
Fireworks AI 概览
Fireworks AI 是一个尖端的开发者平台,旨在以无与伦比的速度和效率构建、定制和扩展生成式AI应用。它将自己定位为最快的推理平台,使开发者和企业能够仅用几行代码就运行和微调Llama、Mistral、DeepSeek和Qwen等开源AI模型。该平台建立在高度优化的推理引擎FireAttention之上,可提供实时性能、最低延迟和高吞吐量,是任务关键型应用的理想选择。Fireworks AI 消除了GPU管理的复杂性,让用户可以专注于构建创新的AI产品。
如何使用Fireworks AI
对于开发者来说,使用Fireworks AI的流程非常简化。首先,您在其网站上注册以获取平台访问权限并获得初始免费额度。然后,您可以使用其直观的SDK或直接进行API调用,开始对数百个预支持的开源模型进行实验。该平台与OpenAI兼容,使迁移变得容易。对于自定义需求,您可以使用监督式微调(SFT)或强化学习微调(RFT)等先进技术上传您的数据来微调模型。模型准备就绪后,您可以使用灵活的部署选项之一进行部署:Serverless(无服务器)模式,按令牌付费,无冷启动,使用简单;或On-Demand Deployments(按需部署),提供专用的GPU资源,具有更高的速率限制和更大规模下的更低成本。
Fireworks AI的核心功能
- 极速推理引擎: 由专有的FireAttention引擎驱动,提供业界领先的速度、低延迟和高吞吐量,性能显著优于vLLM等标准推理引擎。
- 广泛的开源模型库: 即时访问数百个流行的开源模型,涵盖文本、视觉、音频和图像生成,包括Llama 3.1、Mixtral、Qwen和DeepSeek。用户也可以上传自定义模型。
- 高级微调与定制: 提供复杂的模型定制工具,包括监督式微调(SFT)、强化学习微调(RFT)和量化感知微调,以针对特定用例实现最高质量。
- Multi-LoRA服务: 在单个部署上部署数百个经过微调的LoRA适配器,而无需额外的服务成本,从而高效地实现大规模个性化和实验。
- 灵活的部署选项: 提供Serverless(按令牌付费)、On-Demand(按GPU秒付费)和Enterprise Reserved(企业预留)容量,以适应从原型设计到大规模生产的不同规模和需求。
