Mcpwhiz
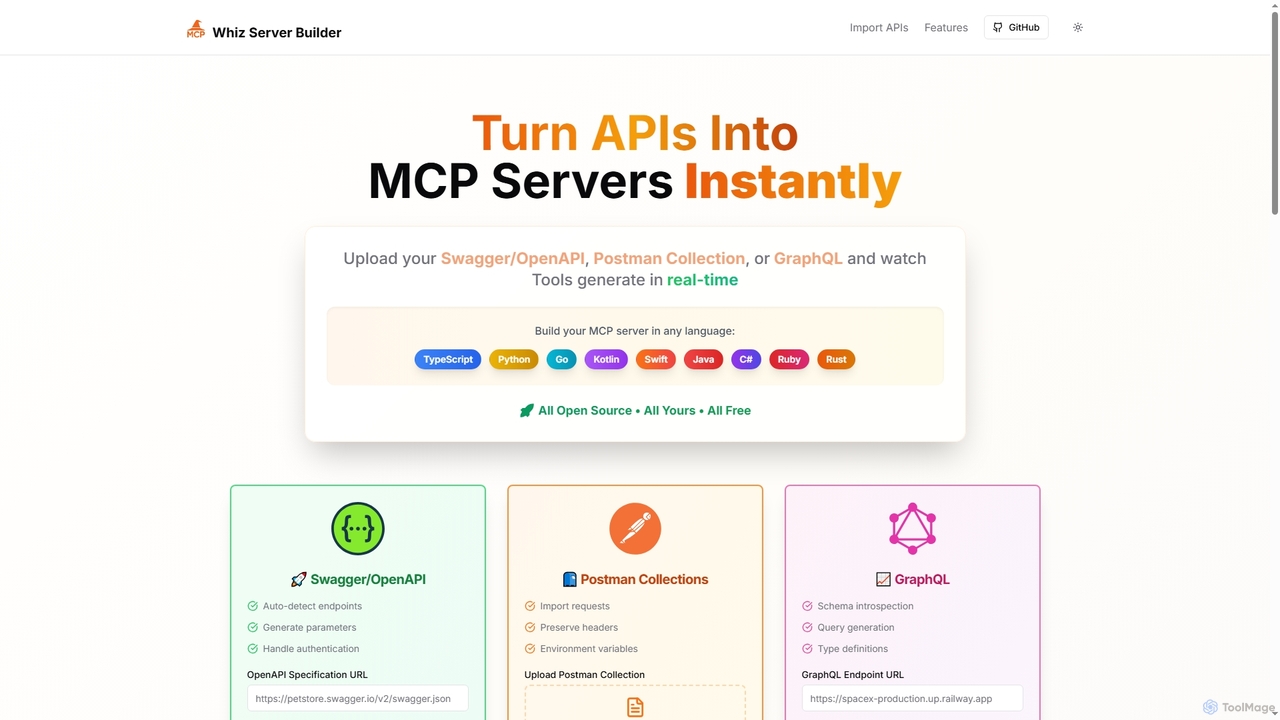
Mcpwhiz is a free, open-source developer tool that instantly converts API specifications like Swagger/OpenAPI, Postman Collections, and GraphQL …
Mcpwhiz is a free, open-source developer tool that instantly converts API specifications like Swagger/OpenAPI, Postman Collections, and GraphQL into production-ready Model Context Protocol (MCP) servers. It automates code generation in multiple languages, including TypeScript and Python, allowing developers to build context-aware applications with ease.
About Server Management
AI Server Management tools are a specialized category of AI Infrastructure software that uses machine learning to automate and optimize the monitoring, maintenance, and performance of server environments. These tools analyze vast amounts of telemetry data—such as logs, metrics, and traces—to identify patterns, predict failures, and automate complex administrative tasks. Their primary value lies in transforming server operations from a reactive to a proactive model, significantly increasing uptime, security, and resource efficiency. By leveraging predictive analytics, they help prevent issues before they impact users and optimize resource allocation for demanding workloads like AI model training.
Core Features
- Predictive Failure Analysis: Uses machine learning models to analyze hardware metrics and logs to forecast potential server component failures.
