
pdfparser 概要
pdfparserは、PDFファイル内に閉じ込められたデータのロックを解除するために設計された、専門的で高性能なツールです。高度なAIと光学文字認識(OCR)技術を活用し、非構造化PDFコンテンツを構造化された実用的なデータに変換するための、シンプルかつ強力なソリューションを提供します。ネイティブPDFやスキャンPDF、請求書、レポート、フォームなど、どのようなドキュメントを扱っていても、pdfparserは抽出プロセスを自動化し、手作業によるデータ入力の膨大な時間を節約し、人為的ミスを削減します。その主な出力はクリーンで整理されたJSONであり、開発者があらゆるアプリケーションやデータ処理パイプラインに非常に簡単に統合できるようにします。
pdfparserの使い方
pdfparserの使用は、プロジェクトへのシームレスな統合のためにAPIを介してアクセスできる、簡単なプロセスとして設計されています。
- サインアップしてクレジットを取得:pdfparserのウェブサイトでアカウントを作成し、ニーズに合ったクレジットパッケージを購入します。1クレジットは1ドキュメントの処理に相当します。
- API統合:一意のAPIキーを使用してリクエストを認証します。ドキュメントにはAPI呼び出しの明確な例が提供されています。
- PDFの送信:処理したいPDFファイルをリクエストボディに含めて、pdfparser APIエンドポイントにPOSTリクエストを送信します。
- AIによる処理:サービスのバックエンドがドキュメントを自動的に分析します。レイアウトを検出し、テキストブロックを識別し、テーブルを認識し、画像ベースのテキストにはOCRを使用します。
- 構造化JSONの受信:APIは、生のテキスト、構造化されたテーブルデータ(行と列を含む)、ドキュメントに関するメタデータを含む、抽出されたすべてのコンテンツを含む詳細なJSONオブジェクトを返します。
pdfparserの主な機能
- 高度なOCRエンジン:スキャンされたドキュメント、低解像度の画像、複雑なレイアウトからテキストを正確に抽出し、複数の言語をサポートします。
- インテリジェントなテーブル抽出:PDF内のテーブルを自動的に検出し、その構造を保持しながら、行と列をネストされたJSON配列に変換して、解析を容易にします。
- 構造化JSON出力:抽出されたすべてのデータは、データベース、アプリケーション、または分析ツールですぐに使用できるように、クリーンで予測可能で開発者に優しいJSON形式で提供されます。
- スケーラブルなAPI:開発者向けに構築された堅牢なAPIは、大量のドキュメントを処理でき、エンタープライズアプリケーションでのバッチ処理とリアルタイムのデータ抽出を可能にします。
- シンプルなクレジットベースのシステム:透明性の高い従量課金制の価格モデルにより、使用した分だけを支払うことができ、小規模プロジェクトから大規模な運用までコスト効率が高くなります。
pdfparserの使用例
pdfparserは、多くの業界で適用可能な多目的なツールです。
- 金融の自動化:請求書、発注書、領収書、銀行取引明細書からデータを自動的に抽出し、会計および簿記を合理化します。
- データサイエンスと研究:学術論文、研究レポート、PDF形式のデータセットを解析し、手作業での転記なしに分析用の情報を収集します。
- 法務とコンプライアンス:法的契約書、裁判所提出書類、規制文書から条項、事件の詳細、主要な情報を迅速に抽出します。
- 物流とサプライチェーン:船荷証券、出荷マニフェスト、納品書をデジタル化し、追跡と在庫管理を自動化します。
- 人事:履歴書や応募フォームを処理して候補者情報を抽出し、人事管理システムに入力します。
pdfparserの利点
pdfparserの主な利点は、そのシンプルさとパワーに焦点を当てていることです。PDF解析とOCRの複雑さを抽象化し、確実に機能する信頼性の高いサービスを提供します。これにより、ドキュメントデータに依存するアプリケーションの開発サイクルが大幅に短縮されます。テキストとテーブルの両方の抽出における高い精度により、手作業によるレビューと修正の必要性が最小限に抑えられます。スケーラブルなクレジットベースのモデルにより、あらゆる規模の企業が、多額の初期投資なしにエンタープライズグレードのドキュメント処理を活用できます。
