
Evidently AI 概要
Evidently AIは、AI製品の安全性、信頼性、パフォーマンスを確保するために設計された堅牢なテスト・評価プラットフォームです。LLMの幻覚やデータ漏洩から、ジェイルブレイクや連鎖的なエラーに至るまで、AIシステムが従来のソフトウェアとは異なる独自の方法で障害を起こすことを認識し、Evidentlyは大規模言語モデル(LLM)と従来の機械学習(ML)モデルの両方をテスト、評価、モニタリングするための包括的なスタックを提供します。
このプラットフォームは、6,000以上のGitHubスターを持つ信頼されたオープンソースツールを基盤としており、透明性と拡張性を提供します。これにより、AIチームは単純な精度指標を超え、全体的なAI品質システムを構築できます。RAGパイプライン、AIエージェント、または予測分類器を開発している場合でも、Evidentlyはシステムの各コンポーネントを検証するために必要なツールを提供します。
Evidently AIの使い方
Evidently AIは、さまざまな開発および運用ニーズに適応できる柔軟なワークフローを提供します。ユーザーは主に2つの方法でプラットフォームと対話できます。
- Python SDKによるローカル評価:データサイエンティストやMLOpsエンジニアは、オープンソースのEvidently Pythonライブラリを使用して、既存のインフラストラクチャ内で直接評価を実行できます。これは、CI/CDパイプラインに回帰テストを統合したり、ローカルでのデータ分析に最適です。テスト実行後、ユーザーは集計されたレポート(JSONファイル)をEvidently Cloudにアップロードし、生データを送信することなく視覚化、追跡、共同作業を行うことができます。
- クラウドベースの評価:より統合された体験のために、ユーザーは生データ、トレース、またはログをEvidently Cloudプラットフォームに直接アップロードできます。そこから、ノーコードのインターフェースを使用して評価をトリガーし、モニタリングダッシュボードを設計し、アラートを設定し、テストデータセットを管理できます。このアプローチは、生ログへのアクセスが重要なLLMアプリケーションのデバッグに特に役立ちます。
プラットフォームはまた、MLflow、Prefect、FastAPIなどの一般的なMLOpsツールとの統合をサポートしており、既存のMLサービングおよびモニタリングのブループリントにシームレスに組み込むことができます。
Evidently AIの主な機能
- 包括的な評価指標:データ品質、データドリフト、モデルパフォーマンス(分類と回帰の両方)に関する100以上の組み込み指標にアクセスできます。これには、テキストデータと埋め込み用の専門的な指標も含まれます。
