Oneinfer
Oneinfer 是一个面向开发人员的高性能 AI 推理平台。它提供统一的 API 来访问超过 15 种 LLM(如 GPT-4 和 Claude),从而简化 AI 集成。该平台具有无服务器部署、自动扩展、企业级安全性和按使用付费的定价模式。它还为自定义 AI 工作负载提供了一个租用 GPU 实例的市场。
Oneinfer 是一个面向开发人员的高性能 AI 推理平台。它提供统一的 API 来访问超过 15 种 LLM(如 GPT-4 和 Claude),从而简化 AI 集成。该平台具有无服务器部署、自动扩展、企业级安全性和按使用付费的定价模式。它还为自定义 AI 工作负载提供了一个租用 GPU 实例的市场。

HIVE Digital Technologies
HIVE Digital Technologies 是可持续数据中心基础设施领域的全球领导者,专注于大规模比特币挖矿和为人工智能应用提供高性能计算(HPC)。HIVE 利用其 NVIDIA GPU 集群,通过其位于加拿大、瑞典和巴拉圭的地理多元化数据中心,以高效的绿色能源为变革性技术提供动力。
HIVE Digital Technologies 是可持续数据中心基础设施领域的全球领导者,专注于大规模比特币挖矿和为人工智能应用提供高性能计算(HPC)。HIVE 利用其 NVIDIA GPU 集群,通过其位于加拿大、瑞典和巴拉圭的地理多元化数据中心,以高效的绿色能源为变革性技术提供动力。
Exa Laboratories
Exa Laboratories(现为 Zettascale)是一家由 YC 支持的硅谷初创公司,致力于为人工智能开发最先进、高能效的可重构芯片(XPU)。其多态计算架构旨在通过提供比传统 GPU 和 TPU 更卓越的性能、通用性和效率,解决人工智能训练和推理中的能源危机问题。
Exa Laboratories(现为 Zettascale)是一家由 YC 支持的硅谷初创公司,致力于为人工智能开发最先进、高能效的可重构芯片(XPU)。其多态计算架构旨在通过提供比传统 GPU 和 TPU 更卓越的性能、通用性和效率,解决人工智能训练和推理中的能源危机问题。
Prediction Guard
Prediction Guard 是一个企业级 AI 平台,允许组织在自己的防火墙后安全地部署、管理和扩展大型语言模型 (LLM)。它提供灵活的部署选项,包括本地、物理隔离和私有云,确保完全的数据隐私和控制。凭借其与 OpenAI 兼容的 API,它可以与 LangChain 和 LlamaIndex 等现有工具和框架无缝集成,是医疗、国防和金融等受监管行业的理想选择。
Prediction Guard 是一个企业级 AI 平台,允许组织在自己的防火墙后安全地部署、管理和扩展大型语言模型 (LLM)。它提供灵活的部署选项,包括本地、物理隔离和私有云,确保完全的数据隐私和控制。凭借其与 OpenAI 兼容的 API,它可以与 LangChain 和 LlamaIndex 等现有工具和框架无缝集成,是医疗、国防和金融等受监管行业的理想选择。

