Helicone
Helicone 是一个为开发者提供的开源平台,集成了 AI 网关和 LLM 可观测性功能。它通过提供路由、监控、调试和分析 LLM 使用情况的工具,帮助构建可靠的 AI 应用程序。主要功能包括支持100多种模型的统一 API、智能缓存、速率限制、提示词管理和详细的性能分析。
Helicone 是一个为开发者提供的开源平台,集成了 AI 网关和 LLM 可观测性功能。它通过提供路由、监控、调试和分析 LLM 使用情况的工具,帮助构建可靠的 AI 应用程序。主要功能包括支持100多种模型的统一 API、智能缓存、速率限制、提示词管理和详细的性能分析。
Outoftheblue
Outoftheblue 是一款专为 D2C 品牌打造的 AI 驱动的电商可观测性平台。它能实时监控超过100个广告和网站信号,即时提醒企业注意影响收入的问题,如像素损坏、结账失败和广告支出效率低下等。这种主动式方法帮助品牌保护广告支出回报率(ROAS)、提高转化率并自信地实现规模化增长。
Outoftheblue 是一款专为 D2C 品牌打造的 AI 驱动的电商可观测性平台。它能实时监控超过100个广告和网站信号,即时提醒企业注意影响收入的问题,如像素损坏、结账失败和广告支出效率低下等。这种主动式方法帮助品牌保护广告支出回报率(ROAS)、提高转化率并自信地实现规模化增长。
Simple Analytics
Simple Analytics 是一款将隐私放在首位的 Google Analytics 替代品。它提供简洁明了的仪表盘和强大的洞察力,且无需使用 cookie 或收集个人数据。其突出特点是其 AI 助手,让您能通过与分析数据聊天来即时获得答案。该工具总部位于欧盟,完全符合 GDPR,提供尊重访问者并提升网站速度的准确、轻量级追踪。
Simple Analytics 是一款将隐私放在首位的 Google Analytics 替代品。它提供简洁明了的仪表盘和强大的洞察力,且无需使用 cookie 或收集个人数据。其突出特点是其 AI 助手,让您能通过与分析数据聊天来即时获得答案。该工具总部位于欧盟,完全符合 GDPR,提供尊重访问者并提升网站速度的准确、轻量级追踪。
