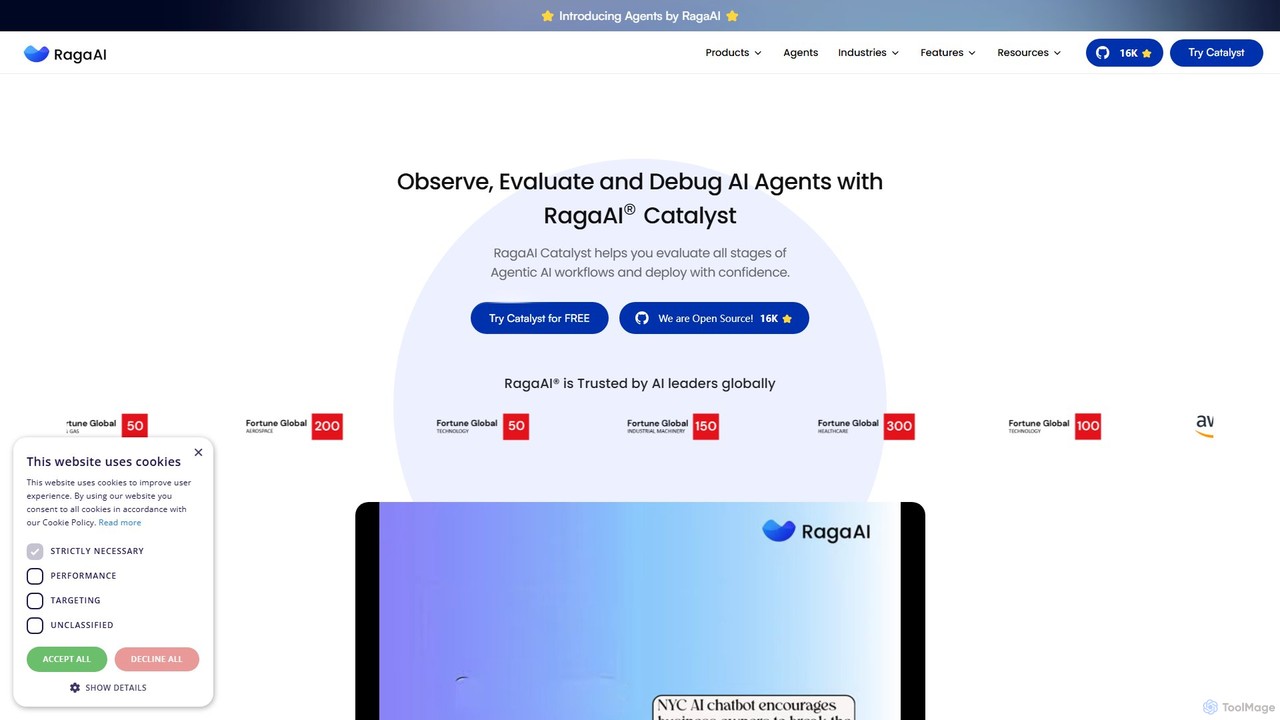
RagaAI
RagaAIは、開発者や企業が信頼性の高いAIアプリケーションを構築するのを支援するために設計された、包括的なAIテストおよびオブザーバビリティプラットフォームです。AIエージェント、LLM、RAGシステムを監視、評価、デバッグするための一連のツールを提供します。主な機能には、エージェントテスト、リアルタイムガードレール、合成データ生成、ファインチューニング機能が含まれます。RagaAIはマルチモーダルデータ(LLM、コンピュータビジョン、表形式データ)をサポートし、問題の検出から解決まで、AIの品質保証ライフサイクル全体を自動化し、堅牢で信頼性の高いAIの展開を目指します。
RagaAIは、開発者や企業が信頼性の高いAIアプリケーションを構築するのを支援するために設計された、包括的なAIテストおよびオブザーバビリティプラットフォームです。AIエージェント、LLM、RAGシステムを監視、評価、デバッグするための一連のツールを提供します。主な機能には、エージェントテスト、リアルタイムガードレール、合成データ生成、ファインチューニング機能が含まれます。RagaAIはマルチモーダルデータ(LLM、コンピュータビジョン、表形式データ)をサポートし、問題の検出から解決まで、AIの品質保証ライフサイクル全体を自動化し、堅牢で信頼性の高いAIの展開を目指します。
AfterQuery
AfterQueryは、高品質な人間生成データセットと汚染のないベンチマークを作成することで、基盤モデルの進化を目指すAI研究ラボです。優れたトレーニングデータと厳格な評価を通じて、モデルのパフォーマンス向上に焦点を当てています。
AfterQueryは、高品質な人間生成データセットと汚染のないベンチマークを作成することで、基盤モデルの進化を目指すAI研究ラボです。優れたトレーニングデータと厳格な評価を通じて、モデルのパフォーマンス向上に焦点を当てています。
promptfoo
promptfooは、大規模言語モデル(LLM)のための包括的なテスト・評価フレームワークです。開発者や企業が体系的なテスト、ベンチマーキング、AIによるレッドチーミングを通じて、プロンプトの品質比較、モデル性能の評価、AIセキュリティの強化を行うのを支援します。50以上のLLMプロバイダーとローカルモデルをサポートし、開発者フレンドリーなCLIで開発ワークフローにシームレスに統合できます。
