BlickState
BlickState 是一款先进的 AI 代理时空旅行调试工具,使开发者能够在 AI 代理工具执行失败的精确毫秒点恢复并检查完整的内存状态。它将黑盒式的代理行为转化为透明、可检查的过程,显著加速了 AI 工程师的调试效率。
BlickState 是一款先进的 AI 代理时空旅行调试工具,使开发者能够在 AI 代理工具执行失败的精确毫秒点恢复并检查完整的内存状态。它将黑盒式的代理行为转化为透明、可检查的过程,显著加速了 AI 工程师的调试效率。
Middleware
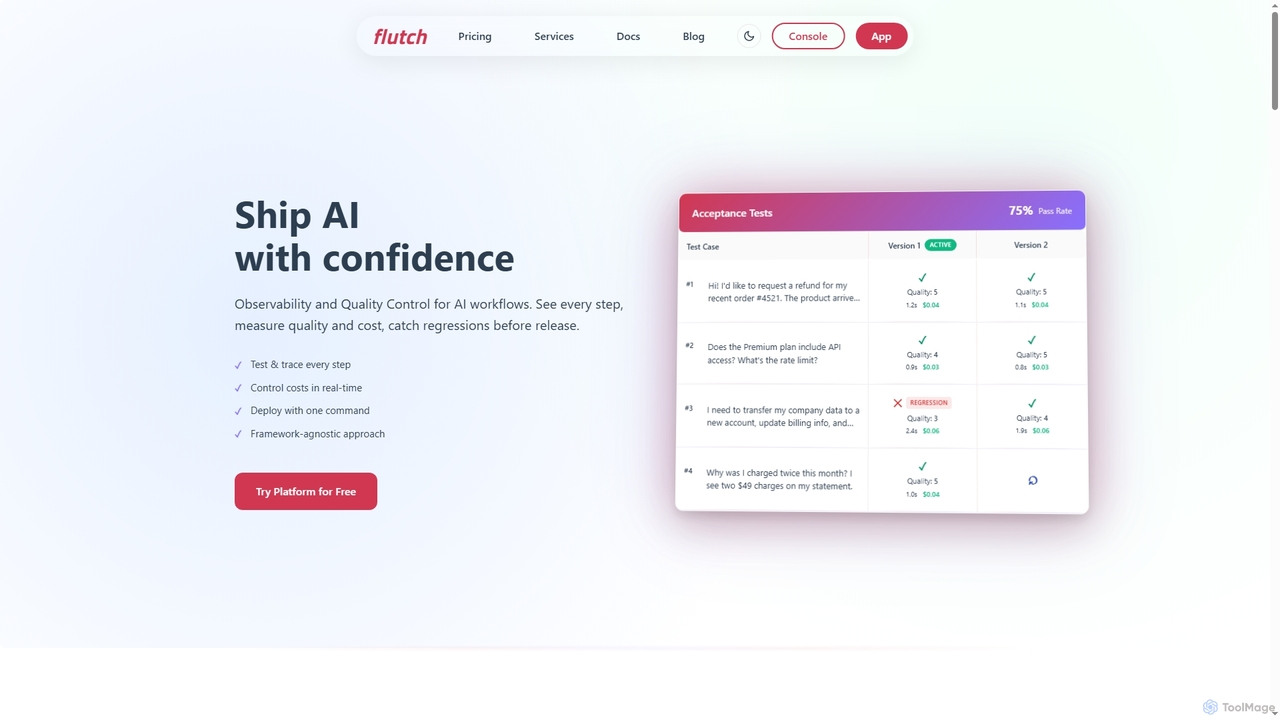
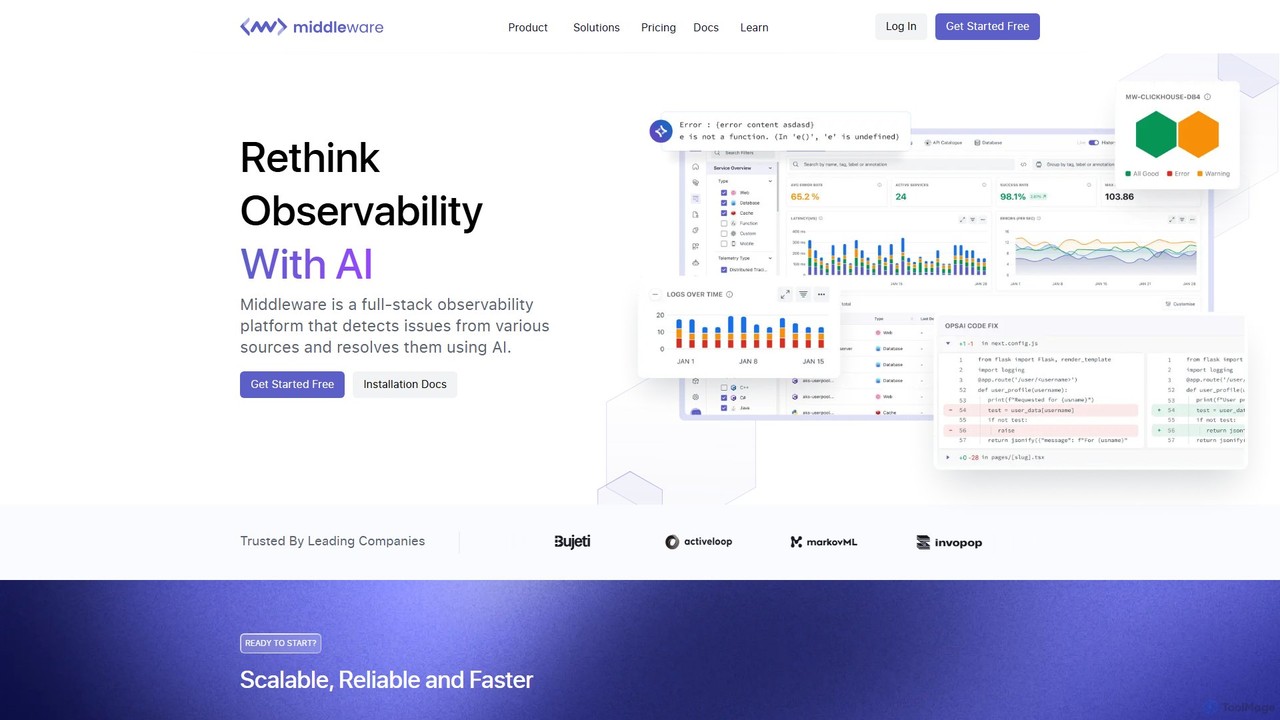
Middleware 是一个由人工智能驱动的全栈云可观测性平台,旨在实现 IT 基础设施的现代化。它将日志、指标、追踪和 RUM 数据统一到一个视图中,使团队能够实时监控其整个技术栈。借助其核心功能 OpsAI,Middleware 可自动检测、诊断甚至解决高达 70% 的问题,从而显著缩短解决时间并提高开发人员的生产力。它为各种规模的企业提供了经济高效、可扩展的解决方案。
Middleware 是一个由人工智能驱动的全栈云可观测性平台,旨在实现 IT 基础设施的现代化。它将日志、指标、追踪和 RUM 数据统一到一个视图中,使团队能够实时监控其整个技术栈。借助其核心功能 OpsAI,Middleware 可自动检测、诊断甚至解决高达 70% 的问题,从而显著缩短解决时间并提高开发人员的生产力。它为各种规模的企业提供了经济高效、可扩展的解决方案。