drdroid
drdroid 是一款面向 SRE 和 DevOps 团队的、由 AI 驱动的可观测性与生产监控代理。它通过查询和分析来自多个来源的日志和指标来自动进行事件调查。通过 Slack 与您现有的技术栈集成,它能帮助减少警报疲劳,大幅缩短 MTTR(平均解决时间),并将运行手册转变为自愈系统,充当一个全天候的 AI SRE。
drdroid 是一款面向 SRE 和 DevOps 团队的、由 AI 驱动的可观测性与生产监控代理。它通过查询和分析来自多个来源的日志和指标来自动进行事件调查。通过 Slack 与您现有的技术栈集成,它能帮助减少警报疲劳,大幅缩短 MTTR(平均解决时间),并将运行手册转变为自愈系统,充当一个全天候的 AI SRE。

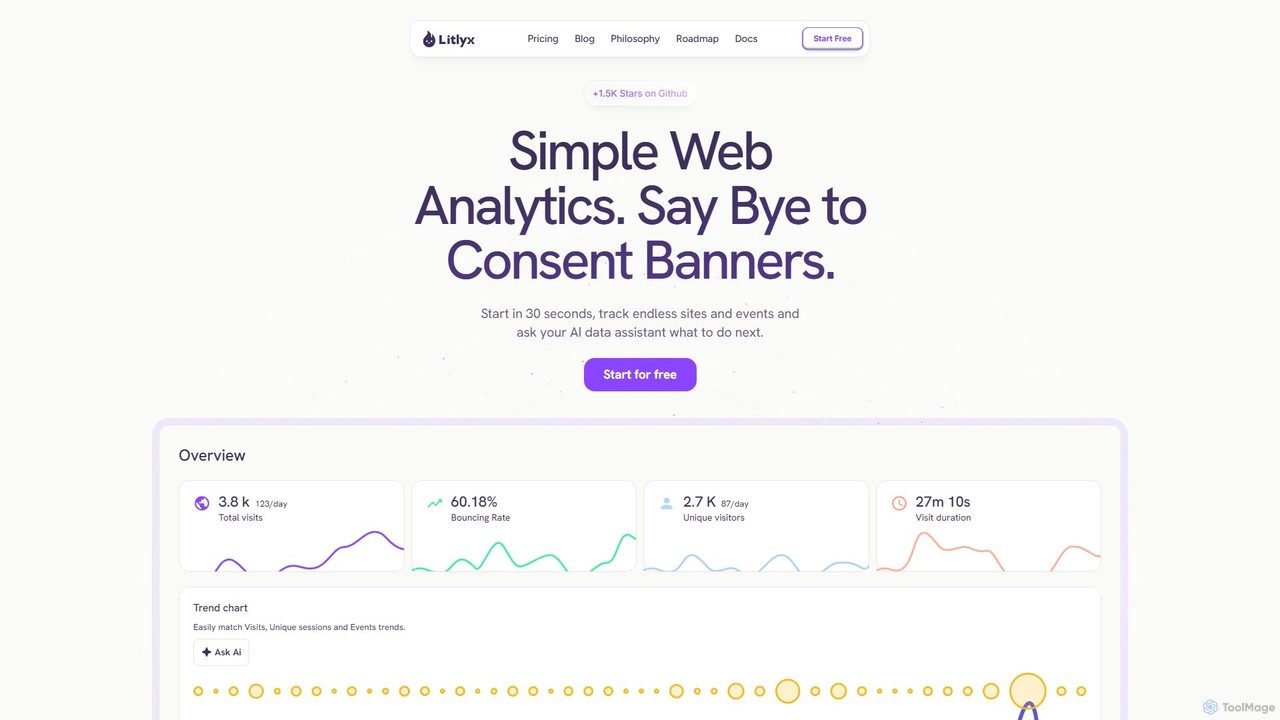
Seline
Seline 是一款注重隐私、轻量级且用户友好的网站和产品分析平台。作为 Google Analytics 的无 Cookie 替代品,它通过直观的仪表盘、访客旅程跟踪、转化漏斗和 AI 聊天功能提供实时洞察。Seline 专为简化和性能而设计,帮助企业、SaaS 公司和电子商务商店了解用户行为,同时不影响隐私或网站速度。它符合 GDPR 标准,并且可在几分钟内轻松集成。
Seline 是一款注重隐私、轻量级且用户友好的网站和产品分析平台。作为 Google Analytics 的无 Cookie 替代品,它通过直观的仪表盘、访客旅程跟踪、转化漏斗和 AI 聊天功能提供实时洞察。Seline 专为简化和性能而设计,帮助企业、SaaS 公司和电子商务商店了解用户行为,同时不影响隐私或网站速度。它符合 GDPR 标准,并且可在几分钟内轻松集成。
hawkflow.ai
HawkFlow.ai 是一个为开发人员和技术负责人设计的统一监控平台。它允许您在一个集中的地方跟踪应用程序性能、基础设施、数据、KPI 和机器学习模型。通过简单的代码集成,它帮助团队主动识别问题、监控成本,并全面了解其整个技术堆栈。
