Plurai
Plurai là nền tảng niềm tin cho AI Agent, tăng tốc phát triển agent sẵn sàng đưa vào …
Plurai là nền tảng niềm tin cho AI Agent, tăng tốc phát triển agent sẵn sàng đưa vào sản xuất thông qua mô phỏng, đánh giá và guardrails. Giảm đáng kể tỷ lệ thất bại, vi phạm chính sách và chi phí so với các mô hình ngôn ngữ lớn.
Agenta
Agenta là một nền tảng LLMOps mã nguồn mở được thiết kế để các nhóm xây dựng các …
Agenta là một nền tảng LLMOps mã nguồn mở được thiết kế để các nhóm xây dựng các ứng dụng LLM đáng tin cậy. Nó tích hợp quản lý prompt, đánh giá hệ thống và khả năng quan sát vào một quy trình làm việc cộng tác duy nhất, giúp các nhà phát triển, quản lý sản phẩm và chuyên gia lĩnh vực chuyển từ các quy trình phân tán sang phát triển có cấu trúc.
Athina
Athina là một nền tảng phát triển AI hợp tác được thiết kế để giúp các nhóm xây …
Athina là một nền tảng phát triển AI hợp tác được thiết kế để giúp các nhóm xây dựng, thử nghiệm và giám sát các ứng dụng LLM nhanh hơn 10 lần. Nó cung cấp một bộ công cụ toàn diện cho kỹ thuật prompt, đánh giá, thử nghiệm, chú thích và giám sát sản xuất. Athina hỗ trợ cả người dùng kỹ thuật và phi kỹ thuật, đảm bảo sự hợp tác liền mạch và triển khai các hệ thống AI chất lượng cao, đáng tin cậy.

LangWatch
LangWatch là một nền tảng mã nguồn mở tất cả trong một để giám sát, đánh giá và …
LangWatch là một nền tảng mã nguồn mở tất cả trong một để giám sát, đánh giá và tối ưu hóa các ứng dụng LLM. Nền tảng này chuyên về kiểm thử tác nhân AI thông qua môi trường người dùng mô phỏng, giúp các nhóm phát hiện các lỗi hồi quy và các trường hợp biên trước khi đưa vào sản xuất. Nền tảng kết hợp khả năng quan sát, đánh giá, tối ưu hóa và các rào cản để đảm bảo các ứng dụng AI đáng tin cậy, an toàn và hiệu suất cao.
deepchecks
Deepchecks là một nền tảng toàn diện để đánh giá, xác thực và giám sát các ứng dụng …
Deepchecks là một nền tảng toàn diện để đánh giá, xác thực và giám sát các ứng dụng dựa trên LLM. Nó giúp các nhóm AI xác định, đo lường và xác thực tiến trình AI, đảm bảo phát hành các ứng dụng chất lượng cao, đáng tin cậy bằng cách hợp lý hóa quy trình kiểm thử từ phát triển, CI/CD đến sản xuất.
EvalsOne
EvalsOne là một nền tảng đánh giá tất cả trong một được thiết kế cho các ứng dụng …
EvalsOne là một nền tảng đánh giá tất cả trong một được thiết kế cho các ứng dụng AI tạo sinh. Nó cho phép các nhóm dễ dàng đánh giá, lặp lại và tối ưu hóa các câu lệnh LLM, quy trình RAG và các tác nhân AI thông qua một giao diện mạnh mẽ, trực quan, đảm bảo các sản phẩm AI mạnh mẽ và cạnh tranh.

Prompt Octopus
Một tiện ích mở rộng VSCode dành cho nhà phát triển để tối ưu hóa kỹ thuật prompt. …
Một tiện ích mở rộng VSCode dành cho nhà phát triển để tối ưu hóa kỹ thuật prompt. Nó cho phép so sánh song song các phản hồi từ hơn 40 LLM (như OpenAI, Anthropic, Mistral) trực tiếp trong codebase, giúp bạn tìm ra mô hình tốt nhất cho mọi tác vụ một cách hiệu quả.
usevelvet
Velvet là một cổng phát triển, hiện là một phần của Arize AI, được thiết kế để phân …
Velvet là một cổng phát triển, hiện là một phần của Arize AI, được thiết kế để phân tích, đánh giá và giám sát các tính năng do AI cung cấp. Nó cung cấp một bộ công cụ toàn diện cho khả năng quan sát AI, theo dõi LLM và quản lý hiệu suất mô hình, giúp các nhà phát triển xây dựng và hoàn thiện các ứng dụng AI từ giai đoạn phát triển đến sản xuất.