OpenLIT
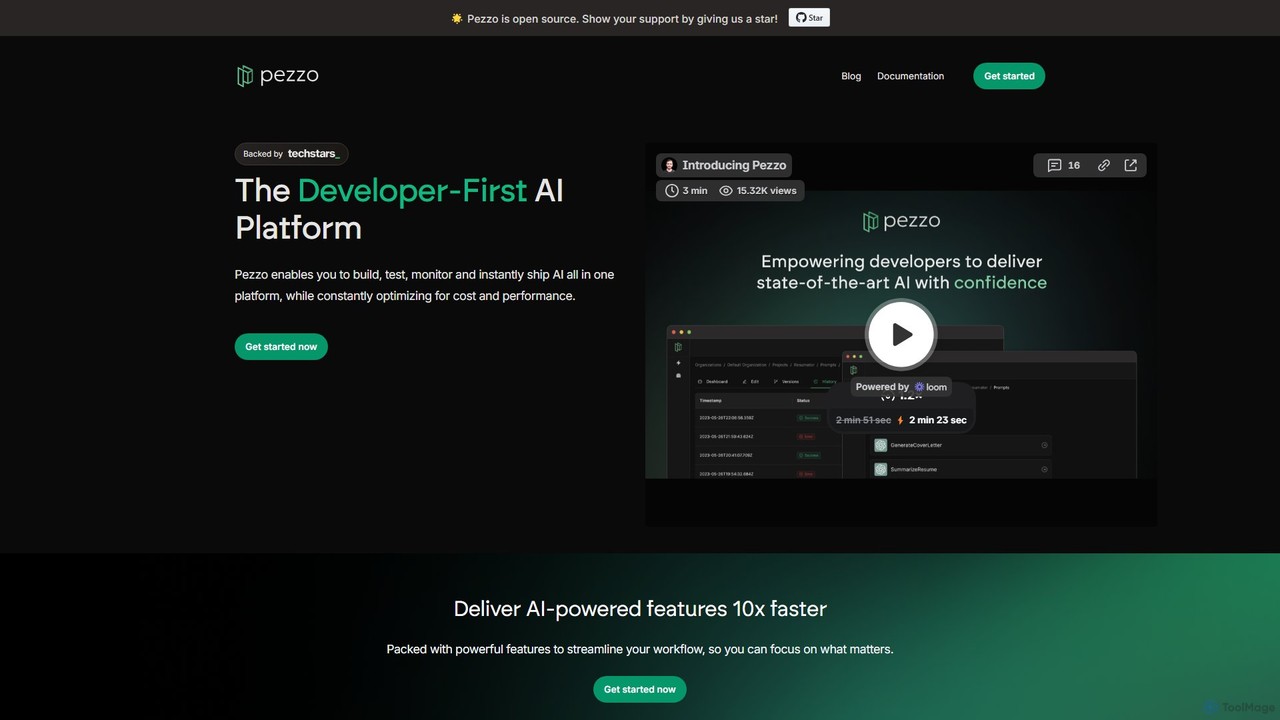
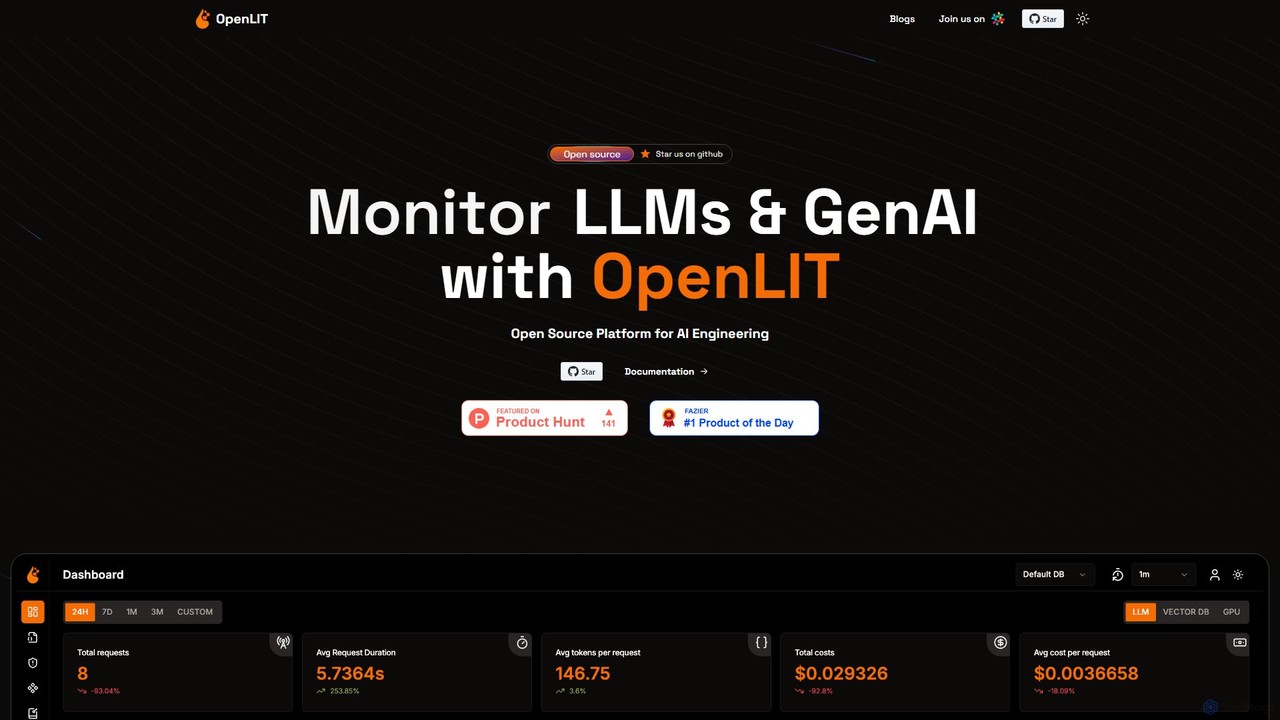
OpenLIT 是一个专为生成式 AI 和 LLM 应用设计的开源、OpenTelemetry 原生可观测性平台。它通过请求追踪、成本跟踪、异常监控和性能分析等工具简化了开发流程。OpenLIT 拥有集中的提示词仓库、用于存储密钥的安全保管库以及用于比较 LLM 的实验场,为高效监控和扩展 AI 应用提供了全面的解决方案。
OpenLIT 是一个专为生成式 AI 和 LLM 应用设计的开源、OpenTelemetry 原生可观测性平台。它通过请求追踪、成本跟踪、异常监控和性能分析等工具简化了开发流程。OpenLIT 拥有集中的提示词仓库、用于存储密钥的安全保管库以及用于比较 LLM 的实验场,为高效监控和扩展 AI 应用提供了全面的解决方案。

关于 可观测性
可观测性工具是一类利用AI技术,旨在深入洞察复杂软件系统内部状态与行为的解决方案。通过收集和分析指标、日志和追踪数据,这些工具使开发和运维团队能够理解问题发生的根本原因,预测潜在风险,并优化系统性能。它们对于维护现代应用程序的可靠性、效率和弹性至关重要,尤其是在分布式和云原生环境中。