HawkFlow.ai 是一个为开发人员和技术负责人设计的统一监控平台。它允许您在一个集中的地方跟踪应用程序性能、基础设施、数据、KPI 和机器学习模型。通过简单的代码集成,它帮助团队主动识别问题、监控成本,并全面了解其整个技术堆栈。
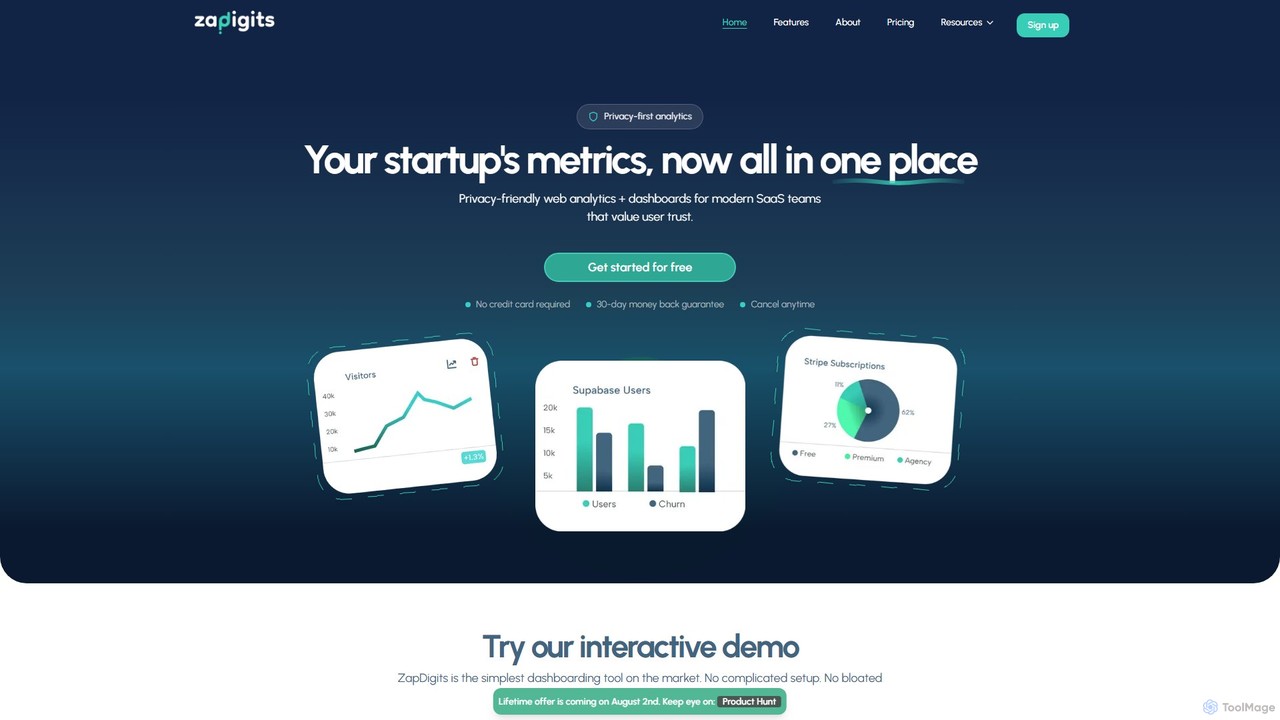
ZapDigits
ZapDigits 是一款优先考虑隐私的分析和仪表板工具,专为初创公司和 SaaS 团队设计。它将来自 Stripe、Supabase 和 GitHub 等各种服务的关键指标整合到一个简单易懂的仪表板中。通过无代码设置,它提供了清晰、可操作的见解,无需传统商业智能工具的复杂性,帮助创始人节省时间并做出数据驱动的决策。
ZapDigits 是一款优先考虑隐私的分析和仪表板工具,专为初创公司和 SaaS 团队设计。它将来自 Stripe、Supabase 和 GitHub 等各种服务的关键指标整合到一个简单易懂的仪表板中。通过无代码设置,它提供了清晰、可操作的见解,无需传统商业智能工具的复杂性,帮助创始人节省时间并做出数据驱动的决策。
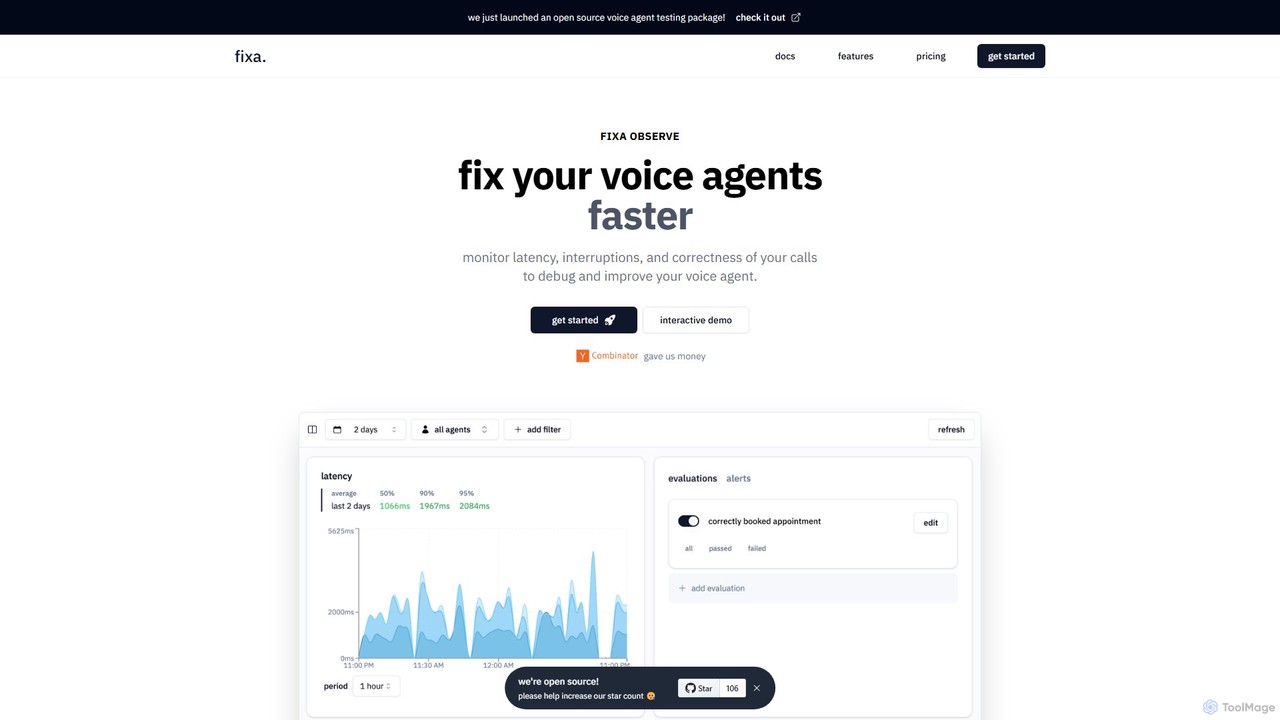
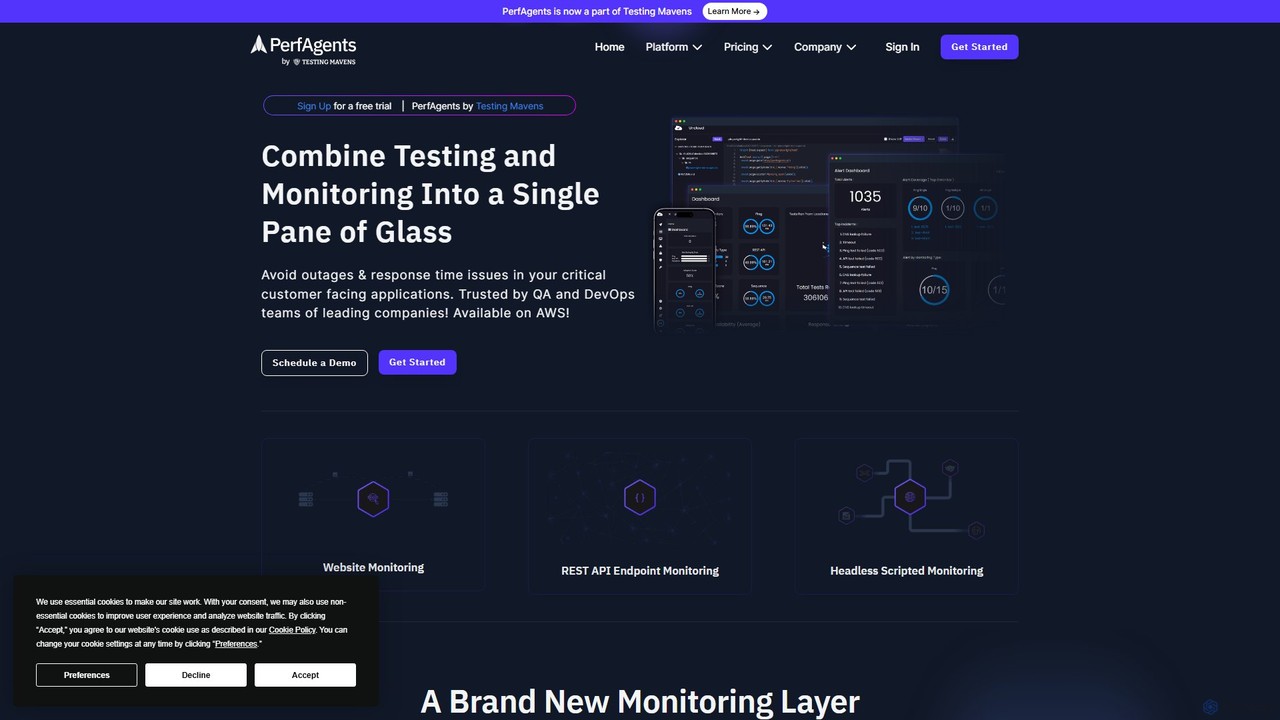
PerfAgents
PerfAgents 是一个专为 QA 和 DevOps 团队设计的 AI 驱动的综合监控平台。它利用 Playwright、Selenium 和 Cypress 等框架的现有测试脚本,或使用自然语言生成新脚本,从全球各地持续监控网站和 API 的性能、可用性以及关键用户流程。
PerfAgents 是一个专为 QA 和 DevOps 团队设计的 AI 驱动的综合监控平台。它利用 Playwright、Selenium 和 Cypress 等框架的现有测试脚本,或使用自然语言生成新脚本,从全球各地持续监控网站和 API 的性能、可用性以及关键用户流程。
关于 监控