Ragas
Ragas là một framework Python mã nguồn mở để đánh giá và kiểm thử các pipeline Sinh Tăng …
Ragas là một framework Python mã nguồn mở để đánh giá và kiểm thử các pipeline Sinh Tăng cường Truy xuất (RAG). Nó cung cấp một bộ số liệu để đo lường hiệu suất của các ứng dụng LLM của bạn, từ truy xuất ngữ cảnh đến tạo câu trả lời. Được tin cậy bởi các nhà lãnh đạo ngành như LangChain và LlamaIndex, Ragas giúp các nhà phát triển xây dựng các hệ thống AI mạnh mẽ, đáng tin cậy và chính xác hơn bằng cách xác định và giảm thiểu các vấn đề như ảo giác và phản hồi không liên quan.
Keywords AI
Keywords AI là một nền tảng giám sát và quan sát LLM toàn diện được thiết kế cho …
Keywords AI là một nền tảng giám sát và quan sát LLM toàn diện được thiết kế cho các startup AI và nhà phát triển. Nó cung cấp một API thống nhất để triển khai, kiểm tra, giám sát và tối ưu hóa các quy trình làm việc LLM, hỗ trợ hơn 200 mô hình với tích hợp đơn giản chỉ bằng hai dòng mã để giúp các nhóm xây dựng và phát hành các tính năng AI đáng tin cậy nhanh hơn.
withpi.ai
Một nền tảng tập trung vào nhà phát triển để tạo ra các hệ thống chấm điểm và …