StackSpaces
StackSpaces 是一个集成开发平台,旨在帮助开发人员轻松构建、部署和扩展全栈 AI 应用程序。它提供了一个包含后端、前端和基础设施组件的统一环境,简化了从创意到生产的整个开发生命周期。
StackSpaces 是一个集成开发平台,旨在帮助开发人员轻松构建、部署和扩展全栈 AI 应用程序。它提供了一个包含后端、前端和基础设施组件的统一环境,简化了从创意到生产的整个开发生命周期。
Fastly
Fastly 是一个领先的边缘云平台,旨在构建、保护和交付快速、可扩展的数字体验。它结合了现代化的 CDN、强大的安全功能(如新一代 WAF)以及功能强大的无服务器计算环境。Fastly 帮助企业提升性能、增强安全性,并在更靠近用户的位置进行创新,为电子商务、流媒体和 AI 驱动的应用提供特定解决方案。
Fastly 是一个领先的边缘云平台,旨在构建、保护和交付快速、可扩展的数字体验。它结合了现代化的 CDN、强大的安全功能(如新一代 WAF)以及功能强大的无服务器计算环境。Fastly 帮助企业提升性能、增强安全性,并在更靠近用户的位置进行创新,为电子商务、流媒体和 AI 驱动的应用提供特定解决方案。
Tensorfuse
Tensorfuse 是一个无服务器 GPU 平台,允许开发者在自己的 AWS 云上微调、部署和自动扩展生成式 AI 模型。它简化了基础设施管理,提供无服务器推理、作业队列和开发容器等功能,以加速开发、降低成本并消除 DevOps 开销。
Tensorfuse 是一个无服务器 GPU 平台,允许开发者在自己的 AWS 云上微调、部署和自动扩展生成式 AI 模型。它简化了基础设施管理,提供无服务器推理、作业队列和开发容器等功能,以加速开发、降低成本并消除 DevOps 开销。
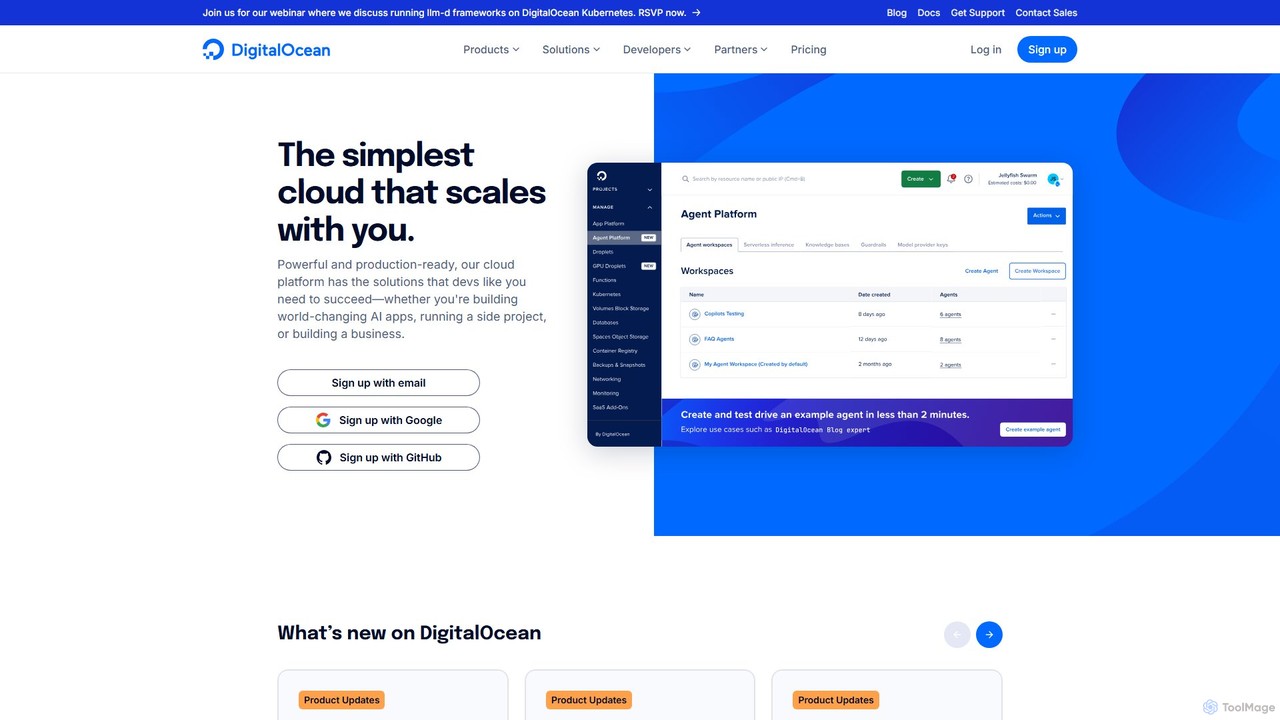
DigitalOcean
DigitalOcean 是一个专注于开发者的云基础设施平台,可简化应用程序的构建、部署和扩展。它提供一整套产品,包括虚拟机(Droplets)、托管 Kubernetes 和 GradientAI 平台,为创建和托管足以改变世界的人工智能应用(从个人项目到大型企业)提供强大的 GPU 资源和工具。
DigitalOcean 是一个专注于开发者的云基础设施平台,可简化应用程序的构建、部署和扩展。它提供一整套产品,包括虚拟机(Droplets)、托管 Kubernetes 和 GradientAI 平台,为创建和托管足以改变世界的人工智能应用(从个人项目到大型企业)提供强大的 GPU 资源和工具。