promptfooは、大規模言語モデル(LLM)のための包括的なテスト・評価フレームワークです。開発者や企業が体系的なテスト、ベンチマーキング、AIによるレッドチーミングを通じて、プロンプトの品質比較、モデル性能の評価、AIセキュリティの強化を行うのを支援します。50以上のLLMプロバイダーとローカルモデルをサポートし、開発者フレンドリーなCLIで開発ワークフローにシームレスに統合できます。
BenchLLM
AIエンジニア向けに設計された、大規模言語モデル(LLM)アプリケーションを評価・テストするための強力なオープンソースフレームワークです。BenchLLMは、柔軟なAPIと堅牢なCLIを提供し、テストスイートの構築、品質レポートの生成、CI/CDパイプラインへのモデル評価の統合を可能にし、予測可能で高品質な結果を保証します。
AIエンジニア向けに設計された、大規模言語モデル(LLM)アプリケーションを評価・テストするための強力なオープンソースフレームワークです。BenchLLMは、柔軟なAPIと堅牢なCLIを提供し、テストスイートの構築、品質レポートの生成、CI/CDパイプラインへのモデル評価の統合を可能にし、予測可能で高品質な結果を保証します。
getmaxim
getmaximは、AI開発チーム向けに設計された包括的なGenAI評価およびオブザーバビリティプラットフォームです。ユーザーはLLMやRAGパイプラインの広範な評価、テストの自動化、リアルタイムのプロダクション監視を通じてAIアプリケーションをテスト、監視、改善し、高品質で信頼性が高く、責任あるAIを実現できます。
getmaximは、AI開発チーム向けに設計された包括的なGenAI評価およびオブザーバビリティプラットフォームです。ユーザーはLLMやRAGパイプラインの広範な評価、テストの自動化、リアルタイムのプロダクション監視を通じてAIアプリケーションをテスト、監視、改善し、高品質で信頼性が高く、責任あるAIを実現できます。
Giskard
Giskardは、LLMベースのアプリケーションを保護し、検証するために設計されたAIテストプラットフォームです。エンタープライズチームが展開前にハルシネーション、セキュリティ脆弱性、バイアス、パフォーマンス問題などのリスクを検出し、軽減するのを支援します。テスト生成の自動化と継続的なレッドチーム演習により、GiskardはAIエージェントの信頼性、安全性、コンプライアンスを保証します。
Giskardは、LLMベースのアプリケーションを保護し、検証するために設計されたAIテストプラットフォームです。エンタープライズチームが展開前にハルシネーション、セキュリティ脆弱性、バイアス、パフォーマンス問題などのリスクを検出し、軽減するのを支援します。テスト生成の自動化と継続的なレッドチーム演習により、GiskardはAIエージェントの信頼性、安全性、コンプライアンスを保証します。