料金プラン
pdfparserは、1クレジットで1ドキュメントを解析する、シンプルで分かりやすい従量課金制のクレジットシステムで運営されています。
- ライト:$1.00で10クレジット
- スタンダード:$5.00で60クレジット
- プロ:$25.00で500クレジット
支払いはカードまたはPayPalを介して安全に処理されます。この柔軟な価格設定により、アイデアをテストする開発者、ワークフローを自動化する中小企業、または大規模にドキュメントを処理する大企業にとって利用しやすくなっています。
pdfparser コメント (0)
ログインするとコメントを投稿できます
今すぐログインpdfparser 代替案
すべて表示
Finigami AI
Finigami AIは、インテリジェント・ドキュメント・プロセッシング(IDP)とカスタムAI開発を専門とする、エンタープライズ向けのAIソリューションを提供します。手書き文字や複雑な表を含むあらゆる文書からデータを抽出する強力なプラットフォームを提供し、金融、人事、運用などの部門向けに特注のAIシステムを構築するために企業と提携します。
Finigami AIは、インテリジェント・ドキュメント・プロセッシング(IDP)とカスタムAI開発を専門とする、エンタープライズ向けのAIソリューションを提供します。手書き文字や複雑な表を含むあらゆる文書からデータを抽出する強力なプラットフォームを提供し、金融、人事、運用などの部門向けに特注のAIシステムを構築するために企業と提携します。
CambioML
CambioMLは、高精度なドキュメント解析のために設計された強力なビジョンLLMであるAnyParser APIを提供します。PDF、画像、Officeドキュメントからテキスト、表、グラフ、キーバリューペアを抽出します。PII(個人識別情報)の墨消し、設定可能な出力、リアルタイム処理などの機能を備え、金融、研究、データ分析分野の開発者や企業が、プライバシーと効率を確保しながらデータ抽出ワークフローを自動化するのに最適です。
CambioMLは、高精度なドキュメント解析のために設計された強力なビジョンLLMであるAnyParser APIを提供します。PDF、画像、Officeドキュメントからテキスト、表、グラフ、キーバリューペアを抽出します。PII(個人識別情報)の墨消し、設定可能な出力、リアルタイム処理などの機能を備え、金融、研究、データ分析分野の開発者や企業が、プライバシーと効率を確保しながらデータ抽出ワークフローを自動化するのに最適です。
hand_check
hand_checkは、機械学習を用いてPDFや画像からテキストを抽出する高度なOCRツールです。手書きのメモや表などの複雑な文書を、編集可能なテキストや構造化されたJSONデータに変換することに特化しています。使いやすいインターフェースと開発者向けの強力なAPIを備え、文書処理やデータ抽出を自動化したい個人、開発者、企業に最適です。
hand_checkは、機械学習を用いてPDFや画像からテキストを抽出する高度なOCRツールです。手書きのメモや表などの複雑な文書を、編集可能なテキストや構造化されたJSONデータに変換することに特化しています。使いやすいインターフェースと開発者向けの強力なAPIを備え、文書処理やデータ抽出を自動化したい個人、開発者、企業に最適です。
Sensible
Sensibleは、開発者向けのAPIファーストのインテリジェント文書処理プラットフォームです。高度なLLM解析と視覚的なレイアウトベースのルールを使用して、PDF、画像、スプレッドシートなどのあらゆる文書から構造化データを正確に抽出します。シームレスな統合、スケーラビリティ、そしてSOC 2およびHIPAA準拠を含むエンタープライズレベルのセキュリティを実現するように設計されています。
Sensibleは、開発者向けのAPIファーストのインテリジェント文書処理プラットフォームです。高度なLLM解析と視覚的なレイアウトベースのルールを使用して、PDF、画像、スプレッドシートなどのあらゆる文書から構造化データを正確に抽出します。シームレスな統合、スケーラビリティ、そしてSOC 2およびHIPAA準拠を含むエンタープライズレベルのセキュリティを実現するように設計されています。