Một nền tảng tập trung vào nhà phát triển để tạo ra các hệ thống chấm điểm và đánh giá có thể điều chỉnh, nhanh chóng và tiết kiệm chi phí cho các ứng dụng AI. Nó chuyển đổi các tiêu chí định tính thành các chỉ số định lượng chính xác để giám sát mô hình, xếp hạng và tối ưu hóa RAG.
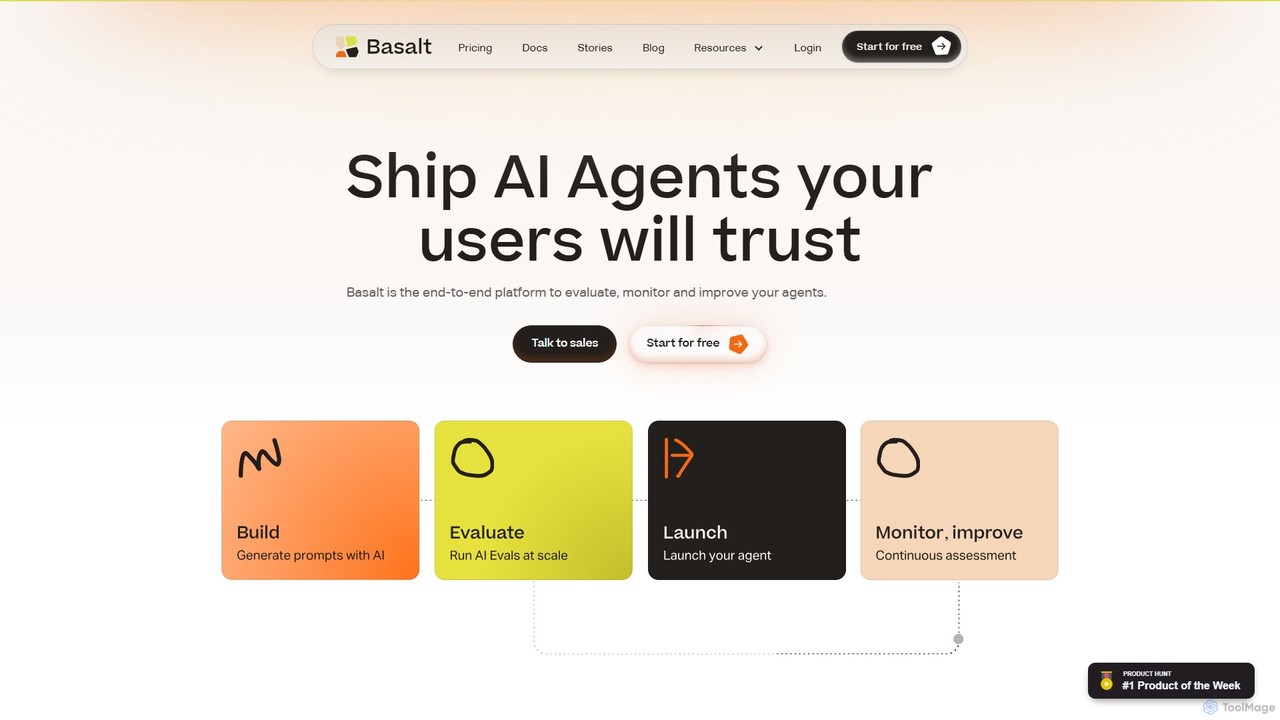
Basalt
Basalt là một nền tảng toàn diện dành cho các nhà phát triển và đội ngũ sản phẩm …
Basalt là một nền tảng toàn diện dành cho các nhà phát triển và đội ngũ sản phẩm để xây dựng, đánh giá và giám sát các tác nhân AI đáng tin cậy. Nó cung cấp một bộ công cụ toàn diện, bao gồm đánh giá tự động, thử nghiệm A/B, kỹ thuật prompt với trợ lý AI và SDK thân thiện với nhà phát triển để đảm bảo các tính năng AI của bạn đáng tin cậy và sẵn sàng cho sản xuất.
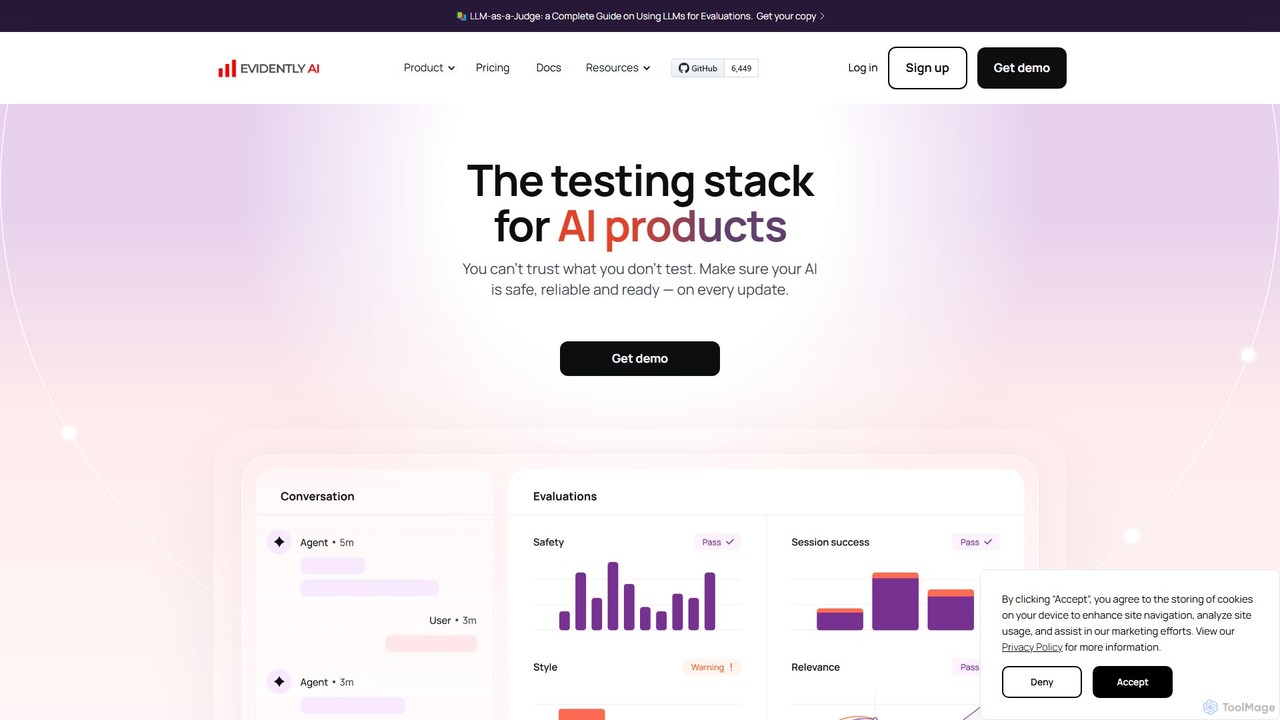
Evidently AI
Evidently AI là một nền tảng kiểm thử và đánh giá toàn diện cho các sản phẩm AI, …
Evidently AI là một nền tảng kiểm thử và đánh giá toàn diện cho các sản phẩm AI, chuyên về giám sát mô hình LLM và ML. Nó giúp các nhóm đảm bảo an toàn, độ tin cậy và hiệu suất của AI thông qua đánh giá tự động, tạo dữ liệu tổng hợp, kiểm thử liên tục và tấn công đối kháng. Được xây dựng trên một thư viện mã nguồn mở mạnh mẽ, nó được thiết kế cho các nhà khoa học dữ liệu và kỹ sư MLOps để phát hiện các vấn đề như ảo giác, trôi dạt dữ liệu và rò rỉ PII trước khi chúng ảnh hưởng đến người dùng.