- 多模态能力: 支持广泛的AI任务,包括文本生成、语音转文本转录、图像生成和视觉语言理解。
- 复合AI与结构化输出: 函数调用、JSON模式和语法模式等功能允许构建复杂、可靠的AI系统,这些系统可以与其他工具和API交互。
- 企业级安全与可扩展性: 符合SOC2 Type II、GDPR和HIPAA标准,在全球10多个云和15多个地区进行部署,以实现高可用性和无缝扩展。
Fireworks AI的使用案例
Fireworks AI受到Notion、Sourcegraph和Quora等领先公司的信赖,用于各种应用。常见用例包括:
- 实时AI代理: 构建延迟极低的响应迅速的语音代理和聊天机器人。
- AI驱动的开发者工具: 创建高级编码助手,如Sourcegraph的Cody,具有快速的代码补全和AI驱动的搜索功能。
- 企业级RAG系统: 驱动大规模检索增强生成工作流,如Notion所用,以提供准确、具有上下文感知的答案。
- 大规模个性化AI: 为不同用户或领域提供数千个自定义模型,例如Quora的领域特定基础模型。
- 高吞吐量媒体处理: 为内容创作和分析平台执行快速的音频转录和图像生成。
Fireworks AI的优势特点
Fireworks AI的主要优势在于其极致的性能。客户证言强调了显著的延迟降低(例如,Notion的延迟从2秒降至350毫秒),从而实现了实时用户体验。其成本效益是另一个关键优势,通过优化的引擎和Multi-LoRA服务等创新功能实现。该平台提供了深度定制功能,但没有通常的复杂性,使高级AI变得易于使用。最后,其以开发者为中心的方法,拥有强大的SDK、详尽的文档和无缝的可扩展性,使团队能够快速可靠地从想法走向生产。
定价和计划
Fireworks AI采用免费增值、按需付费的模式,新用户可获得1美元的免费额度。定价按服务细分:
- Serverless推理: 按每百万个令牌计费,费率因模型大小而异(例如,4B-16B模型为0.20美元,>16B模型为0.90美元)。
- 微调: 按每百万个训练令牌收费(例如,对于高达16B参数的模型为0.50美元)。服务微调模型的成本与基础模型相同。
- 语音转文本: 按音频分钟定价(例如,Whisper-v3-large为0.0015美元/分钟)。