Monkt
Monktは、ドキュメントやウェブサイトをクリーンでAI対応のMarkdownや構造化JSONに変換するAI搭載プラットフォームです。PDF、Word、Excelなどの様々な形式をサポートし、OCR、バッチ処理、REST APIなどの機能を提供して、データ抽出を自動化し、LLMトレーニング用のデータセットを準備します。
Monktは、ドキュメントやウェブサイトをクリーンでAI対応のMarkdownや構造化JSONに変換するAI搭載プラットフォームです。PDF、Word、Excelなどの様々な形式をサポートし、OCR、バッチ処理、REST APIなどの機能を提供して、データ抽出を自動化し、LLMトレーニング用のデータセットを準備します。
Doctly
Doctlyは、PDFやその他のドキュメントからデータを正確に抽出するAI搭載ツールです。テキスト、表、図、グラフを構造化されたMarkdownやJSONに変換し、元の書式を保持します。シンプルなAPIと高精度を特徴とし、開発者や企業がドキュメント処理ワークフローを自動化するために設計されています。
Doctlyは、PDFやその他のドキュメントからデータを正確に抽出するAI搭載ツールです。テキスト、表、図、グラフを構造化されたMarkdownやJSONに変換し、元の書式を保持します。シンプルなAPIと高精度を特徴とし、開発者や企業がドキュメント処理ワークフローを自動化するために設計されています。
extracta.ai
extracta.aiは、文書や画像からインテリジェントなデータ抽出を行うために設計されたAI搭載プラットフォームです。請求書、領収書、契約書、フォームなどの様々なソースから構造化データをキャプチャするプロセスを自動化し、手作業によるデータ入力をなくし、ビジネスワークフローを効率化します。
extracta.aiは、文書や画像からインテリジェントなデータ抽出を行うために設計されたAI搭載プラットフォームです。請求書、領収書、契約書、フォームなどの様々なソースから構造化データをキャプチャするプロセスを自動化し、手作業によるデータ入力をなくし、ビジネスワークフローを効率化します。
Upstage
Upstageは、企業向けに高性能なエンタープライズグレードのAIモデルを提供します。そのスイートには、言語タスク用の強力なSolar LLM、高精度でデータを解析・抽出する高度なドキュメントAI、複雑なワークフローを自動化するための柔軟なデプロイメントオプション(API、オンプレミス、クラウド)が含まれています。
Upstageは、企業向けに高性能なエンタープライズグレードのAIモデルを提供します。そのスイートには、言語タスク用の強力なSolar LLM、高精度でデータを解析・抽出する高度なドキュメントAI、複雑なワークフローを自動化するための柔軟なデプロイメントオプション(API、オンプレミス、クラウド)が含まれています。
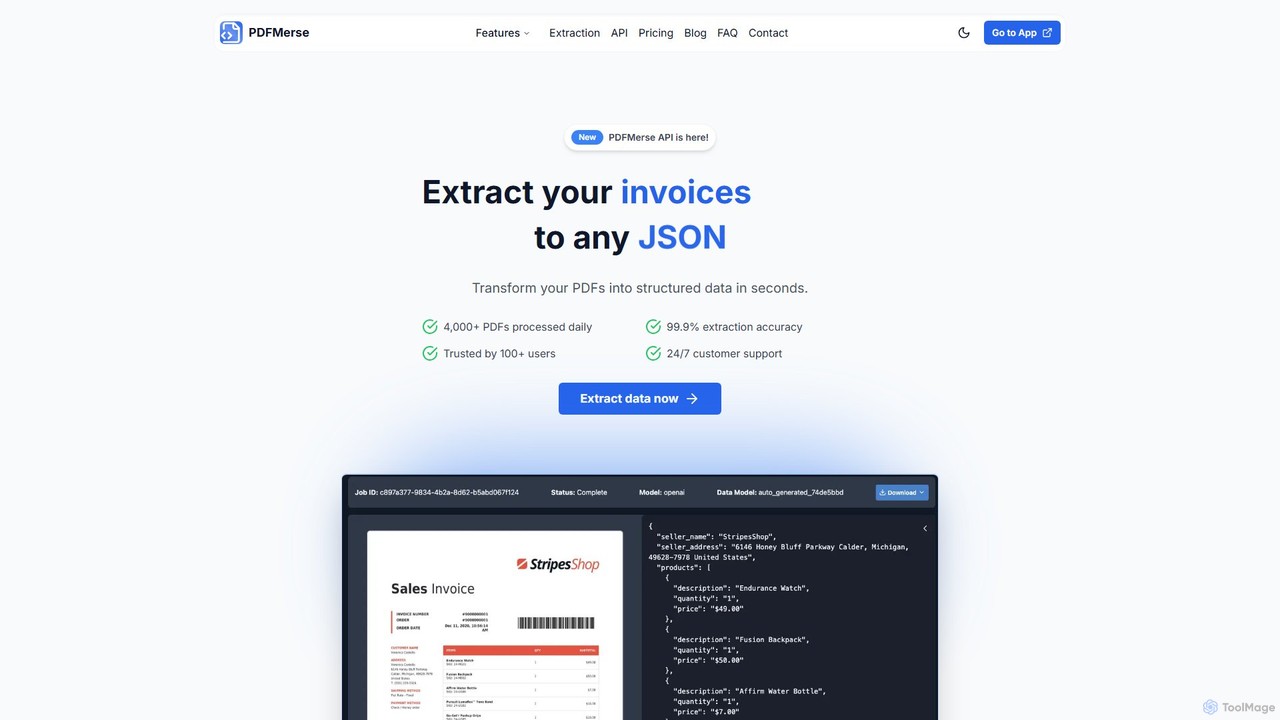
pdfmerse
pdfmerseは、あらゆるPDFドキュメントから情報を自動的にキャプチャするAI搭載のデータ抽出ツールです。非構造化PDFデータをJSONやテキストなどの構造化形式にインテリジェントに変換します。文書処理を合理化し、手作業によるデータ入力を削減し、高い精度でワークフローの効率を向上させたい企業や個人に最適です。
pdfmerseは、あらゆるPDFドキュメントから情報を自動的にキャプチャするAI搭載のデータ抽出ツールです。非構造化PDFデータをJSONやテキストなどの構造化形式にインテリジェントに変換します。文書処理を合理化し、手作業によるデータ入力を削減し、高い精度でワークフローの効率を向上させたい企業や個人に最適です。

pdfparser AIツール
pdfparser 埋め込み機能
下の埋め込みコードをコピーし、素敵なバッジをあなたのブログ、記事、またはアプリの公式サイトに貼り付けるだけで、このツールの詳細ページに直接トラフィックを誘導し、露出とユーザー数を素早く増やすことができます!

まだコメントはありません。最初のコメントをしてみませんか!