AI监控工具是一类专业的开发者工具,利用机器学习来分析和解读系统健康状况、性能及运营数据。与依赖预定义阈值的传统系统不同,这些工具能自动检测异常、识别日志和指标中的复杂模式,并在问题影响用户前预测潜在故障。它们提供关于应用程序行为的深度、可行的洞察,显著缩短平均解决时间(MTTR),并简化对复杂分布式架构的管理。这种主动方法对于维护现代软件环境的可靠性至关重要。
核心功能
- 异常检测:无需手动设置规则,自动识别指标、日志和追踪中偏离基线性能的异常波动。
- AI驱动的根因分析(RCA):关联整个技术栈中不同事件和数据点,精确定位问题的可能来源。
- 预测性分析:预测未来趋势,如资源消耗或错误率,从而在故障发生前进行预防。
- 日志模式识别:对海量非结构化日志数据进行聚类,自动发现新出现的错误和未知问题。
- 智能告警与降噪:将相关告警分组为单一事件,并抑制低优先级通知,以解决告警疲劳问题。
适用场景
这些工具对于站点可靠性工程师(SRE)、DevOps团队以及管理云原生应用、微服务和Kubernetes环境的开发人员至关重要。它们在高速CI/CD流水线中用于检测性能衰退,以及在监控手动分析不可行的大规模系统时尤其有价值。任何追求高可用性和快速事件响应的组织都能从AI驱动的监控中受益。
选择要点
选择AI监控工具时,应评估其与现有技术栈(如AWS、Azure、Kubernetes)的集成能力。考察其支持的数据类型(日志、指标、追踪、事件)及其机器学习模型的成熟度。此外,还需考虑实施的简易性、可视化和根因分析报告的清晰度,以及一个与您的数据量和增长相匹配的定价模型。
监控应用场景
为电商平台主动预防服务中断
一个大型电商平台的SRE团队使用AI监控工具为“黑色星期五”促销活动做准备。该工具分析历史性能数据,并预测300%的流量高峰可能会导致数据库连接池耗尽。基于这一预测性警报,团队在促销开始前两小时主动扩展了数据库副本并调整了连接限制。最终,平台在没有任何性能下降或停机的情况下处理了峰值负载,保障了数百万的收入并维持了客户信任。
微服务中的自动化根因分析