- 图像生成: 根据模型,按步数或每张图像计费。
- 按需部署: 为专用硬件(如NVIDIA H100,5.80美元/小时;或A100,2.90美元/小时)按GPU秒付费,提供更高的吞吐量且无速率限制。
这种灵活的结构允许用户根据其特定的使用模式和规模优化成本。
Fireworks AI 评论 (0)
登录后即可发表评论
立即登录Fireworks AI网站流量分析
最新流量情况
状态
月度流量趋势
地理位置
Top 5 国家/地区
-
🇺🇸 United States48.63%
-
🇮🇳 India19.04%
-
🇹🇭 Thailand11.96%
-
🇷🇺 Russia10.38%
-
🇨🇳 China9.99%
流量来源
| 来源类型 | 百分比 |
|---|---|
|
直接访问
|
90.87% |
|
外链引荐
|
7.34% |
|
邮件
|
1.79% |
热门关键词
| 关键词 | 每次点击费用 |
|---|---|
|
$4.30
|
|
|
$0.00
|
|
|
$0.00
|
|
|
$0.00
|
|
|
$0.00
|
Fireworks AI 替代方案
查看全部
thundercompute
Thunder Compute 是一个超低成本的GPU云平台,专为AI和机器学习开发者设计。它提供NVIDIA A100和T4等按需GPU实例,价格比主流云服务商低80%。凭借一键设置、VS Code集成和无缝扩展等功能,它极大地简化了从原型设计到生产的开发工作流程,让开发者能专注于构建模型,而非管理基础设施。
Thunder Compute 是一个超低成本的GPU云平台,专为AI和机器学习开发者设计。它提供NVIDIA A100和T4等按需GPU实例,价格比主流云服务商低80%。凭借一键设置、VS Code集成和无缝扩展等功能,它极大地简化了从原型设计到生产的开发工作流程,让开发者能专注于构建模型,而非管理基础设施。

Predibase
Predibase 是一个端到端的开发者平台,用于高效地微调和服务开源大型语言模型(LLM)。它使用户能够构建自定义的 AI 模型,在特定任务上超越像 GPT-4 这样的大型专有模型,同时显著降低成本和推理延迟。该平台采用强化学习微调(RFT)和 LoRAX 等先进技术,实现高速、多模型的服务。