- LLM-as-a-Judge:強力なLLMを活用して、生成AI出力の品質を評価します。プラットフォームは、事実性、ガイドライン遵守、トーン、検索品質などの基準を評価するためのテンプレートを提供し、これらは簡単なテキストプロンプトでカスタマイズできます。
- 合成データ生成:特定のユースケースに合わせて、エッジケースや敵対的入力を含む多様で現実的なテストケースを作成します。これにより、システムの脆弱性を事前に特定できます。
- 継続的なテストとモニタリング:ライブのインタラクティブなダッシュボードを使用して、すべての更新にわたってモデルとデータのパフォーマンスを追跡します。これにより、パフォーマンスの低下、データドリフト、新たなリスクを早期に検出できます。
- 敵対的および安全性テスト:システム的にAIシステムを攻撃し、PII漏洩、有害コンテンツの生成、ジェイルブレイクプロンプトへの脆弱性などの脆弱性を調査します。
- RAGおよびAIエージェントのテスト:単一応答の評価を超えて、複数ステップのワークフローを検証します。RAGシステムの検索精度をテストし、AIエージェントの推論、ツール使用、目標達成を評価します。
- アラートとレポート:失敗したテストや指標のしきい値違反に対する自動アラートを設定します。AIシステムがどこで、なぜ故障したかを正確に示す、明確で共有可能なレポートを生成します。
Evidently AIの使用例
Evidently AIは、DeepL、Wise、Realtor.comなどのスタートアップから大企業まで、何千もの企業に信頼されています。
- RAG評価:チャットボットやナレッジシステムを構築するチームは、Evidentlyを使用して検索精度をテストし、幻覚を防ぎ、生成された回答の品質を確保します。
- 敵対的テスト:セキュリティを重視するチームは、このプラットフォームを使用して攻撃をシミュレートし、AIアプリケーションが機密データを漏洩したり、安全でない出力を生成したりしないことを確認します。
- AIエージェントの検証:複雑なAIエージェントの開発者は、Evidentlyを使用して、シミュレートされたインタラクションを通じて、複数ステップの推論、ツールの使用、全体的なタスクの成功を検証します。
- 予測システムのモニタリング:MLOpsチームは、Evidentlyを利用して本番環境の従来のMLモデル(分類器、要約器、推薦システムなど)をモニタリングし、データドリフトとモデルパフォーマンスを追跡して信頼性を維持します。
- データ品質保証:データサイエンティストは、探索的データ分析(EDA)中やCI/CDパイプラインの一部としてEvidentlyレポートを使用し、不安定な特徴を特定し、データ品質問題がモデルに影響を与えるのを防ぎます。
Evidently AIの利点
Evidently AIは、オープンソースの透明性とエンタープライズ級の機能の組み合わせで際立っています。
- ハイブリッドアプローチ:単一のプラットフォームでLLMと従来のMLモデルの両方をサポートします。