- Automated Resource Scaling: Intelligently adjusts compute, memory, and storage resources based on real-time workload demands to optimize performance and cost.
- AI-Powered Anomaly Detection: Identifies unusual patterns in performance or security data that deviate from normal baselines, flagging potential issues or threats.
- Automated Root Cause Analysis (RCA): Correlates events across the infrastructure stack to automatically pinpoint the source of a problem, reducing troubleshooting time.
- Energy Consumption Optimization: Analyzes server utilization to manage power states and workload distribution, minimizing electricity costs in data centers.
Applicable Scenarios
These tools are essential for DevOps engineers, MLOps teams, Site Reliability Engineers (SREs), and IT administrators managing large-scale or mission-critical server fleets. They are particularly valuable in environments with high-performance computing (HPC) clusters, cloud-native applications, and infrastructure dedicated to training and deploying AI models, where performance and reliability are paramount.
Selection Criteria
When choosing an AI Server Management tool, consider its integration capabilities with your existing monitoring stack (e.g., Prometheus, Datadog). Evaluate the sophistication of its AI models for prediction and anomaly detection. Also, assess its compatibility with your infrastructure, whether on-premises, cloud, or hybrid, and its support for specific hardware like GPUs.
Server ManagementUse Cases
Proactive Data Center Hardware Maintenance
An IT administrator for a large e-commerce platform is responsible for maintaining hundreds of physical servers. Using an AI Server Management tool, they can move beyond scheduled, routine checks. The tool continuously analyzes vibration sensor data, temperature metrics, and disk I/O error rates. It predicts that three specific hard drives in a critical database cluster have an 85% probability of failure within the next 30 days. This allows the administrator to schedule a maintenance window to replace the drives proactively, preventing a catastrophic outage during a peak sales period and saving hours of emergency recovery work.
Dynamic GPU Resource Allocation for MLOps
An MLOps team at a research institute manages a shared cluster of expensive GPU servers for multiple simultaneous machine learning experiments. An AI Server Management tool monitors the resource requests and actual utilization of each training job. When it detects that one high-priority job is underutilizing its allocated GPUs while another is queued, it automatically reallocates the idle GPU resources. This dynamic scheduling ensures that high-cost hardware is always used efficiently, reducing experiment completion times by up to 30% and maximizing the return on hardware investment.
Automated Security Threat Detection
A financial services company uses an AI Server Management tool to enhance its security posture. The tool establishes a baseline of normal network traffic and user activity for their critical servers. One night, it detects a series of unusual login attempts from a foreign IP address, followed by unexpected data transfers to an external server. This pattern deviates significantly from the established norm. The system automatically flags this as a high-risk anomaly, isolates the affected server from the network, and alerts the security operations team, preventing a potential data breach before significant damage occurs.
Optimizing Cloud Compute Costs
A startup running its entire application on a public cloud provider wants to control its escalating compute costs. Their DevOps team deploys an AI Server Management tool that analyzes historical usage patterns of their virtual machine instances. The tool identifies that several large instances used for data processing are idle for over 18 hours a day. It recommends an automated schedule to shut down these instances during off-peak hours and restart them before the workday begins. Implementing this single recommendation reduces their monthly cloud server bill by 25% without impacting application performance.
Accelerating Incident Response with Root Cause Analysis
A Site Reliability Engineer (SRE) receives an alert that a customer-facing API is experiencing high latency. Instead of manually sifting through logs and dashboards from dozens of microservices, they consult their AI Server Management tool. The tool has already correlated the latency spike with an abnormal increase in memory usage on a specific database server and a series of slow-running queries from a newly deployed service. It presents a clear causal chain, identifying the faulty queries as the root cause. This reduces the mean time to resolution (MTTR) from over an hour to just ten minutes.
Managing Distributed Edge Computing Fleets
A retail chain operates thousands of small server nodes in its stores for point-of-sale and inventory management. Manually monitoring this distributed fleet is impossible. They use an AI Server Management platform to centrally oversee the health and performance of all edge devices. The AI can detect patterns indicative of location-specific issues, such as network connectivity problems affecting a group of stores in one region. It can also automate patch management, rolling out security updates intelligently based on device workload to avoid disrupting store operations, ensuring the entire edge fleet remains secure and operational.