thundercompute
Thunder Compute 是一个超低成本的GPU云平台,专为AI和机器学习开发者设计。它提供NVIDIA A100和T4等按需GPU实例,价格比主流云服务商低80%。凭借一键设置、VS Code集成和无缝扩展等功能,它极大地简化了从原型设计到生产的开发工作流程,让开发者能专注于构建模型,而非管理基础设施。
Thunder Compute 是一个超低成本的GPU云平台,专为AI和机器学习开发者设计。它提供NVIDIA A100和T4等按需GPU实例,价格比主流云服务商低80%。凭借一键设置、VS Code集成和无缝扩展等功能,它极大地简化了从原型设计到生产的开发工作流程,让开发者能专注于构建模型,而非管理基础设施。

massedcompute
Massed Compute 是一个云平台,提供按需、高性能的 NVIDIA GPU 和 CPU。它为人工智能开发、机器学习和大数据分析提供灵活、可扩展且经济实惠的计算能力,无需长期合同,专为创新者和开发者设计。
Massed Compute 是一个云平台,提供按需、高性能的 NVIDIA GPU 和 CPU。它为人工智能开发、机器学习和大数据分析提供灵活、可扩展且经济实惠的计算能力,无需长期合同,专为创新者和开发者设计。

Predibase
Predibase 是一个端到端的开发者平台,用于高效地微调和服务开源大型语言模型(LLM)。它使用户能够构建自定义的 AI 模型,在特定任务上超越像 GPT-4 这样的大型专有模型,同时显著降低成本和推理延迟。该平台采用强化学习微调(RFT)和 LoRAX 等先进技术,实现高速、多模型的服务。
Predibase 是一个端到端的开发者平台,用于高效地微调和服务开源大型语言模型(LLM)。它使用户能够构建自定义的 AI 模型,在特定任务上超越像 GPT-4 这样的大型专有模型,同时显著降低成本和推理延迟。该平台采用强化学习微调(RFT)和 LoRAX 等先进技术,实现高速、多模型的服务。

Fireworks AI
一个为开发者设计的高性能平台,用于构建、定制和扩展生成式AI应用。它提供业界领先的快速推理引擎、先进的微调功能以及对广泛开源模型的访问,从而实现实时、高性价比的AI解决方案。
一个为开发者设计的高性能平台,用于构建、定制和扩展生成式AI应用。它提供业界领先的快速推理引擎、先进的微调功能以及对广泛开源模型的访问,从而实现实时、高性价比的AI解决方案。
HyperAI
HyperAI 是一个位于欧洲的超本地化 GPU 云平台,旨在普及企业级 AI 计算。它通过灵活的计划(包括即用实例和专用服务器)提供高性能的 NVIDIA A100 和 H100 GPU。HyperAI 专注于低延迟、数据合规性和开发者友好的环境,并预装了 Nvidia AI SDK,助力开发者和企业高效、安全地构建、训练和部署复杂的 AI 模型。
HyperAI 是一个位于欧洲的超本地化 GPU 云平台,旨在普及企业级 AI 计算。它通过灵活的计划(包括即用实例和专用服务器)提供高性能的 NVIDIA A100 和 H100 GPU。HyperAI 专注于低延迟、数据合规性和开发者友好的环境,并预装了 Nvidia AI SDK,助力开发者和企业高效、安全地构建、训练和部署复杂的 AI 模型。
Google Cloud
Google Cloud 是一套全面的云计算服务,提供基础设施、平台和无服务器环境。它在人工智能/机器学习(Vertex AI 和 Gemini)和数据分析(BigQuery)方面表现卓越,并为从初创公司到全球性企业的各种规模的企业提供可扩展、安全的基础设施。
Google Cloud 是一套全面的云计算服务,提供基础设施、平台和无服务器环境。它在人工智能/机器学习(Vertex AI 和 Gemini)和数据分析(BigQuery)方面表现卓越,并为从初创公司到全球性企业的各种规模的企业提供可扩展、安全的基础设施。
Cirrascale Cloud Services
Cirrascale 提供专为大规模人工智能、深度学习和高性能计算(HPC)量身定制的高性能专用 GPU 云服务。它提供对最新 NVIDIA GPU 硬件和可扩展基础设施的访问,使企业能够高效地训练大型模型并运行复杂的计算工作负载。
Cirrascale 提供专为大规模人工智能、深度学习和高性能计算(HPC)量身定制的高性能专用 GPU 云服务。它提供对最新 NVIDIA GPU 硬件和可扩展基础设施的访问,使企业能够高效地训练大型模型并运行复杂的计算工作负载。
Clore.ai
Clore.ai 是一个去中心化 GPU 市场,提供对全球高性能计算资源的按需访问。它将需要 GPU 算力进行 AI 训练、3D 渲染和科学模拟的用户与希望将闲置服务器变现的硬件所有者连接起来。该平台拥有灵活的租赁市场、用于交易的自有加密货币 (CLORE) 以及独特的持币证明 (POH) 系统,以提供更高的奖励和折扣,为高性能计算创建了一个全面的生态系统。
Clore.ai 是一个去中心化 GPU 市场,提供对全球高性能计算资源的按需访问。它将需要 GPU 算力进行 AI 训练、3D 渲染和科学模拟的用户与希望将闲置服务器变现的硬件所有者连接起来。该平台拥有灵活的租赁市场、用于交易的自有加密货币 (CLORE) 以及独特的持币证明 (POH) 系统,以提供更高的奖励和折扣,为高性能计算创建了一个全面的生态系统。