- オープンソースコア:基盤は、コミュニティで検証された評価の高いオープンソースライブラリであり、透明性と柔軟性を確保します。
- 包括的なツール:テストデータ生成から継続的な本番モニタリングまで、エンドツーエンドのソリューションを提供します。
- ユーザーフレンドリー:開発者向けのPython SDKと、より広範なチームコラボレーションのためのノーコードUIの両方を提供します。
- 実用的な洞察:チームがAIシステムを迅速にデバッグし、改善するのに役立つ明確なレポートとダッシュボードの提供に重点を置いています。
料金プラン
Evidently AIは、ユーザーのニーズに合わせて拡張できる階層型の料金モデルを提供しています。
- デベロッパープラン(無料):すべてのコア評価機能、月間10,000データ行、30日間のデータ保持、コミュニティサポートが含まれます。趣味のプロジェクトや初期の実験に最適です。
- プロプラン(月額50ドル):無料プランにアラート機能、月間100,000データ行、12ヶ月の保持期間、5シート、メールサポートが追加されます。本番AIシステムの改良とモニタリングに適しています。
- エキスパートプラン(月額399ドルから):合成データ生成や敵対的テストなどの高度な機能、月間200,000データ行、10シート、専任サポートが追加されます。複雑なAIエージェントやアプリケーションのテスト用に設計されています。
- エンタープライズプラン(カスタム):カスタム制限付きの全機能、オンプレミスまたはプライベートクラウドのデプロイオプション、プレミアムサポート、SLAを提供し、大規模にAIを管理する企業向けです。
Evidently AI コメント (0)
ログインするとコメントを投稿できます
今すぐログインEvidently AIウェブサイトトラフィック分析
最新のトラフィック状況
ステータス
月間トラフィックの傾向
地域
上位5か国/地域
-
🇺🇸 United States44.38%
-
🇺🇿 Uzbekistan17.31%
-
🇮🇳 India13.41%
-
🇻🇳 Vietnam13.41%
-
🇫🇷 France11.49%
トラフィックソース
| 参照元タイプ | パーセンテージ |
|---|---|
|
ダイレクトアクセス
|
64.06% |
|
リファラル
|
34.11% |
|
メール
|
1.83% |
人気キーワード
| キーワード | クリック単価 |
|---|---|
|
$2.20
|
|
|
$2.72
|
|
|
$3.39
|
|
|
$7.33
|
|
|
$0.00
|
Evidently AI 代替案
すべて表示
Openlayer
Openlayerは、エンタープライズ向けのAI評価およびオブザーバビリティプラットフォームです。開発から本番までのライフサイクル全体を通じて、従来の機械学習モデルと大規模言語モデル(LLM)のテスト、監視、ガバナンスをチームが実行できるよう支援し、信頼性とコンプライアンスを確保します。