一位开发人员收到警报,称一个基于微服务的应用程序中的结账流程变慢。他们没有手动检查数十个服务的日志,而是查阅了他们的AI监控工具。该工具的服务地图可视化了整个交易流程,并自动高亮显示了一个延迟异常高的特定“支付网关”服务。它将此延迟峰值与最近的代码部署以及该服务错误日志的激增关联起来,在五分钟内确定了根本原因。这使开发人员能够立即回滚有问题的部署,迅速恢复服务。
用于安全异常检测的智能日志分析
一个安全运营团队使用AI监控工具来分析来自其整个基础设施的身份验证日志。该工具的机器学习模型在基线活动上进行了训练,检测到一个新的模式:一系列来自地理位置异常的IP范围的成功登录,目标是非关键服务,随后是失败的提权尝试。这种微妙的模式没有触发任何单一的基于阈值的警报。AI工具将其标记为高风险异常,使安全团队能够在恶意行为者破坏敏感系统之前进行调查并阻止他们。
利用AI洞察优化云资源成本
一个DevOps团队的任务是减少公司的月度云账单。他们部署了一个AI监控工具,该工具分析了数百台虚拟机上的资源利用率(CPU、内存、网络)。该工具识别出一个服务器集群,即使在高峰时段,其CPU利用率也持续低于10%。它建议将这些实例降级为更具成本效益的机器类型。通过遵循这个由AI驱动的建议,团队在不影响应用程序性能的情况下将云支出减少了18%,直接为公司的利润做出了贡献。
在CI/CD流水线中检测性能衰退
一个软件开发团队将他们的AI监控工具与CI/CD流水线集成。在新功能合并后,自动化测试套件运行。监控工具分析此构建的性能指标,并将其与先前成功构建的动态基线进行比较。它自动标记出一个关键端点的API响应时间增加了20%,尽管所有功能测试都已通过。这使团队能够在代码部署到生产环境之前捕获性能衰退,从而防止对用户体验产生负面影响。
为移动应用后端团队减少告警疲劳
一个流行移动应用的后端小团队每天收到超过500条警报,其中大部分是来自临时网络波动的噪音。他们实施了一个具有智能告警功能的AI监控工具。该工具学习了正常模式,并开始自动将相关的、不稳定的警报分组为单一事件。例如,在一次短暂的网络故障期间,来自不同服务器的20个单独的“高延迟”警报被整合为一个标题为“在EU-West-1区域检测到瞬时网络延迟”的事件。这使他们的每日警报量减少了90%以上,让他们能够只专注于真实、可操作的问题。