Juice
Juice 是一个纯软件平台,可实现 GPU-over-IP(IP网络上的GPU),允许您通过任何标准网络访问、共享和池化 GPU 资源。它将 GPU 与物理机器解耦,按需将任何 CPU 节点转变为 GPU 加速系统,从而在无需更改代码的情况下优化利用率并显著降低 AI 和图形工作负载的成本。
Juice 是一个纯软件平台,可实现 GPU-over-IP(IP网络上的GPU),允许您通过任何标准网络访问、共享和池化 GPU 资源。它将 GPU 与物理机器解耦,按需将任何 CPU 节点转变为 GPU 加速系统,从而在无需更改代码的情况下优化利用率并显著降低 AI 和图形工作负载的成本。
HIVE Digital Technologies
HIVE Digital Technologies 是构建和运营由绿色能源驱动的尖端数据中心的全球领导者。它为人工智能解决方案提供高性能计算(HPC)和GPU云基础设施,同时运营大规模比特币挖矿业务,专注于可持续性和数据主权。
HIVE Digital Technologies 是构建和运营由绿色能源驱动的尖端数据中心的全球领导者。它为人工智能解决方案提供高性能计算(HPC)和GPU云基础设施,同时运营大规模比特币挖矿业务,专注于可持续性和数据主权。

OctoAI
OctoAI 是一个高性能计算平台,旨在帮助开发者高效地运行、调整和扩展生成式AI模型。它为Llama、Mixtral和Stable Diffusion等流行的开源模型提供优化的、生产就绪的API端点。通过专注于深度系统优化,OctoAI提供了更快的推理速度和更低的成本,使企业能够轻松构建和部署可扩展的AI应用程序,而无需管理复杂的基础设施。
OctoAI 是一个高性能计算平台,旨在帮助开发者高效地运行、调整和扩展生成式AI模型。它为Llama、Mixtral和Stable Diffusion等流行的开源模型提供优化的、生产就绪的API端点。通过专注于深度系统优化,OctoAI提供了更快的推理速度和更低的成本,使企业能够轻松构建和部署可扩展的AI应用程序,而无需管理复杂的基础设施。