Openlayerは、エンタープライズ向けのAI評価およびオブザーバビリティプラットフォームです。開発から本番までのライフサイクル全体を通じて、従来の機械学習モデルと大規模言語モデル(LLM)のテスト、監視、ガバナンスをチームが実行できるよう支援し、信頼性とコンプライアンスを確保します。
Confident AI
Confident AIは、エンジニアリングチーム向けのLLM評価およびオブザーバビリティプラットフォームです。オープンソースのDeepEvalライブラリの作成者によって構築され、包括的なメトリクス、回帰テスト、詳細なトレースを通じてLLMアプリケーションのベンチマーク、保護、改善を支援し、一貫したAIパフォーマンスを保証します。
Confident AIは、エンジニアリングチーム向けのLLM評価およびオブザーバビリティプラットフォームです。オープンソースのDeepEvalライブラリの作成者によって構築され、包括的なメトリクス、回帰テスト、詳細なトレースを通じてLLMアプリケーションのベンチマーク、保護、改善を支援し、一貫したAIパフォーマンスを保証します。
getmaxim
getmaximは、AI開発チーム向けに設計された包括的なGenAI評価およびオブザーバビリティプラットフォームです。ユーザーはLLMやRAGパイプラインの広範な評価、テストの自動化、リアルタイムのプロダクション監視を通じてAIアプリケーションをテスト、監視、改善し、高品質で信頼性が高く、責任あるAIを実現できます。
getmaximは、AI開発チーム向けに設計された包括的なGenAI評価およびオブザーバビリティプラットフォームです。ユーザーはLLMやRAGパイプラインの広範な評価、テストの自動化、リアルタイムのプロダクション監視を通じてAIアプリケーションをテスト、監視、改善し、高品質で信頼性が高く、責任あるAIを実現できます。

LangWatch
LangWatchは、LLMアプリケーションを監視、評価、最適化するためのオールインワンのオープンソースプラットフォームです。シミュレートされたユーザー環境を通じてAIエージェントのテストに特化しており、チームが本番前にリグレッションやエッジケースを検出するのに役立ちます。このプラットフォームは、可観測性、評価、最適化、ガードレールを組み合わせ、AIアプリケーションの信頼性、安全性、パフォーマンスを保証します。
LangWatchは、LLMアプリケーションを監視、評価、最適化するためのオールインワンのオープンソースプラットフォームです。シミュレートされたユーザー環境を通じてAIエージェントのテストに特化しており、チームが本番前にリグレッションやエッジケースを検出するのに役立ちます。このプラットフォームは、可観測性、評価、最適化、ガードレールを組み合わせ、AIアプリケーションの信頼性、安全性、パフォーマンスを保証します。