核心功能
- 自动化数据摄取:自动从各种来源(应用程序、基础设施、服务)收集指标、日志和追踪数据。
- 实时监控与告警:提供仪表盘用于实时系统健康可视化,并在异常或预设阈值时触发告警。
- 分布式追踪:追踪跨多个服务的请求,以查明微服务架构中的延迟瓶颈和故障点。
- 日志管理与分析:集中、索引和分析海量日志数据,用于故障排除和安全审计。
- AI驱动的异常检测:利用机器学习识别系统行为中可能预示潜在问题的异常模式。
适用场景
可观测性工具对于管理生产系统的SRE、DevOps工程师和开发人员来说不可或缺。它们用于快速诊断应用程序错误的根本原因,监控微服务性能,并确保服务水平目标(SLO)的达成。例如,DevOps团队可能使用这些工具在新部署后识别特定服务中的内存泄漏,或理解用户请求在多个后端组件中为何出现高延迟。
选择要点
选择可观测性工具时,需考虑其数据收集能力(指标、日志、追踪)、与现有技术栈的集成度,以及处理不断增长数据量的可扩展性。评估其实时分析和可视化功能,包括可定制的仪表盘和告警机制。同时,还要评估其AI驱动的异常检测和根因分析能力,以及基于数据摄取和保留的定价模式。
可观测性应用场景
更快地诊断生产事故