Predibase 是一个端到端的开发者平台,用于高效地微调和服务开源大型语言模型(LLM)。它使用户能够构建自定义的 AI 模型,在特定任务上超越像 GPT-4 这样的大型专有模型,同时显著降低成本和推理延迟。该平台采用强化学习微调(RFT)和 LoRAX 等先进技术,实现高速、多模型的服务。

Paperspace
Paperspace 是一个专为人工智能和机器学习设计的高性能云计算平台。它提供对强大云GPU、托管式Jupyter笔记本和完整的MLOps平台(Gradient)的轻松访问,以构建、训练和部署模型。它非常适合希望在无需管理复杂基础设施的情况下加速其AI工作流程的开发人员、数据科学家和企业。
Paperspace 是一个专为人工智能和机器学习设计的高性能云计算平台。它提供对强大云GPU、托管式Jupyter笔记本和完整的MLOps平台(Gradient)的轻松访问,以构建、训练和部署模型。它非常适合希望在无需管理复杂基础设施的情况下加速其AI工作流程的开发人员、数据科学家和企业。

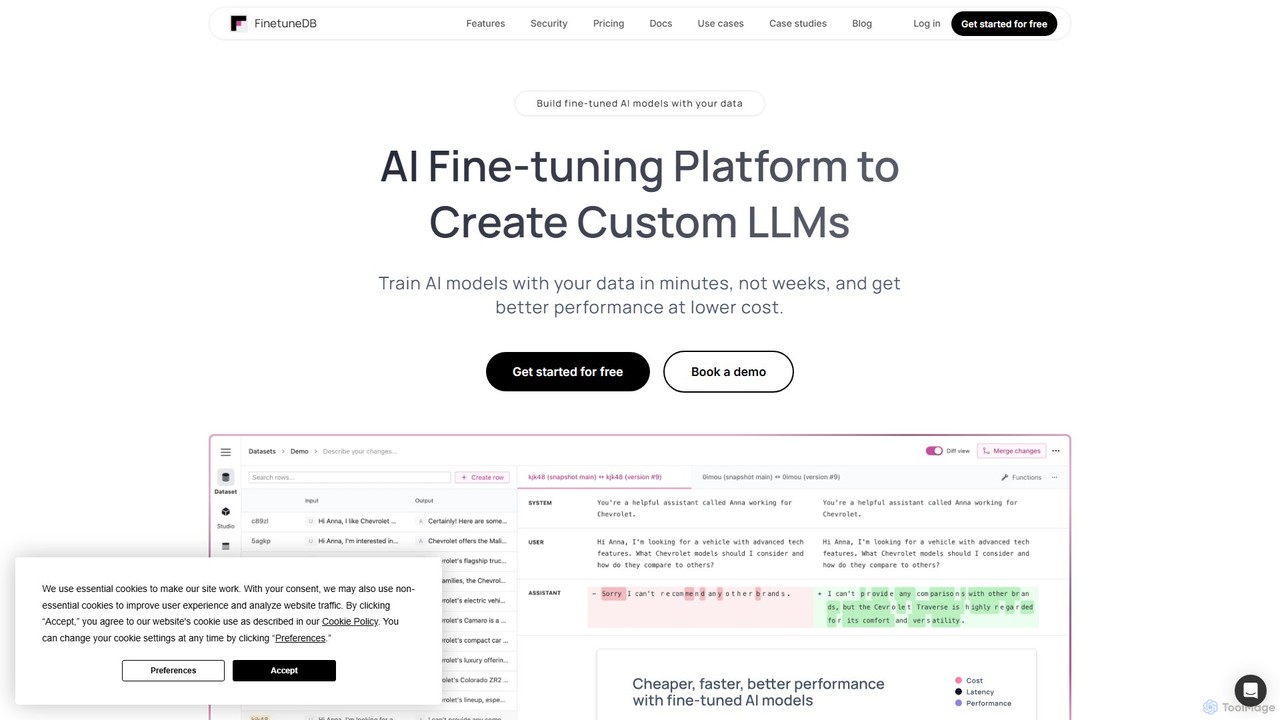
FinetuneDB
FinetuneDB 是一个面向开发人员的一体化 AI 微调平台。它简化了创建自定义大型语言模型(LLM)的整个工作流程,从构建高质量数据集、微调 Llama 3 和 GPT-4o mini 等模型,到在单一、安全的平台上进行部署和持续评估。
FinetuneDB 是一个面向开发人员的一体化 AI 微调平台。它简化了创建自定义大型语言模型(LLM)的整个工作流程,从构建高质量数据集、微调 Llama 3 和 GPT-4o mini 等模型,到在单一、安全的平台上进行部署和持续评估。

OctoAI
OctoAI 是一个高性能计算平台,旨在帮助开发者高效地运行、调整和扩展生成式AI模型。它为Llama、Mixtral和Stable Diffusion等流行的开源模型提供优化的、生产就绪的API端点。通过专注于深度系统优化,OctoAI提供了更快的推理速度和更低的成本,使企业能够轻松构建和部署可扩展的AI应用程序,而无需管理复杂的基础设施。