RagaAI
RagaAIは、開発者や企業が信頼性の高いAIアプリケーションを構築するのを支援するために設計された、包括的なAIテストおよびオブザーバビリティプラットフォームです。AIエージェント、LLM、RAGシステムを監視、評価、デバッグするための一連のツールを提供します。主な機能には、エージェントテスト、リアルタイムガードレール、合成データ生成、ファインチューニング機能が含まれます。RagaAIはマルチモーダルデータ(LLM、コンピュータビジョン、表形式データ)をサポートし、問題の検出から解決まで、AIの品質保証ライフサイクル全体を自動化し、堅牢で信頼性の高いAIの展開を目指します。
RagaAIは、開発者や企業が信頼性の高いAIアプリケーションを構築するのを支援するために設計された、包括的なAIテストおよびオブザーバビリティプラットフォームです。AIエージェント、LLM、RAGシステムを監視、評価、デバッグするための一連のツールを提供します。主な機能には、エージェントテスト、リアルタイムガードレール、合成データ生成、ファインチューニング機能が含まれます。RagaAIはマルチモーダルデータ(LLM、コンピュータビジョン、表形式データ)をサポートし、問題の検出から解決まで、AIの品質保証ライフサイクル全体を自動化し、堅牢で信頼性の高いAIの展開を目指します。
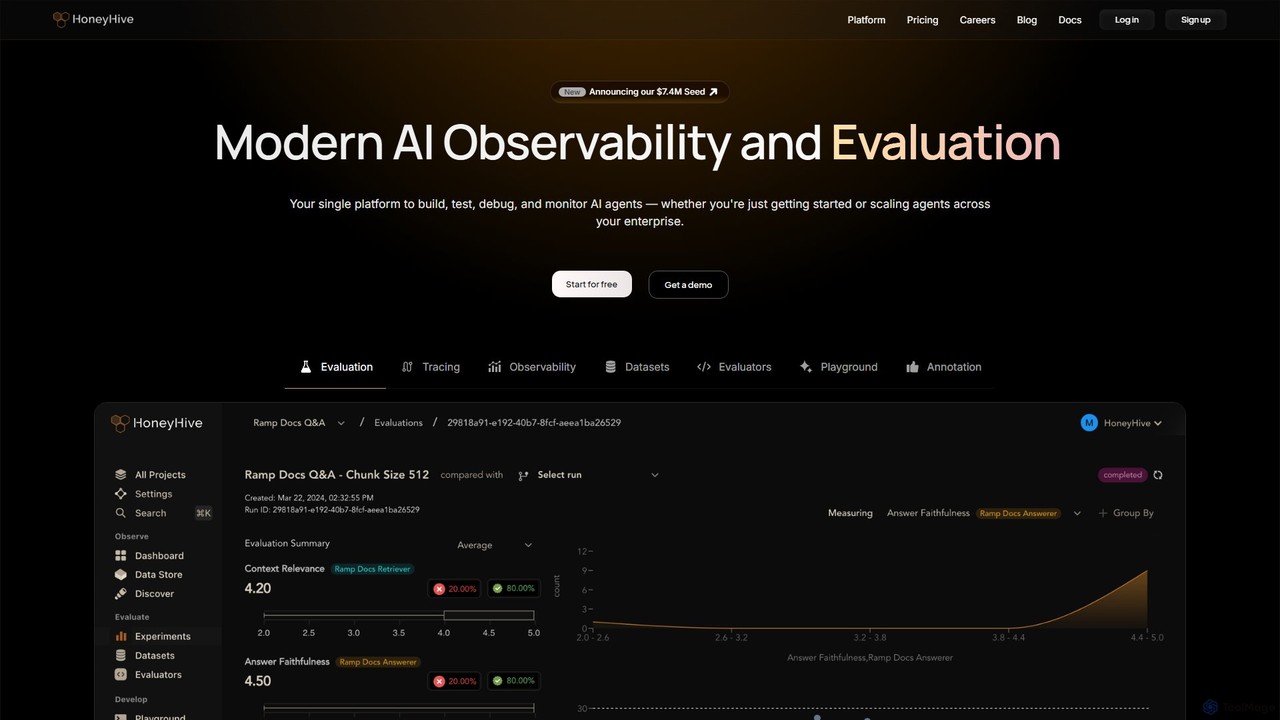
HoneyHive
HoneyHiveは、LLMとAIエージェントを構築する開発者向けのオールインワンAIオブザーバビリティ&評価プラットフォームです。初期の実験からエンタープライズ規模のデプロイまで、AIアプリケーションの構築、テスト、デバッグ、監視を行うための統一ソリューションを提供します。このプラットフォームは、チームが体系的にAIの品質を測定し、エージェントの相互作用に対する深い可視性を得て、コストやレイテンシなどのパフォーマンスメトリクスを監視し、プロンプトやデータセットなどの重要なアセットで共同作業を行うことで、信頼性の高いAI製品を自信を持って出荷できるよう支援します。
HoneyHiveは、LLMとAIエージェントを構築する開発者向けのオールインワンAIオブザーバビリティ&評価プラットフォームです。初期の実験からエンタープライズ規模のデプロイまで、AIアプリケーションの構築、テスト、デバッグ、監視を行うための統一ソリューションを提供します。このプラットフォームは、チームが体系的にAIの品質を測定し、エージェントの相互作用に対する深い可視性を得て、コストやレイテンシなどのパフォーマンスメトリクスを監視し、プロンプトやデータセットなどの重要なアセットで共同作業を行うことで、信頼性の高いAI製品を自信を持って出荷できるよう支援します。