Adaline
Adaline là một nền tảng đầu cuối toàn diện cho các nhóm sản phẩm và kỹ thuật để …
Adaline là một nền tảng đầu cuối toàn diện cho các nhóm sản phẩm và kỹ thuật để lặp lại, đánh giá, triển khai và giám sát các Mô hình Ngôn ngữ Lớn (LLM). Nó hợp lý hóa toàn bộ vòng đời ứng dụng AI, cho phép phát triển nhanh hơn, tăng cường hợp tác và triển khai các tính năng do AI cung cấp một cách đáng tin cậy.
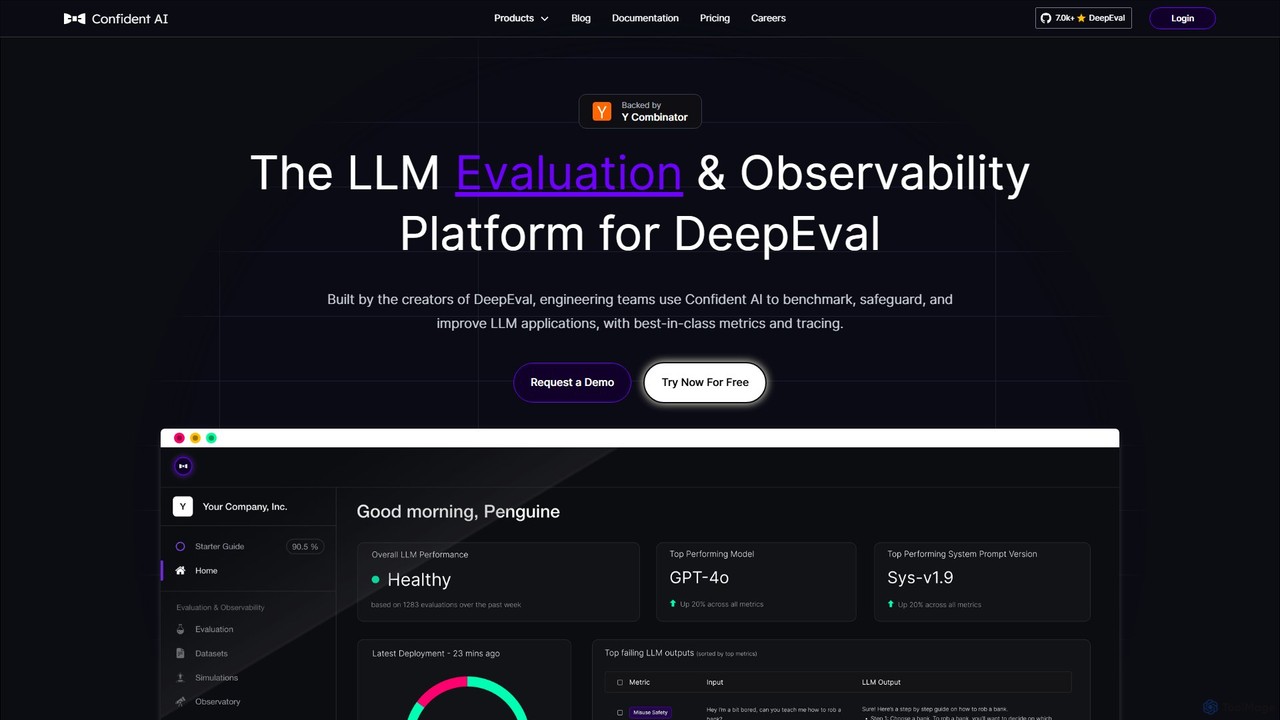
Confident AI
Confident AI là một nền tảng đánh giá và quan sát LLM dành cho các nhóm kỹ thuật. …
Confident AI là một nền tảng đánh giá và quan sát LLM dành cho các nhóm kỹ thuật. Được xây dựng bởi những người tạo ra thư viện mã nguồn mở DeepEval, nó giúp đánh giá, bảo vệ và cải thiện các ứng dụng LLM thông qua các chỉ số toàn diện, kiểm thử hồi quy và theo dõi chi tiết để đảm bảo hiệu suất AI nhất quán.