OctoAI 是一个高性能计算平台,旨在帮助开发者高效地运行、调整和扩展生成式AI模型。它为Llama、Mixtral和Stable Diffusion等流行的开源模型提供优化的、生产就绪的API端点。通过专注于深度系统优化,OctoAI提供了更快的推理速度和更低的成本,使企业能够轻松构建和部署可扩展的AI应用程序,而无需管理复杂的基础设施。
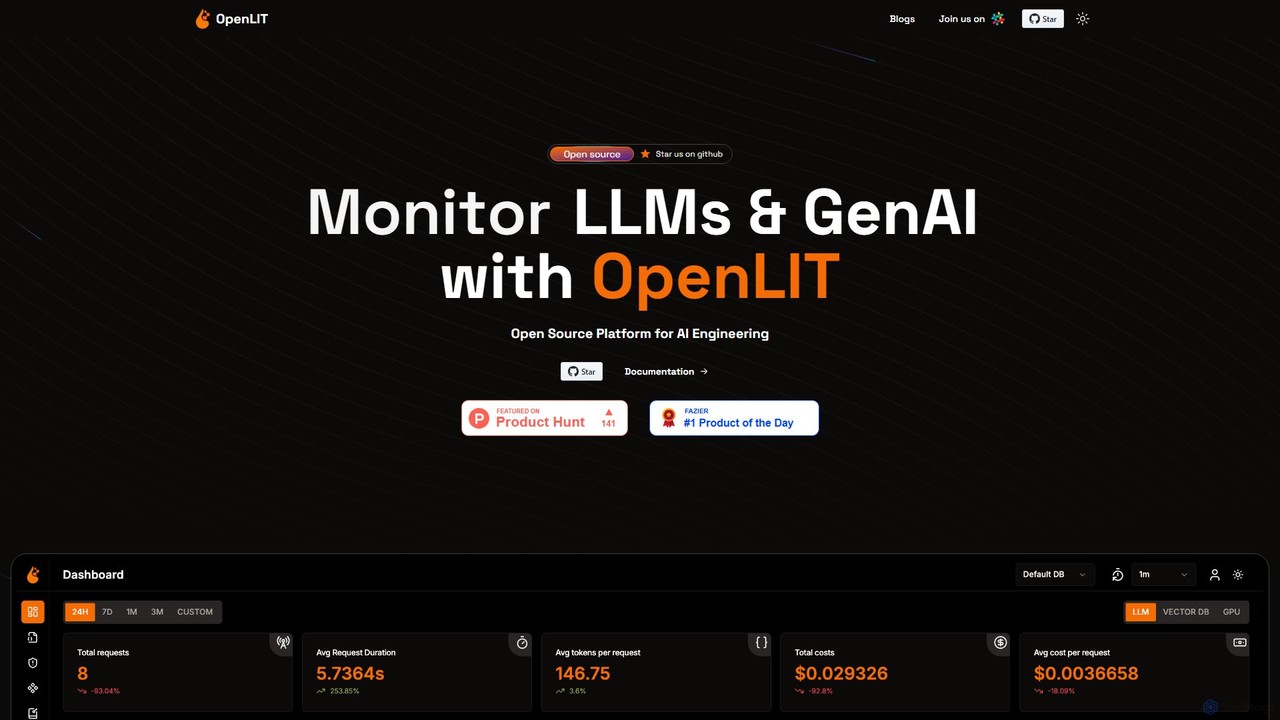
OpenLIT
OpenLIT 是一个专为生成式 AI 和 LLM 应用设计的开源、OpenTelemetry 原生可观测性平台。它通过请求追踪、成本跟踪、异常监控和性能分析等工具简化了开发流程。OpenLIT 拥有集中的提示词仓库、用于存储密钥的安全保管库以及用于比较 LLM 的实验场,为高效监控和扩展 AI 应用提供了全面的解决方案。
OpenLIT 是一个专为生成式 AI 和 LLM 应用设计的开源、OpenTelemetry 原生可观测性平台。它通过请求追踪、成本跟踪、异常监控和性能分析等工具简化了开发流程。OpenLIT 拥有集中的提示词仓库、用于存储密钥的安全保管库以及用于比较 LLM 的实验场,为高效监控和扩展 AI 应用提供了全面的解决方案。


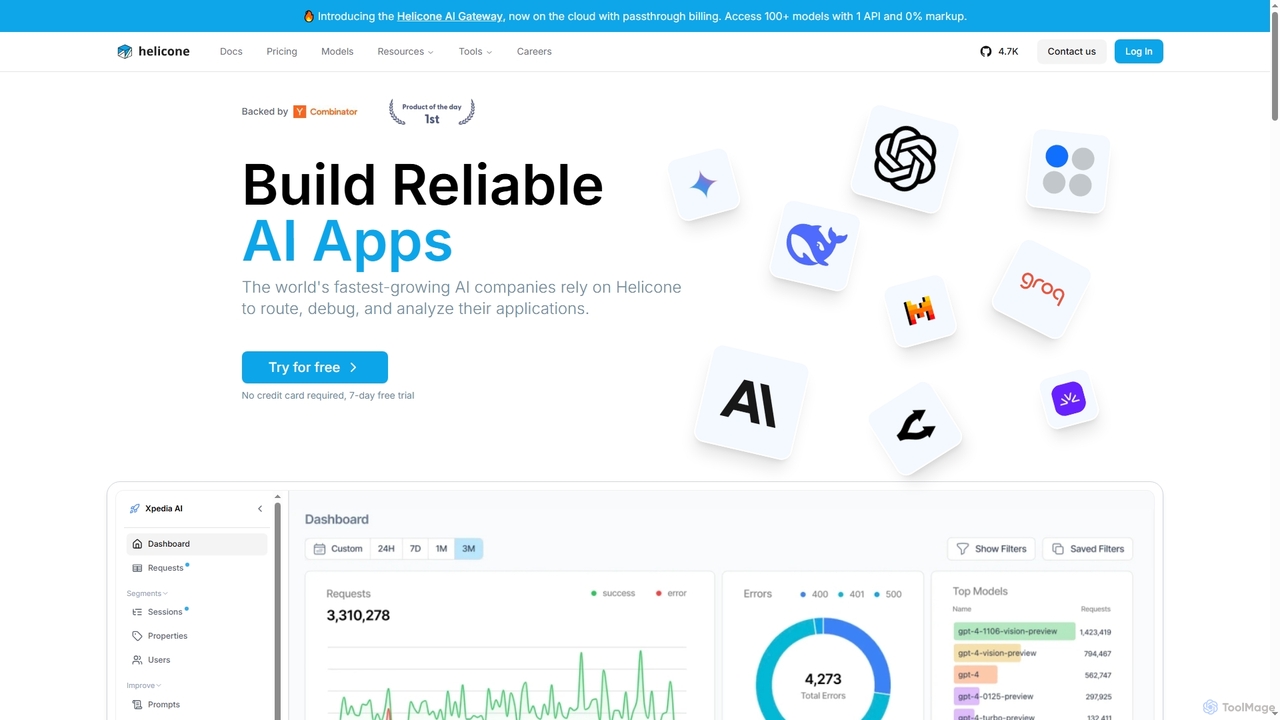
Helicone
Helicone 是一个为开发者提供的开源平台,集成了 AI 网关和 LLM 可观测性功能。它通过提供路由、监控、调试和分析 LLM 使用情况的工具,帮助构建可靠的 AI 应用程序。主要功能包括支持100多种模型的统一 API、智能缓存、速率限制、提示词管理和详细的性能分析。
Helicone 是一个为开发者提供的开源平台,集成了 AI 网关和 LLM 可观测性功能。它通过提供路由、监控、调试和分析 LLM 使用情况的工具,帮助构建可靠的 AI 应用程序。主要功能包括支持100多种模型的统一 API、智能缓存、速率限制、提示词管理和详细的性能分析。
Fireworks AI AI工具对比
Fireworks AI 嵌入功能
只需复制下方嵌入代码,将精美徽章贴到您的博客、文章或应用官网,即可把流量直接引导到本工具详情页,快速提升曝光与用户量!

还没有评论,成为第一个评论者吧!