BlickState
BlickState 是一款先進的 AI 代理時空旅行除錯工具,使開發者能夠在 AI 代理工具執行失敗的精確毫秒點恢復並檢查完整的記憶體狀態。它將黑盒式的代理行為轉化為透明、可檢查的過程,顯著加速了 AI 工程師的除錯效率。
BlickState 是一款先進的 AI 代理時空旅行除錯工具,使開發者能夠在 AI 代理工具執行失敗的精確毫秒點恢復並檢查完整的記憶體狀態。它將黑盒式的代理行為轉化為透明、可檢查的過程,顯著加速了 AI 工程師的除錯效率。
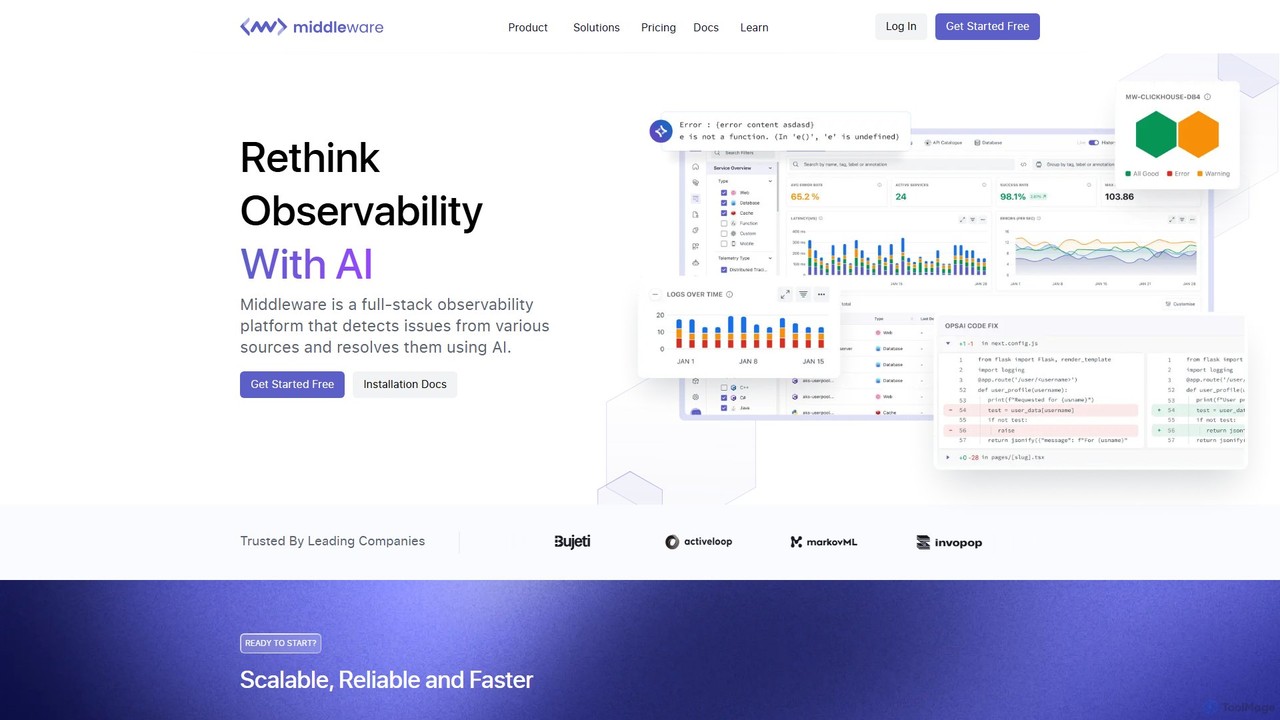
Middleware
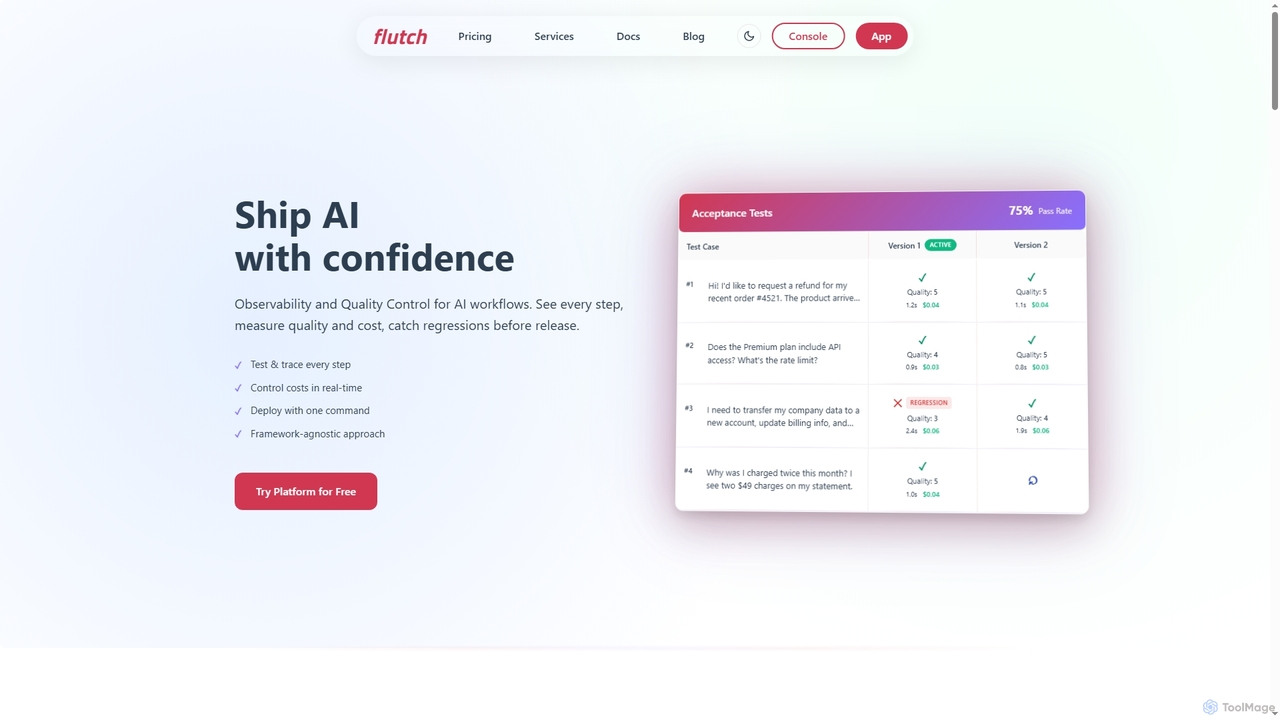
Middleware 是一個由人工智慧驅動的全棧雲可觀測性平台,旨在實現 IT 基礎設施的現代化。它將日誌、指標、追蹤和 RUM 數據統一到一個視圖中,使團隊能夠即時監控其整個技術棧。借助其核心功能 OpsAI,Middleware 可自動偵測、診斷甚至解決高達 70% 的問題,從而顯著縮短解決時間並提高開發人員的生產力。它為各種規模的企業提供了經濟高效、可擴展的解決方案。
Middleware 是一個由人工智慧驅動的全棧雲可觀測性平台,旨在實現 IT 基礎設施的現代化。它將日誌、指標、追蹤和 RUM 數據統一到一個視圖中,使團隊能夠即時監控其整個技術棧。借助其核心功能 OpsAI,Middleware 可自動偵測、診斷甚至解決高達 70% 的問題,從而顯著縮短解決時間並提高開發人員的生產力。它為各種規模的企業提供了經濟高效、可擴展的解決方案。
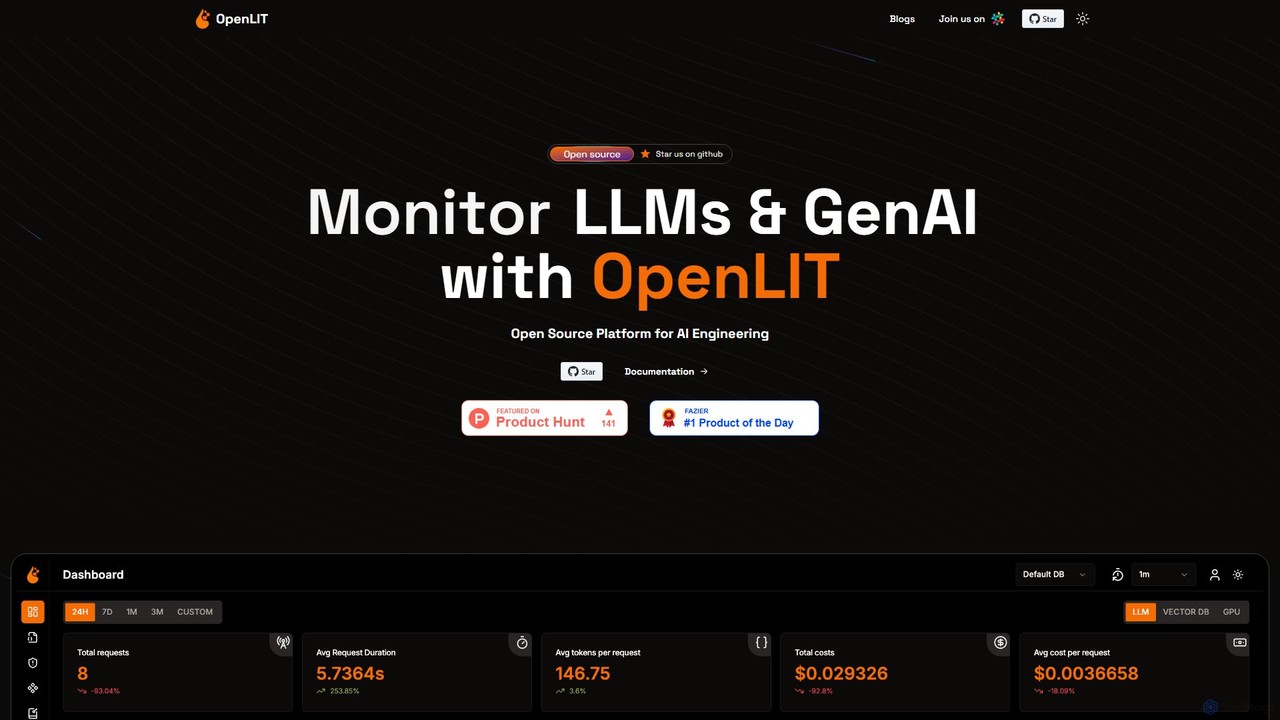
OpenLIT