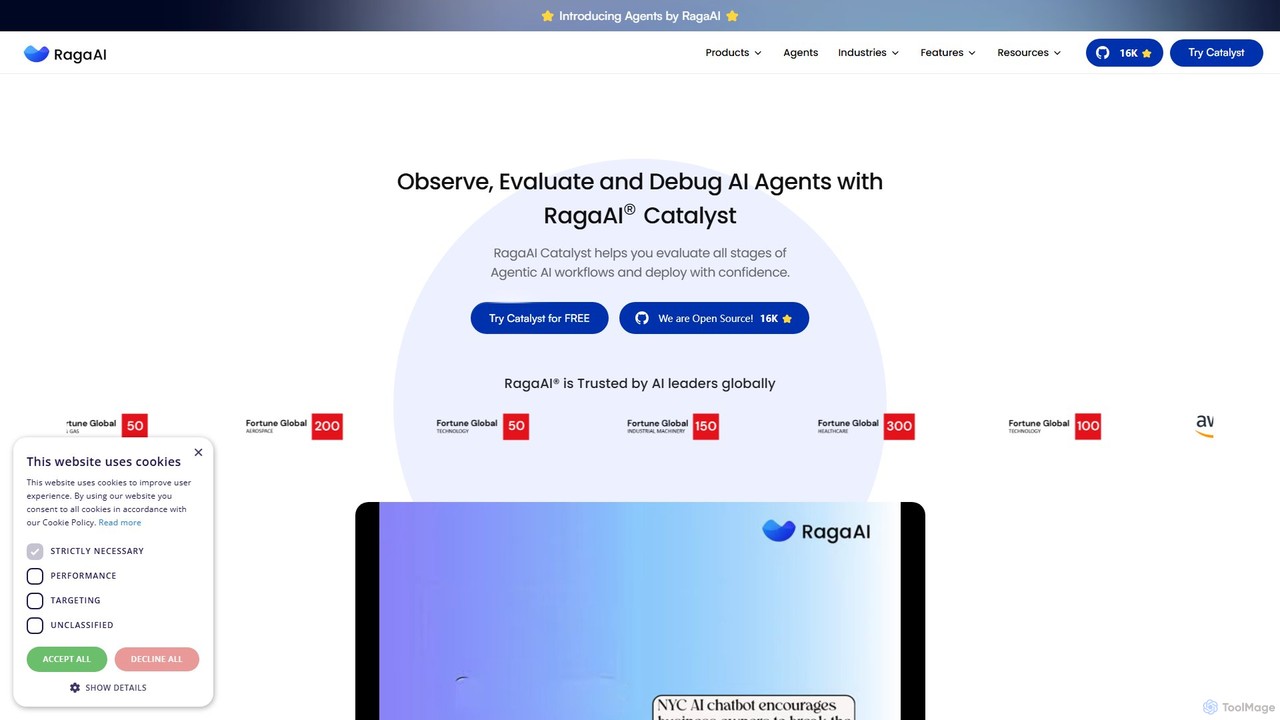
RagaAI
RagaAI là một nền tảng kiểm thử và giám sát AI toàn diện được thiết kế để giúp …
RagaAI là một nền tảng kiểm thử và giám sát AI toàn diện được thiết kế để giúp các nhà phát triển và doanh nghiệp xây dựng các ứng dụng AI đáng tin cậy. Nền tảng cung cấp một bộ công cụ để quan sát, đánh giá và gỡ lỗi các tác tử AI, LLM và hệ thống RAG. Các tính năng chính bao gồm kiểm thử tác tử, hàng rào bảo vệ thời gian thực, tạo dữ liệu tổng hợp và khả năng tinh chỉnh. RagaAI hỗ trợ dữ liệu đa phương thức (LLM, thị giác máy tính, dữ liệu dạng bảng) và nhằm mục đích tự động hóa toàn bộ vòng đời đảm bảo chất lượng AI, từ phát hiện sự cố đến giải quyết, đảm bảo triển khai AI mạnh mẽ và đáng tin cậy.