Fluidstack
Fluidstack 是一个领先的 AI 云平台,为训练和部署前沿 AI 模型提供高性能的专用 GPU 集群。它提供数千个 GPU 的快速部署、带 24/7 专家支持的全托管服务,以及零出口费用的透明定价,助力 AI 团队无缝扩展,摆脱基础设施的束缚。
Fluidstack 是一个领先的 AI 云平台,为训练和部署前沿 AI 模型提供高性能的专用 GPU 集群。它提供数千个 GPU 的快速部署、带 24/7 专家支持的全托管服务,以及零出口费用的透明定价,助力 AI 团队无缝扩展,摆脱基础设施的束缚。
GreenNode
GreenNode 是一站式 AI 云基础设施提供商,为初创公司和企业提供高性能的 NVIDIA GPU 解决方案。它提供对 H100 GPU 等尖端资源的即时访问、可扩展的基础设施以及专业的 AI 实验室支持。GreenNode 专注于成本效益和性能,帮助加速模型训练、微调和推理,并在东南亚拥有强大的业务布局。
GreenNode 是一站式 AI 云基础设施提供商,为初创公司和企业提供高性能的 NVIDIA GPU 解决方案。它提供对 H100 GPU 等尖端资源的即时访问、可扩展的基础设施以及专业的 AI 实验室支持。GreenNode 专注于成本效益和性能,帮助加速模型训练、微调和推理,并在东南亚拥有强大的业务布局。





Cloudflare
Cloudflare 是一个全球连通云平台,提供一整套全面的安全、性能和可靠性服务。它通过其 WAF 和 DDoS 防护功能保护网站和应用程序免受在线威胁,通过其全球 CDN 加速内容交付,并为开发人员提供一个无服务器平台,用于在边缘构建和部署应用程序,包括 AI 驱动的服务。
Cloudflare 是一个全球连通云平台,提供一整套全面的安全、性能和可靠性服务。它通过其 WAF 和 DDoS 防护功能保护网站和应用程序免受在线威胁,通过其全球 CDN 加速内容交付,并为开发人员提供一个无服务器平台,用于在边缘构建和部署应用程序,包括 AI 驱动的服务。