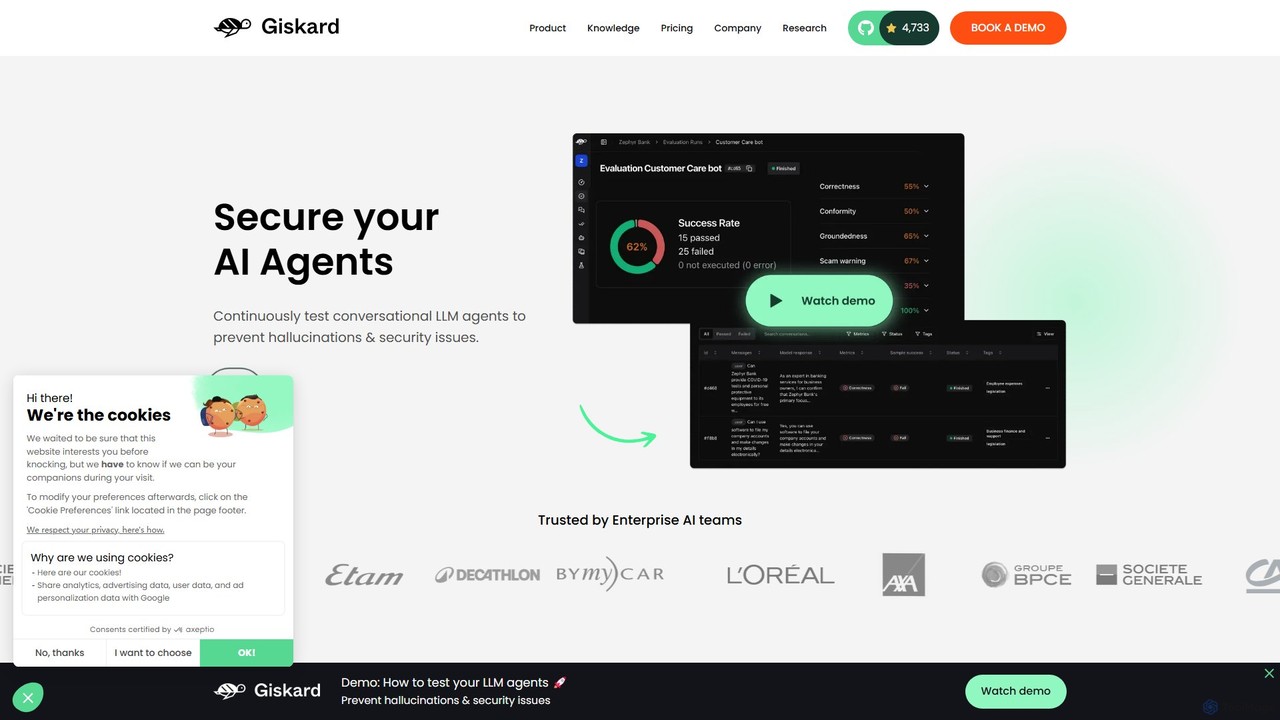
Giskard
Giskardは、LLMベースのアプリケーションを保護し、検証するために設計されたAIテストプラットフォームです。エンタープライズチームが展開前にハルシネーション、セキュリティ脆弱性、バイアス、パフォーマンス問題などのリスクを検出し、軽減するのを支援します。テスト生成の自動化と継続的なレッドチーム演習により、GiskardはAIエージェントの信頼性、安全性、コンプライアンスを保証します。
Giskardは、LLMベースのアプリケーションを保護し、検証するために設計されたAIテストプラットフォームです。エンタープライズチームが展開前にハルシネーション、セキュリティ脆弱性、バイアス、パフォーマンス問題などのリスクを検出し、軽減するのを支援します。テスト生成の自動化と継続的なレッドチーム演習により、GiskardはAIエージェントの信頼性、安全性、コンプライアンスを保証します。

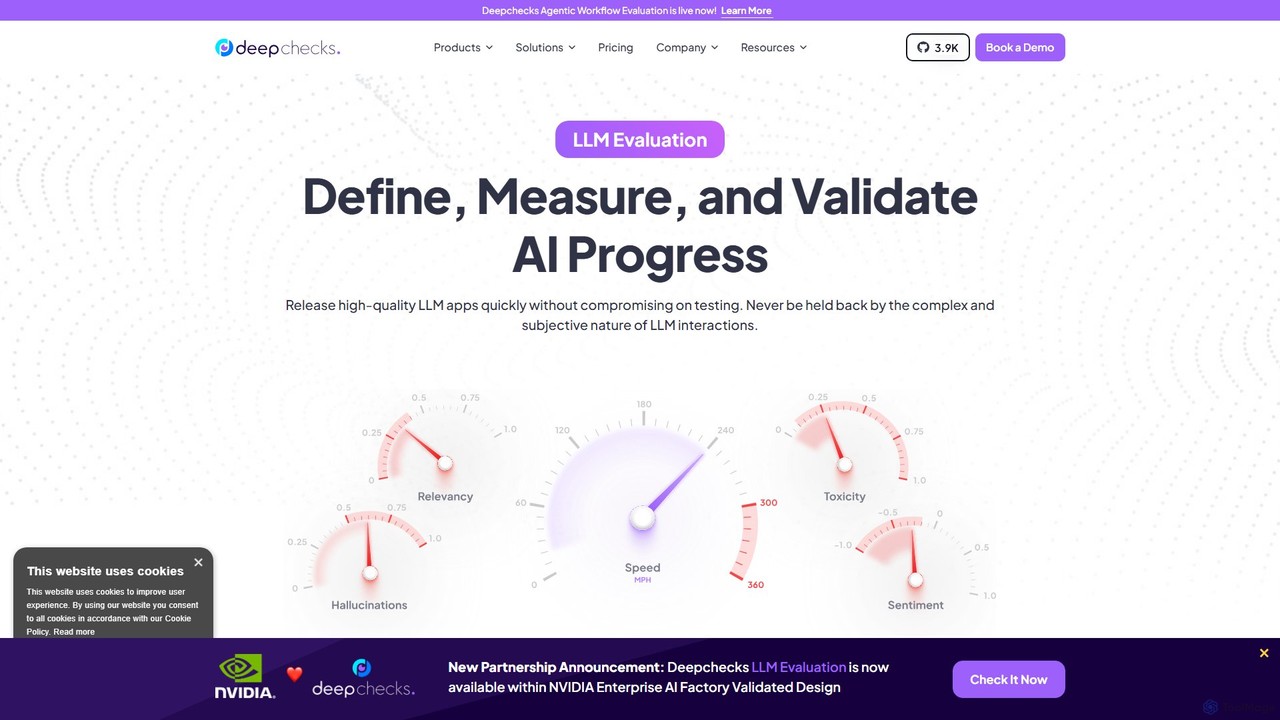
deepchecks
Deepchecksは、LLMベースのアプリケーションを評価、検証、監視するためのエンドツーエンドのプラットフォームです。AIチームがAIの進捗を定義、測定、検証するのを支援し、開発からCI/CD、本番環境までのテストを合理化することで、高品質で信頼性の高いアプリケーションのリリースを保証します。
Deepchecksは、LLMベースのアプリケーションを評価、検証、監視するためのエンドツーエンドのプラットフォームです。AIチームがAIの進捗を定義、測定、検証するのを支援し、開発からCI/CD、本番環境までのテストを合理化することで、高品質で信頼性の高いアプリケーションのリリースを保証します。
usevelvet
Velvetは、現在Arize AIの一部となっている開発者ゲートウェイで、AI搭載機能の分析、評価、監視のために設計されています。AIの可観測性、LLMの追跡、モデルのパフォーマンス管理のための包括的なスイートを提供し、開発者が開発から本番までAIアプリケーションを構築し、完成させるのを支援します。
Velvetは、現在Arize AIの一部となっている開発者ゲートウェイで、AI搭載機能の分析、評価、監視のために設計されています。AIの可観測性、LLMの追跡、モデルのパフォーマンス管理のための包括的なスイートを提供し、開発者が開発から本番までAIアプリケーションを構築し、完成させるのを支援します。
Evidently AI AIツール
Evidently AI 埋め込み機能
下の埋め込みコードをコピーし、素敵なバッジをあなたのブログ、記事、またはアプリの公式サイトに貼り付けるだけで、このツールの詳細ページに直接トラフィックを誘導し、露出とユーザー数を素早く増やすことができます!

まだコメントはありません。最初のコメントをしてみませんか!