AfterQuery
AfterQuery là một phòng thí nghiệm nghiên cứu AI chuyên sâu về việc thúc đẩy các mô hình …
AfterQuery là một phòng thí nghiệm nghiên cứu AI chuyên sâu về việc thúc đẩy các mô hình nền tảng bằng cách tạo ra các bộ dữ liệu chất lượng cao do con người tạo ra và các tiêu chuẩn đánh giá không bị nhiễm bẩn. Nó tập trung vào việc cải thiện hiệu suất mô hình thông qua dữ liệu đào tạo vượt trội và đánh giá nghiêm ngặt.
promptfoo
promptfoo là một khung kiểm thử và đánh giá toàn diện cho các Mô hình Ngôn ngữ Lớn …
promptfoo là một khung kiểm thử và đánh giá toàn diện cho các Mô hình Ngôn ngữ Lớn (LLM). Nó giúp các nhà phát triển và doanh nghiệp so sánh chất lượng prompt, đánh giá hiệu suất mô hình và tăng cường bảo mật AI thông qua kiểm thử hệ thống, đo lường hiệu năng và tấn công giả lập (red teaming) do AI hỗ trợ. Nó hỗ trợ hơn 50 nhà cung cấp LLM, bao gồm cả các mô hình cục bộ, và cung cấp một CLI thân thiện với nhà phát triển để tích hợp liền mạch vào quy trình phát triển.
BenchLLM
Một framework mã nguồn mở mạnh mẽ dành cho các kỹ sư AI để đánh giá và kiểm …
Một framework mã nguồn mở mạnh mẽ dành cho các kỹ sư AI để đánh giá và kiểm thử các ứng dụng Mô hình Ngôn ngữ Lớn (LLM). BenchLLM cung cấp một API linh hoạt và CLI mạnh mẽ để xây dựng các bộ kiểm thử, tạo báo cáo chất lượng và tích hợp việc đánh giá mô hình vào quy trình CI/CD, đảm bảo kết quả có thể dự đoán và chất lượng cao.
getmaxim
getmaxim là một nền tảng đánh giá và quan sát GenAI toàn diện được thiết kế cho các …
getmaxim là một nền tảng đánh giá và quan sát GenAI toàn diện được thiết kế cho các nhóm phát triển AI. Nó cho phép người dùng kiểm tra, giám sát và cải thiện các ứng dụng AI bằng cách chạy các đánh giá sâu rộng trên LLM và các pipeline RAG, tự động hóa kiểm thử và cung cấp giám sát sản xuất thời gian thực để đảm bảo AI chất lượng cao, đáng tin cậy và có trách nhiệm.
Giskard
Giskard là một nền tảng kiểm thử AI được thiết kế để bảo mật và xác thực các …
Giskard là một nền tảng kiểm thử AI được thiết kế để bảo mật và xác thực các ứng dụng dựa trên LLM. Nó giúp các nhóm doanh nghiệp phát hiện và giảm thiểu các rủi ro như ảo giác, lỗ hổng bảo mật, thiên vị và các vấn đề về hiệu suất trước khi triển khai. Bằng cách tự động hóa việc tạo thử nghiệm và cho phép kiểm thử đối kháng (red teaming) liên tục, Giskard đảm bảo các tác nhân AI đáng tin cậy, an toàn và tuân thủ.