OpenLIT 是一個專為生成式 AI 和 LLM 應用程式設計的開源、OpenTelemetry 原生可觀測性平台。它透過請求追蹤、成本追蹤、異常監控和效能分析等工具簡化了開發流程。OpenLIT 擁有集中的提示詞儲存庫、用於儲存密鑰的安全保管庫以及用於比較 LLM 的實驗場,為高效監控和擴展 AI 應用程式提供了全面的解決方案。
OpenLIT 是一個專為生成式 AI 和 LLM 應用程式設計的開源、OpenTelemetry 原生可觀測性平台。它透過請求追蹤、成本追蹤、異常監控和效能分析等工具簡化了開發流程。OpenLIT 擁有集中的提示詞儲存庫、用於儲存密鑰的安全保管庫以及用於比較 LLM 的實驗場,為高效監控和擴展 AI 應用程式提供了全面的解決方案。

關於 可觀測性
可觀測性工具是一類利用AI技術,旨在深入洞察複雜軟體系統內部狀態與行為的解決方案。透過收集和分析指標、日誌和追蹤數據,這些工具使開發和維運團隊能夠理解問題發生的根本原因,預測潛在風險,並優化系統性能。它們對於維護現代應用程式的可靠性、效率和彈性至關重要,尤其是在分散式和雲原生環境中。
核心功能
- 自動化數據攝取:自動從各種來源(應用程式、基礎設施、服務)收集指標、日誌和追蹤數據。
- 即時監控與告警:提供儀表板用於即時系統健康視覺化,並在異常或預設閾值時觸發告警。
- 分散式追蹤:追蹤跨多個服務的請求,以查明微服務架構中的延遲瓶頸和故障點。
- 日誌管理與分析:集中、索引和分析海量日誌數據,用於故障排除和安全審計。
- AI驅動的異常檢測:利用機器學習識別系統行為中可能預示潛在問題的異常模式。
適用場景
可觀測性工具對於管理生產系統的SRE、DevOps工程師和開發人員來說不可或缺。它們用於快速診斷應用程式錯誤的根本原因,監控微服務性能,並確保服務水平目標(SLO)的達成。例如,DevOps團隊可能使用這些工具在新部署後識別特定服務中的記憶體洩漏,或理解用戶請求在多個後端組件中為何出現高延遲。
選擇要點