站点可靠性工程师(SRE)利用可观测性平台快速查明关键生产问题的根本原因。通过关联分布式服务中的指标、日志和追踪数据,他们可以迅速识别出哪个特定组件正在失效或性能下降,从而缩短平均解决时间(MTTR),并最大程度地减少最终用户的停机时间。
优化微服务性能
开发人员和DevOps团队利用分布式追踪来可视化复杂微服务架构中完整的请求流。这使他们能够识别延迟瓶颈、低效的数据库查询或服务间缓慢的API调用,从而实现有针对性的优化,以提高整体应用程序响应速度和用户体验。
主动异常检测
运维团队部署AI驱动的可观测性工具,自动检测系统行为中的异常模式,这些模式可能预示着即将发生的问题。例如,特定API错误率的突然飙升或吞吐量的意外下降,可以在影响用户之前被标记出来,从而实现主动干预并防止服务中断。
确保合规性和安全审计
安全和合规官员利用集中式日志管理功能,收集、存储和分析所有系统组件的审计日志。这提供了全面的活动轨迹,有助于检测未经授权的访问尝试,调查安全事件,并证明符合GDPR或HIPAA等法规要求。
容量规划与资源管理
基础设施工程师利用可观测性工具收集的历史性能指标,了解资源利用趋势(CPU、内存、网络)。这些数据为容量规划提供战略决策依据,确保有足够的资源来处理高峰负载,同时避免过度配置和不必要的基建成本。
验证新部署和功能
开发团队将可观测性集成到其CI/CD管道中,以实时监控新代码部署或功能发布的影响。通过在发布后立即观察关键绩效指标(KPI)和错误率,他们可以快速识别回归或意外行为,并在必要时启动回滚,确保稳定的发布。