Paperspace
Paperspace 是一个专为人工智能和机器学习设计的高性能云计算平台。它提供对强大云GPU、托管式Jupyter笔记本和完整的MLOps平台(Gradient)的轻松访问,以构建、训练和部署模型。它非常适合希望在无需管理复杂基础设施的情况下加速其AI工作流程的开发人员、数据科学家和企业。
Paperspace 是一个专为人工智能和机器学习设计的高性能云计算平台。它提供对强大云GPU、托管式Jupyter笔记本和完整的MLOps平台(Gradient)的轻松访问,以构建、训练和部署模型。它非常适合希望在无需管理复杂基础设施的情况下加速其AI工作流程的开发人员、数据科学家和企业。
Float16.cloud
Float16.cloud 是一个旨在加速人工智能开发的无服务器 GPU 平台。它提供对高性能 H100 GPU 的即时访问,具有按秒计费、零设置和无冷启动的特点。开发人员可以直接通过 Python 脚本部署开源大语言模型、训练模型和运行 AI 工作负载,而无需管理基础设施。
Float16.cloud 是一个旨在加速人工智能开发的无服务器 GPU 平台。它提供对高性能 H100 GPU 的即时访问,具有按秒计费、零设置和无冷启动的特点。开发人员可以直接通过 Python 脚本部署开源大语言模型、训练模型和运行 AI 工作负载,而无需管理基础设施。
关于 云计算
AI 云计算工具是利用机器学习来自动化管理和优化云基础设施的平台。这类工具通过分析指标、日志和成本报告等海量运营数据来识别模式并预测未来需求。它们为成本节约、性能改进和安全增强提供智能建议,显著减少维护复杂云环境所需的人工操作。这种主动式方法帮助组织在 AWS、Azure 和 GCP 等平台上提高可靠性、控制开支并加强安全态势。
核心功能
- AI 驱动的成本优化:自动识别闲置资源,建议实例规格调整,并预测支出以优化预算。
- 智能性能监控:利用异常检测技术,在性能瓶颈和潜在故障影响用户前主动发出警报。
- 自动化安全与合规:运用机器学习检测异常活动、识别漏洞,并持续检查是否符合 GDPR 或 SOC 2 等标准。
- 预测性自动扩缩:预测流量模式,比传统基于规则的方法更高效地增减资源,平衡性能与成本。
- 智能资产管理:提供智能仪表板和建议,用于跨多个账户或云服务商组织、标记和管理云资源。
适用场景
这些工具主要由 DevOps 工程师、站点可靠性工程师 (SRE)、FinOps 专业人员和 IT 管理员使用。对于拥有大规模、动态或多云部署,且手动监控不切实际的组织而言,它们尤其有价值。常见场景包括管理 Kubernetes 集群、优化无服务器函数成本以及保护云原生应用安全。
选择要点
选择 AI 云计算工具时,请考虑其与您的云服务商(如 AWS、Azure、Google Cloud)的兼容性。评估其在成本、性能和安全方面 AI 驱动分析的深度。考察其自动化能力、与现有工具链(如 Slack 或 Jira)的集成情况,以及其报告和用户界面的清晰度。最后,考虑定价模式是否与您的运营规模相匹配。
精选工具排行榜
最受欢迎
按月度最高流量排序
互动性最强
按最低跳出率排序
用户粘性最高
按平均访问时长排序
云计算应用场景
为初创公司自动化云成本控制
一家快速发展的 SaaS 初创公司的 FinOps 团队面临着在不减缓开发速度的情况下控制迅速增长的 AWS 账单的任务。他们部署了一款 AI 云计算工具,该工具能持续扫描其环境。该工具的 AI 模型识别出未充分利用的 EC2 实例并建议降级。它还能自动终止开发测试后遗留的未标记、孤立资源。在第一个月内,该工具的自动化操作和可行性建议帮助这家初创公司将其云支出减少了 20% 以上,在保持性能的同时,极大地缓解了预算压力。
为电子商务平台进行主动异常检测
一个电子商务网站的 SRE 团队使用 AI 监控工具来防止在购物旺季发生服务中断。该工具学习其应用程序的正常性能基线,包括 CPU 使用率、内存和 API 响应时间。在一次限时抢购活动中,AI 检测到一个特定微服务中不寻常的内存泄漏模式,而这是传统的基于阈值的警报可能会错过的。团队通过 Slack 立即收到通知,使他们能够在问题升级为全站崩溃之前部署修复程序,从而保护了收入和客户体验。
为金融服务增强云安全
一家金融科技公司必须保持严格的安全态势以符合法规要求。他们使用一款 AI 驱动的云安全工具,该工具能实时分析用户活动日志和网络流量。AI 模型识别出一位开发人员的凭证正从一个不寻常的地理位置使用,并试图访问敏感的生产数据。这种异常行为触发了高优先级警报。安全团队能够迅速调查,确认账户被盗用,并撤销访问权限,从而在任何敏感信息被泄露之前阻止了潜在的数据泄露事件。
优化 Kubernetes 集群资源
一个软件开发团队在 Google Kubernetes Engine (GKE) 集群上运行他们的微服务,但苦于资源分配问题,导致资源浪费或性能问题。他们集成了一款 AI 云工具,该工具能随时间分析工作负载模式。该工具为每个 Pod 的 CPU 和内存请求及限制提供了具体的调整建议。通过应用这些 AI 驱动的建议,团队将其集群的整体资源消耗降低了 30%,同时消除了影响应用程序延迟的 CPU 节流问题。
简化多云合规审计流程
一家全球性企业在 Azure 和 GCP 上都运行工作负载,这使得像 SOC 2 这样的标准合规审计成为一个复杂且耗时的过程。他们采用了一个 AI 云平台来自动化合规监控。该工具根据预构建的 SOC 2 控制框架,持续扫描配置、访问策略和数据存储设置。它使用 AI 标记潜在的违规行为,并自动生成详细的、可直接用于审计的报告。这将审计准备的人工工作从数周减少到几天,并为安全团队提供了对其合规状况的持续、实时的视图。
为媒体流媒体服务进行预测性扩缩
一家视频流媒体服务公司需要在不超额配置资源和产生过高成本的情况下,处理直播活动期间不可预测的流量高峰。他们实施了一款具有预测性自动扩缩功能的 AI 云工具。该工具分析历史观看数据和实时趋势,以预测即将到来的重大体育决赛的需求。根据其预测,它会在活动开始前一小时自动开始扩展服务器容量,确保为所有用户提供流畅、无缓冲的体验。高峰过后,它会比基于规则的扩缩器更智能地缩减资源,从而节省成本。