選擇可觀測性工具時,需考慮其數據收集能力(指標、日誌、追蹤)、與現有技術棧的整合度,以及處理不斷增長數據量的可擴展性。評估其實時分析和視覺化功能,包括可定制的儀表板和告警機制。同時,還要評估其AI驅動的異常檢測和根因分析能力,以及基於數據攝取和保留的定價模式。
可觀測性應用場景
更快地診斷生產事故
站點可靠性工程師(SRE)利用可觀測性平台快速查明關鍵生產問題的根本原因。透過關聯分散式服務中的指標、日誌和追蹤數據,他們可以迅速識別出哪個特定組件正在失效或性能下降,從而縮短平均解決時間(MTTR),並最大程度地減少最終用戶的停機時間。
優化微服務性能
開發人員和DevOps團隊利用分散式追蹤來視覺化複雜微服務架構中完整的請求流。這使他們能夠識別延遲瓶頸、低效的資料庫查詢或服務間緩慢的API呼叫,從而實現有針對性的優化,以提高整體應用程式響應速度和用戶體驗。
主動異常檢測
維運團隊部署AI驅動的可觀測性工具,自動檢測系統行為中的異常模式,這些模式可能預示著即將發生的問題。例如,特定API錯誤率的突然飆升或吞吐量的意外下降,可以在影響用戶之前被標記出來,從而實現主動干預並防止服務中斷。
確保合規性和安全審計
安全和合規官員利用集中式日誌管理功能,收集、儲存和分析所有系統組件的審計日誌。這提供了全面的活動軌跡,有助於檢測未經授權的訪問嘗試,調查安全事件,並證明符合GDPR或HIPAA等法規要求。
容量規劃與資源管理
基礎設施工程師利用可觀測性工具收集的歷史性能指標,了解資源利用趨勢(CPU、記憶體、網路)。這些數據為容量規劃提供戰略決策依據,確保有足夠的資源來處理高峰負載,同時避免過度配置和不必要的基建成本。
驗證新部署和功能
開發團隊將可觀測性整合到其CI/CD管道中,以即時監控新程式碼部署或功能發布的影響。透過在發布後立即觀察關鍵績效指標(KPI)和錯誤率,他們可以快速識別回歸或意外行為,並在必要時啟動回滾,確保穩定的發布。