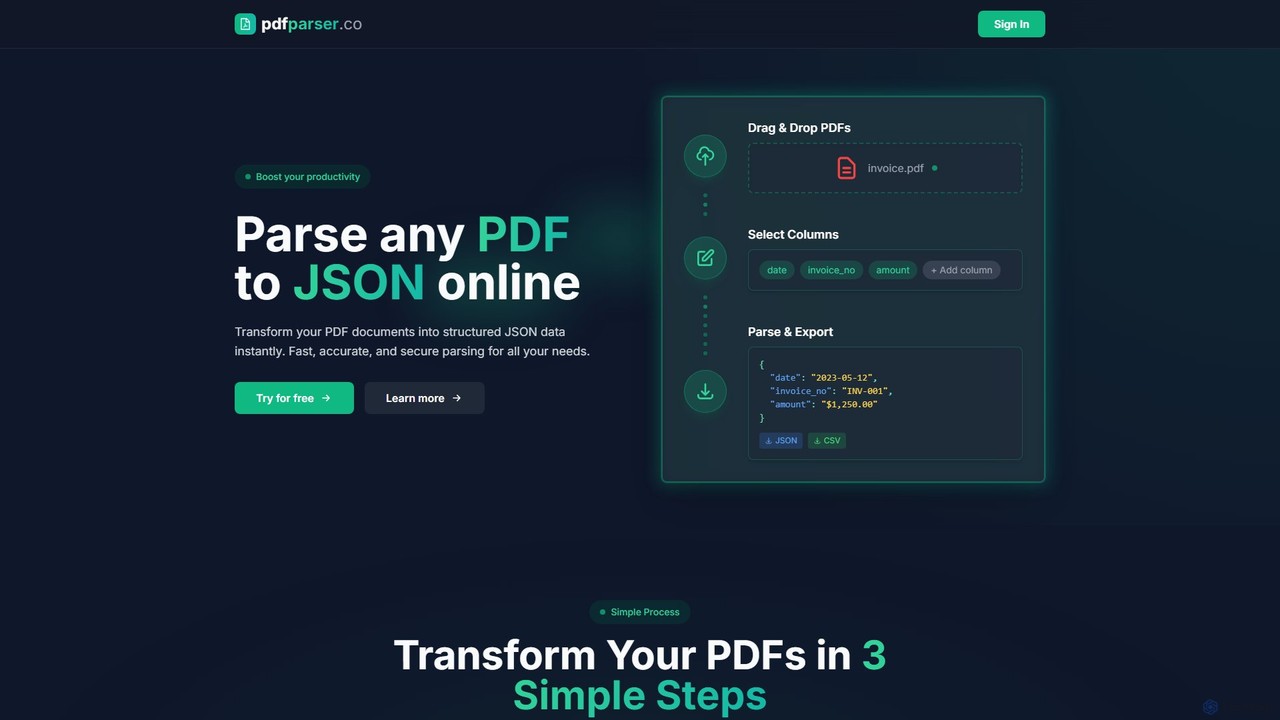
最適な総合代替
Finigami AI
Finigami AI と pdfparser はどちらも 文書処理、自動化 をカバーし、自動化、API、データ抽出 などのニーズに共通して合致するため、類似した使用シナリオを持つユーザーが優先的に比較するのに適しています。
Finigami AI が pdfparser と異なる点は、主なシナリオは 文書処理 寄りです です。
Match score: 32
月間アクセス: 2.4K